梯度增强算法(2)分类
用例子、数学和代码解释算法

在第一部分文章,我们详细学习了梯度增强回归算法。当我们v在那篇文章中,该算法足够灵活,可以处理任何损失函数,只要它是可微的。这意味着如果我们只是将用于回归的损失函数,特别是均方损失替换为处理分类问题的损失函数,我们就可以在不改变算法本身的情况下进行分类。尽管基本算法是一样的,但仍然有一些我们想知道的区别。在这篇文章中,我们将深入研究分类算法的所有细节。
算法及实例
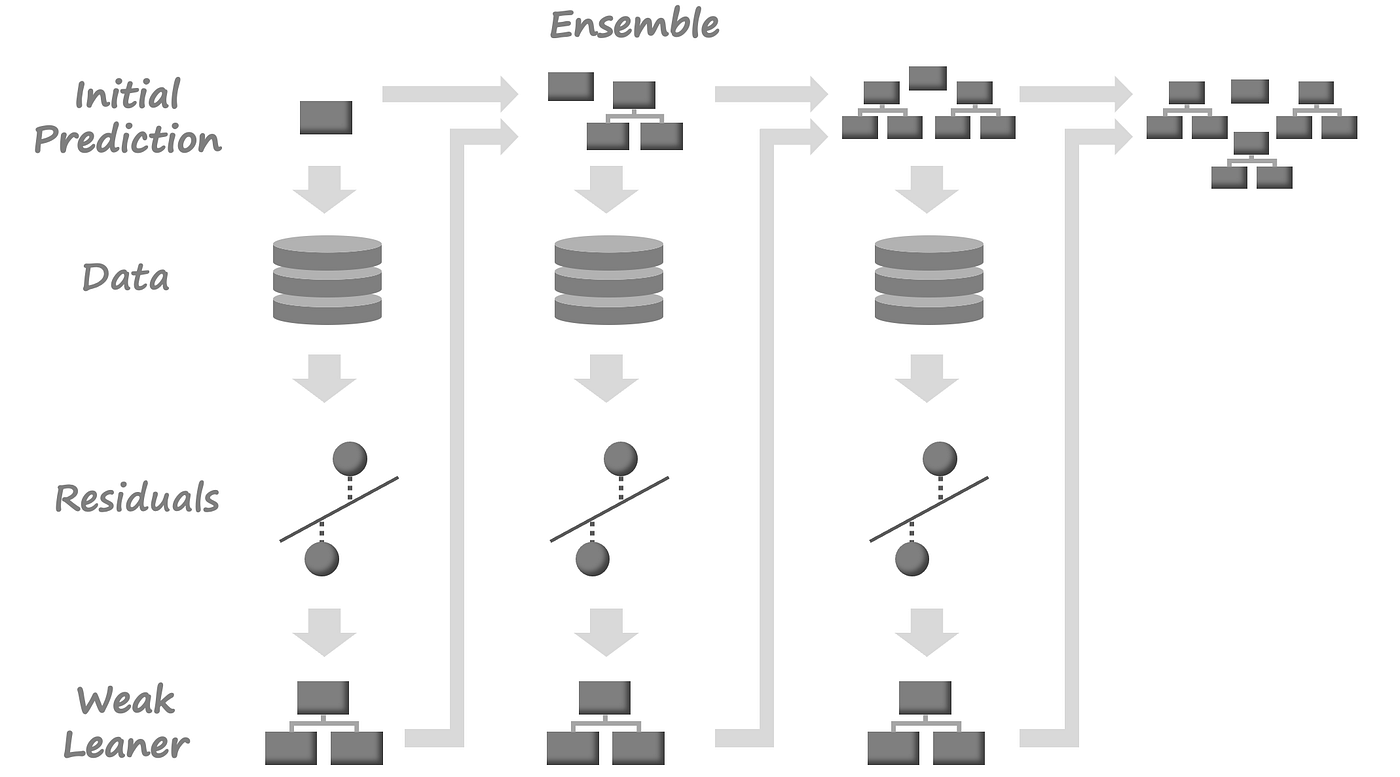
梯度增强是集成方法的一种变体,在集成方法中,您可以创建多个弱模型(它们通常是决策树),并将它们组合在一起以获得更好的整体性能。在本节中,我们将使用非常简单的示例数据构建一个梯度增强分类模型,以便直观地理解它是如何工作的。
下图显示了示例数据。它有二进制类y(0和1)和两个特征x₁而且x₂.

