工程数据
万能工具箱概述
开始使用通用数据工具包,这是一个使数据工程师工作更高效的框架
数据工程师的工作需要多种技能,包括构建数据管道、评估数据库、设计模式和管理它们。简而言之,数据工程师加载、提取、操作和一般管理数据.通常,这项工作需要很多技能,如果这个过程不是自动化的,数据工程师在解决意外事件时可能会犯很多错误并浪费大量时间。
最近,我测试了一个非常有趣的框架,它有助于数据工程师的职责:多功能数据套件,由VMware作为Github上的开源。
通用数据工具包允许数据工程师半自动地执行其任务。在实践中,他们只需要关注数据和框架的一般配置,比如数据库设置和cron任务调度,而不用担心手动部署、版本控制和类似的事情。
换句话说,万能数据工具包简化了数据工程师的生活,因为它允许以简单和快速的方式管理数据,以及快速处理意外事件。
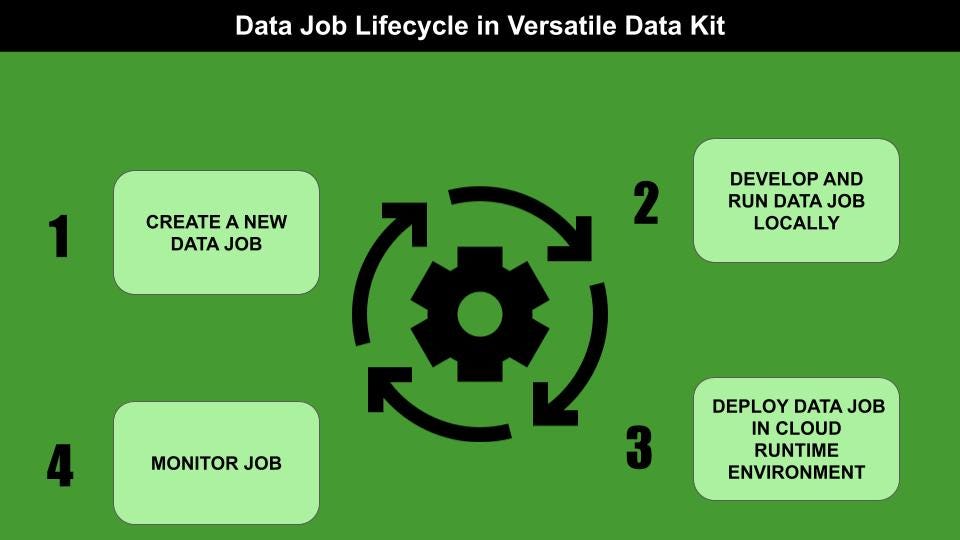
数据工程师可建立完整的数据处理工作负载(数据工作,在通用数据工具包语言中),只需三步:
- 摄取数据
- 处理数据
- 发布的数据
在本文中,我概述了通用数据工具包,以及一个实际用例,展示了它的潜力。有关更多信息,请阅读通用的数据工具包完整的文档.
1概述
通用数据工具包是一个框架,它使数据工程师能够开发、部署、运行和管理数据作业。数据作业是数据处理工作负载。
万能数据套件由两个主要组件组成:
- 一个SDK的数据,它提供了数据提取、转换和加载的所有工具,以及一个插件框架,可以根据数据应用的特定要求对框架进行扩展。
- 一个控制服务,允许创建、部署、管理和执行数据作业Kubernetes运行时环境t。
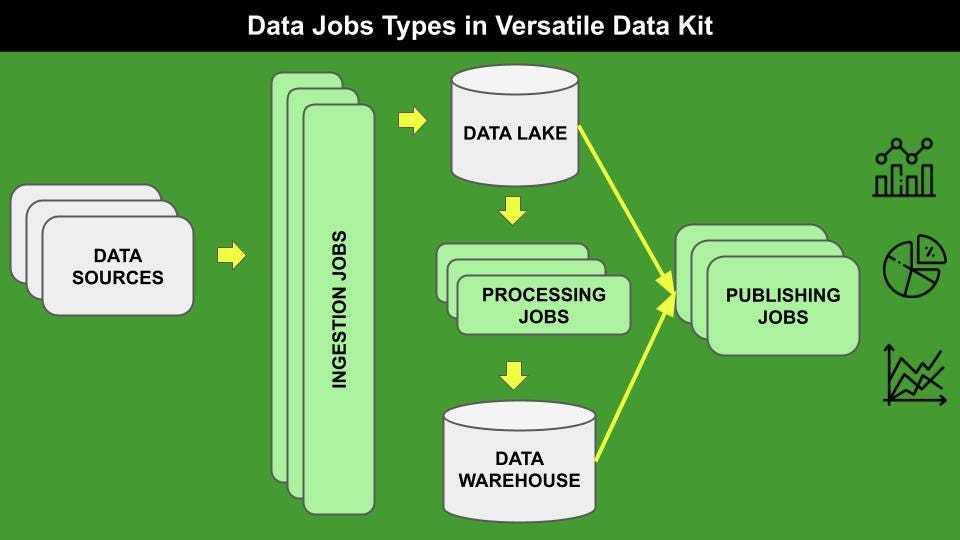
万能数据工具包管理三种类型的数据作业,如下图浅绿色所示:
1.1摄食作业
摄入工作包括将不同来源的数据推送到数据湖,数据湖是原始数据的基本容器.数据可以以不同的格式提供,如CSV、JSON、SQL等。
摄取可以通过不同的步骤定义,包括但不限于创建数据模式和将数据加载到表中的过程。所有这些步骤都可以指定编写数据作业(通常在Python或SQL中)或通过插件.通用数据工具包提供了一些预先打包的插件,例如CSV和SQL摄取,但您可以实现自己的插件。