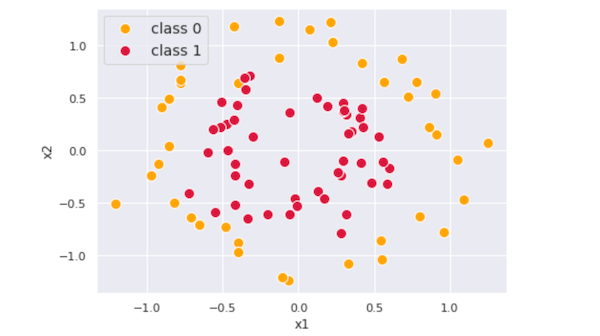
我们的目标是建立一个梯度增强模型,对这两个类别进行分类。第一步是对一类概率(我们称之为一类概率)进行统一预测p)显示所有数据点。最合理的均匀预测值可能是第一类的比例,它只是的平均值y.


这是数据和初始预测的3D表示。此时,预测值只是一个具有均匀值的平面P = mean(y)在y轴。

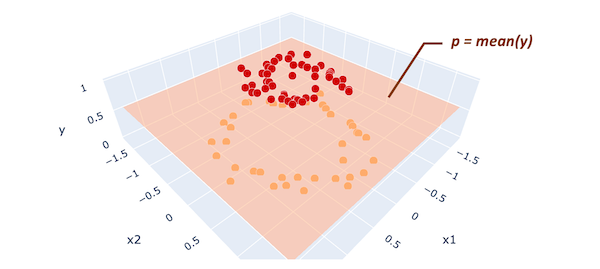
在我们的数据中,y是0.56。因为它大于0.5,所以所有的东西都按照这个初始预测被归为1类。有些人可能会觉得这个统一的值预测没有意义,但不用担心。随着我们加入更多的弱模型,我们将改进我们的预测。
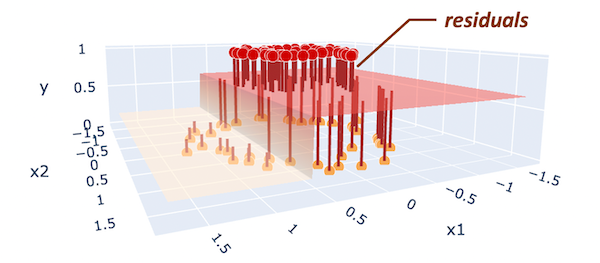
为了提高我们的预测质量,我们可能想要关注最初预测的残差(即预测误差),因为这是我们想要最小化的。残差被定义为Rᵢ= yᵢ−p(我表示每个数据点的索引)。在下面的图中,残差显示为棕色线,这些线是从每个数据点到预测平面的垂线。


为了最小化这些残差,我们正在建立一个两者都包含的回归树模型x₁而且x₂它的特征和残差r作为它的目标。如果我们能建立一个树,找到一些模式x而且r时,我们可以减少初始预测的残差p通过利用这些发现的模式。
为了简化演示,我们构建了非常简单的树,每棵树都只有一个分裂节点和两个终端节点,称为“残桩”。请注意,梯度提升树通常有更深一点的树,比如有8到32个终端节点的树。
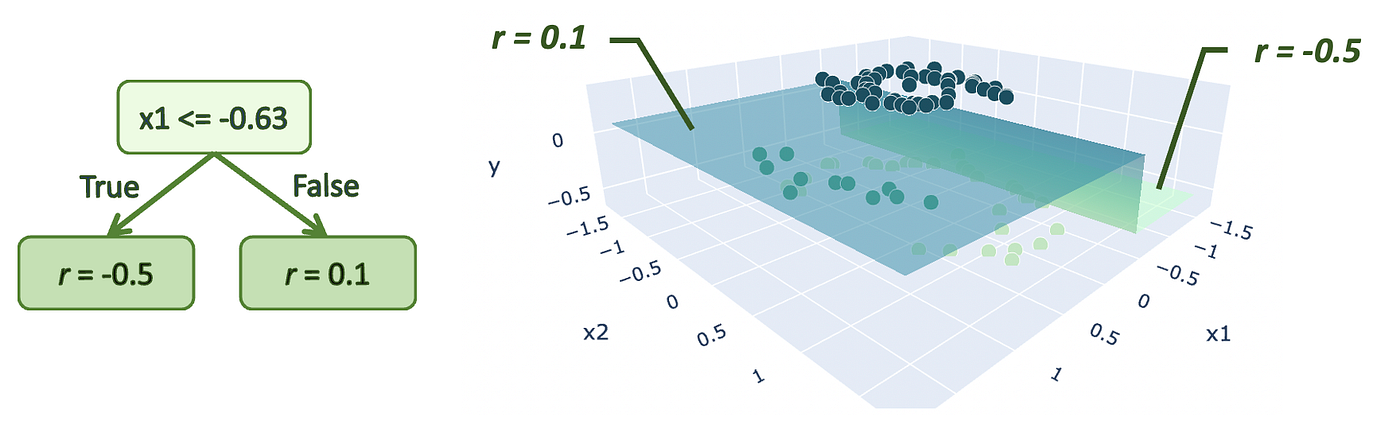
在这里,我们正在创建第一个树,预测两个不同值的残差R = {0.1, -0.6}.

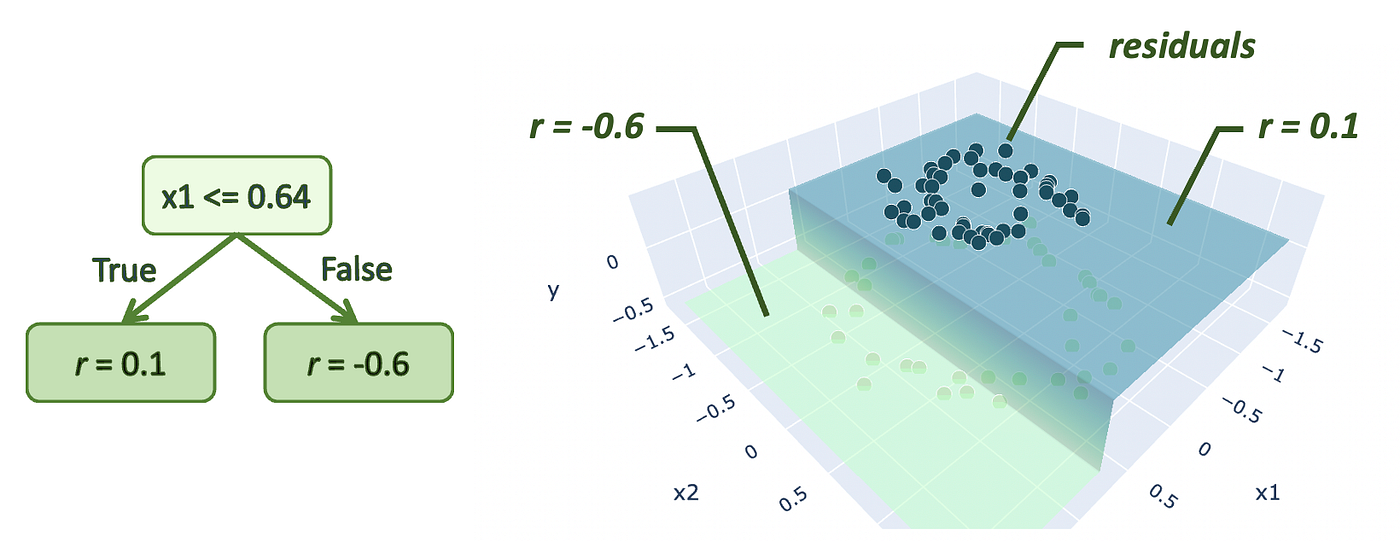
现在您可能认为我们想要将这些预测值添加到最初的预测中p减少残差,如果你已经读过了这篇文章讲的是回归算法,但在分类方面略有不同。值(我们称之为γ我们添加到初始预测中的Gamma)的计算公式如下所示:
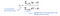
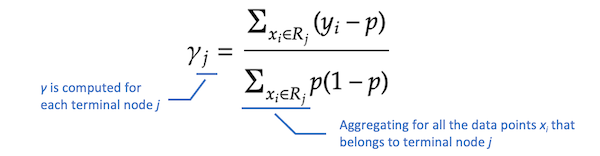
Σxᵢ∈Rⱼ意味着我们正在把这些值集中到sigma中Σ在所有样本上xᵢS属于终端节点Rⱼ.j表示每个终端节点的索引。你可能会注意到,分数的分子是终端节点残差的和j.我们将在下一节中通过所有的计算得到这个公式,但我们只是用它来计算γ现在。的计算值如下γ₁而且γ₂.

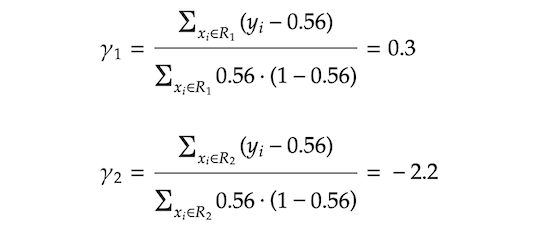
这γ不是简单地加到我们最初的预测中吗p.相反,我们正在转换p转换为log-odds(我们将此称为log-odds转换值F (x)),然后加上γ到它。对于那些不熟悉对数概率的人,它的定义如下。你可能在逻辑回归.


预测更新的另一个调整是γ按比例缩小学习速率ν,范围在0到1之间,然后将其添加到对数概率转换的预测中F (x).这有助于模型不过度拟合训练数据。


在这个例子中,我们使用了一个相对较大的学习率ν = 0.9为了使优化过程更容易理解,但它通常应该是更小的值,如0.1。
通过将上面方程右边的变量替换为实际值,我们得到了更新的预测F₁(x).


如果我们转换对数概率F (x)回到预测的概率p (x)(我们将在下一节中介绍如何转换它),它看起来像下面的楼梯状对象。


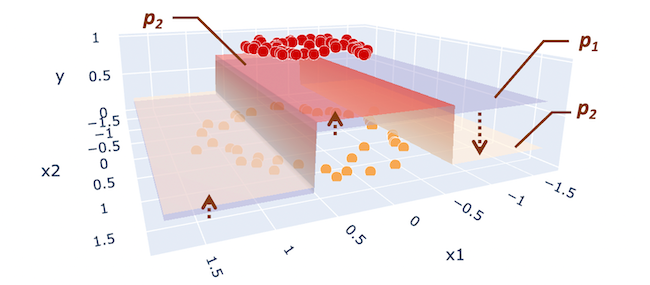
紫色的平面是最初的预测p₀而且更新为红色和黄色平面p₁.
现在是更新后的残差r看起来是这样的:

在下一步中,我们将再次使用相同的方法创建回归树x₁而且x₂作为特征和更新残差r作为它的目标。下面是创建的树:

我们用同样的公式来计算γ.计算γ连同最新的预测F₂(x)如下。


同样,如果我们转换对数概率F₂(x)回到预测的概率p₂(x),它看起来像下面的东西。

我们迭代这些步骤,直到模型预测停止改进。下图显示了从0到4次迭代的优化过程。


你可以看到合并后的预测p (x)(红色和黄色的飞机)正在接近我们的目标y当我们向组合模型中添加更多的树时.这就是梯度增强如何通过组合多个弱模型来预测复杂目标。
下图总结了算法的整个过程。

数学
在本节中,我们将通过查看其数学细节来学习一个更通用的算法。这里是整个算法的数学公式。


让我们逐行仔细看一看。
步骤1




yᵢ是我们的分类目标,它不是0就是1。p是第一类的预测概率。你可能会看到l根据目标类获取不同的值yᵢ.


作为−日志(x)的递减函数是x,预测越好(即增加p为yᵢ= 1),我们的损失就会越小。
argmin意味着我们在搜索值γ(γ),最大限度地减少ΣL (y)ᵢγ).假设更简单γ是预测概率p,我们假设γ是log-odds作为它使下面的计算更简单。对于那些忘记了我们在前一节中回顾的对数概率定义的人,它被定义为Log (odds) = Log (p/(1-p)).
能够解决argmin关于对数概率的问题,我们将损失函数转化为对数概率的函数。

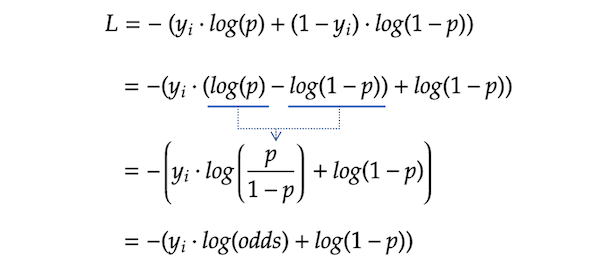
现在,我们可能想要替换p在上面的方程中用对数概率表示。通过转换前面显示的对数赔率表达式,p可以用log-odds表示:


然后,我们把这个值代入p在前面l方程和化简。

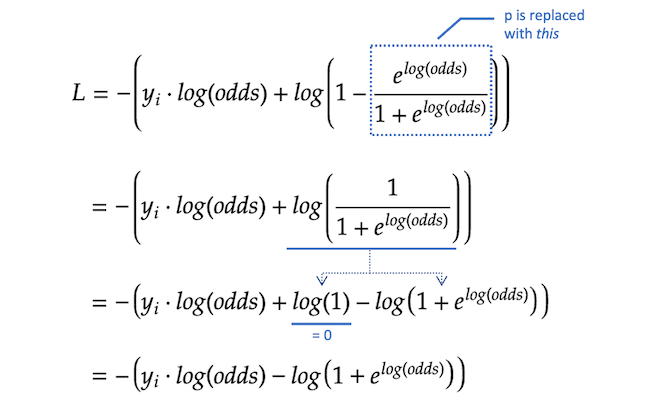
现在我们发现γ(请记住,我们假设它是对数赔率),最大限度地减少ΣL.我们对它求导ΣL关于对数概率。

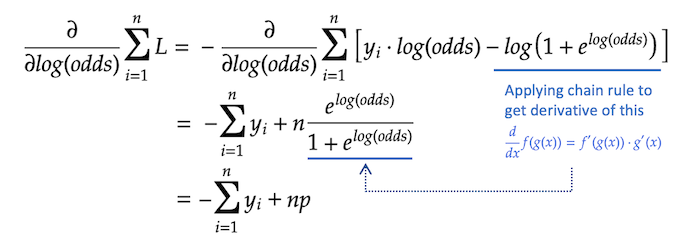
在上面的方程中,我们替换了包含log-odds with的分数p为了化简方程。接下来,我们开始设置∂ΣL /∂日志(优势)等于0,然后解p.


在这个二元分类问题中,y不是0就是1。的均值y实际上是第一类的比例。现在你可能明白为什么我们用P = mean(y)对于我们最初的预测。
作为γ是对数概率而不是概率吗p,我们将其转换为对数赔率。


步骤2

迭代从2-1到2-4的整个step2过程米次了。米表示我们正在创建的树的数量和小米表示每棵树的索引。
步骤2 - 1

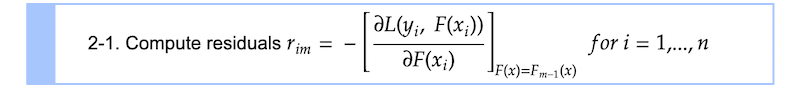
我们在计算残差rᵢ通过对之前的预测对损失函数求导F -₁然后乘以- 1。你可以在下标索引中看到,rᵢ计算每个单一样本我.你们中的一些人可能想知道我们为什么叫这个rᵢ剩余工资。这个值实际上是负梯度这就给出了损失函数可以最小化的方向(+/−)和大小。你很快就会明白为什么我们称它为剩余。顺便说一下,这种使用梯度来最小化模型损失的技术非常类似于gradient血统该技术通常用于优化神经网络。(事实上,它们彼此之间略有不同。如果您有兴趣,请看这篇文章详细说明这个话题。)
我们来计算残差。F -₁式中表示上一步的预测结果。在第一次迭代中,确实如此F₀.和上一步一样,我们要求导l而不是我们预测的p的对数概率Flog-odds。下面我们使用l用对数概率表示这是我们在上一步中得到的。

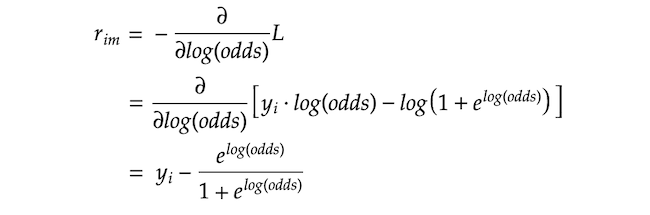
在上一步中,我们还得到了这个方程:

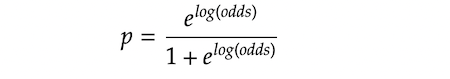
我们可以把第二项代入rᵢ方程p.

你现在知道我们为什么打电话了吧r剩余工资。这也给了我们有趣的见解,负梯度为我们提供了损失最小化的方向和幅度,实际上只是残差。
步骤2 - 2


j表示树中的一个终端节点(即leave),米表示树索引和大写字母J表示叶节点的总数。
步骤2 - 3

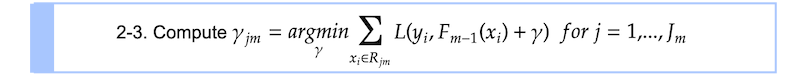
我们正在寻找γⱼ使每个终端节点上的损失函数最小化j.Σxᵢ∈RⱼL意味着我们要把所有的损失xᵢS属于终端节点Rⱼ.我们把损失函数代入方程。


解这个方程γⱼ会非常困难。为了使它更容易解,我们做了近似l用二阶泰勒多项式.泰勒多项式是一种将任何函数近似为具有无限或有限项数的多项式的方法。虽然我们在这里不研究它的细节,但你可以看看本教程如果你感兴趣的话,这很好地解释了这个想法。
这是l使用二阶泰勒多项式:


我们用这个近似代替l在方程中γⱼ,然后求的值γⱼ这使得Σ(*)的导数等于零。


我们已经计算过了∂L /∂F在上一步中如下所示:


我们把这个代入∂L /∂F在γ方程。


最后,我们得到了这个简化的方程γⱼ我们在前一节中使用过。
步骤2 - 4

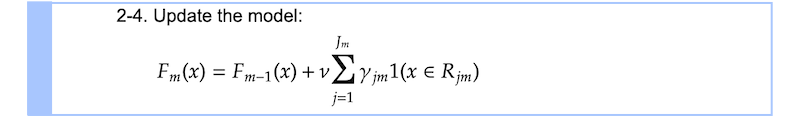
在最后一步中,我们更新组合模型的预测F.γⱼ1(x∈Rⱼ)意思是我们选择一个值γⱼ米如果给定x落在终端节点上Rⱼ.由于所有终端节点都是排他性的,任何给定的单个x落入只与单个终端节点相对应的γⱼ添加到之前的预测中F -₁然后做出更新的预测F.
如前一节所述,ν学习率是否在0和1之间,这控制了额外树预测的贡献程度γ到综合预测F.较小的学习率降低了额外树预测的效果,但它基本上也降低了模型过拟合训练数据的机会。
现在我们已经完成了所有的步骤。为了获得最佳的模型性能,我们希望迭代第2步米乘以,就是相加米到组合模型的树。在现实中,您可能经常想要添加超过100棵树来获得最佳的模型性能。
如果你读过我的文章为一个回归算法,您可能会觉得分类算法的数学计算比回归复杂得多。而argmin对数损失函数的导数计算是复杂的,本节开头展示的重点数学算法是完全相同的。这就是梯度增强算法的精妙之处在于它对任何损失函数都适用只要它是可微的。事实上,流行的梯度增强实现,如XGBoost或LightGBM具有各种各样的损失函数,因此您可以选择适合您的问题的任何损失函数(参见中提供的各种损失函数XGBoost或LightGBM).
代码
在本节中,我们将把刚才回顾的数学运算转换成可行的python代码,以帮助我们进一步理解算法。我们正在使用DecisionTreeRegressor从scikit-learn构建树,这有助于我们只关注梯度增强算法本身,而不是树算法。我们正在模仿scikit-learn风格的实现,您可以在其中训练模型适合方法并进行预测预测方法。
请注意,所有训练过的树都存储在self.trees列表对象,它在我们进行预测时被检索predict_proba方法。
接下来,我们要检查我们的CustomGradientBoostingClassifier性能与GradientBoostingClassifier通过scikit-learn查看他们在我们数据上的日志损失。


正如您在上面的输出中所看到的,两个模型具有完全相同的log-loss。
推荐资源
在这篇博文中,我们回顾了梯度增强分类算法的所有细节。如果您对回归算法也感兴趣,请参阅第1部分的文章。
如果你想了解算法的更多细节,还有其他一些很好的资源:
- StatQuest, Gradient BoostPart3而且第4部分
这些是YouTube上的视频,以初学者友好的方式用出色的视觉效果解释了梯度增强分类算法。 - 特伦斯·帕尔和杰里米·霍华德,如何解释梯度增强
虽然本文侧重于梯度增强回归而不是分类,但它很好地解释了算法的每个细节。 - 杰罗姆•弗里德曼贪心函数逼近:一个梯度提升机
这是弗里德曼的原始论文。虽然这有点难以理解,但它确实显示了算法的灵活性,他展示了一个广义算法,可以处理任何类型的具有可微损失函数的问题。
您还可以在谷歌Colab链接或下面的Github链接中查看完整的Python代码。
参考文献
- 杰罗姆•弗里德曼贪心函数逼近:一个梯度提升机
- 特伦斯·帕尔和杰里米·霍华德,如何解释梯度增强
- 马特•鲍尔斯如何从零开始建立一个梯度增强机
- 维基百科,梯度增加