1.2处理作业
处理作业允许从数据湖中包含的数据集创建精选数据集。通常,这些工作涉及数据操作,例如数据清理和数据聚合。生成的数据集存储在数据仓库中,数据仓库在概念上与数据湖不同,但在物理上可能与数据湖相同。由于它们的高可配置性,Processing job也可以与高级分析用例相关。
通常处理作业是用SQL编写的,但Python也可以用来实现这类作业。
1.3发布工作
发布作业包括特别的查询或视图,可以用于不同的目的,例如使用标准的商业智能工具构建交互式仪表板,向其他应用程序发送通知或警报等等。
发布作业依赖于特定的数据集,因此目前它们还没有包含在当前版本的通用数据工具包中。
2使用实例
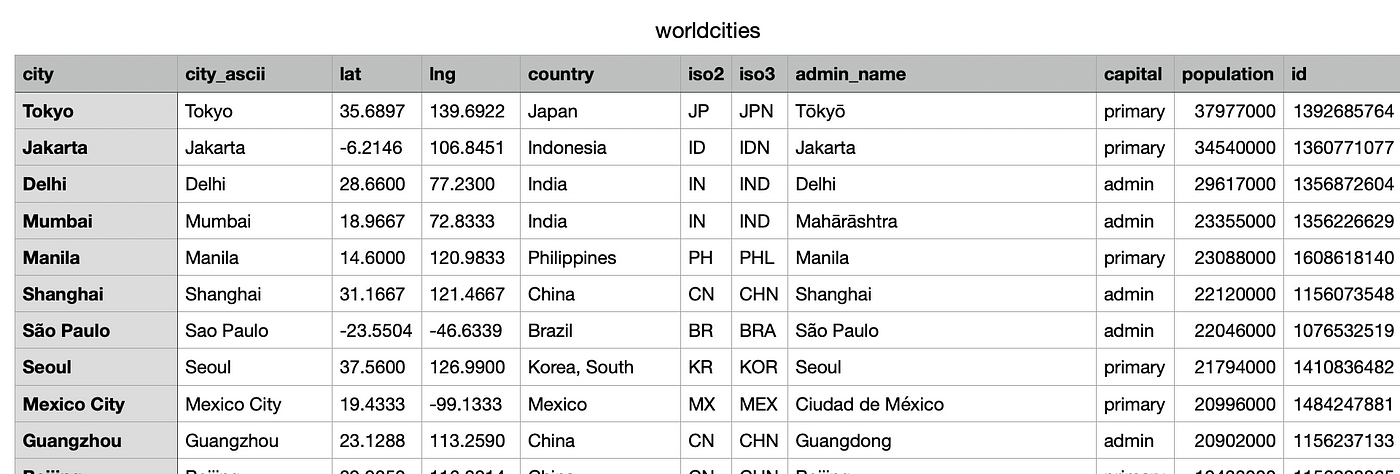
例如,我将开发一个本地数据湖,在其中摄取包含基本版本的CSV文件世界城市数据库,包含约41k个名额:
我将遵循以下步骤:
- 万能数据套件安装
- 数据创建Job
- 摄入的工作
- 处理工作
2.1通用的toolkit安装
多功能数据工具包可以轻松安装通过皮普如下:
pip install -U pip setuptools车轮
PIP安装quickstart-vdk
由于我在本地部署了所有的数据作业,所以不需要安装控制服务。但是,如果您想在Kubernetes运行时环境中部署数据作业,可以按照下面的步骤进行本指南.
2.2创建数据任务
安装完成后,我就可以使用vdk命令与通用数据工具包交互。可以通过以下命令创建一个新的Data Job:
VDK create -n world-cities-vdk -t my-team
在哪里- n指定数据作业名称和- t球队名称。有关每一个的详细信息vdk命令时,可以执行如下命令:
VDK [command-name]——help
例如:
VDK创建—帮助
作为结果创建命令,vdk创建一个新目录,其中包含一些示例文件,每个文件对应于数据作业的一个步骤。
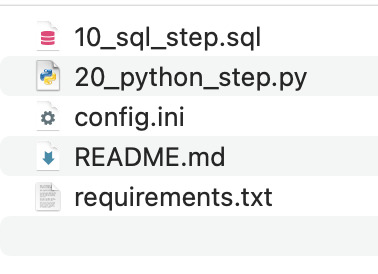
步骤是按字母顺序执行的,因此,出于可读性考虑,它们可以从1开始编号。有关Data Job目录结构的更多详细信息,请参阅官方文档.
2.3环境设置
在开始使用通用数据工具包之前,需要进行初步配置。这可以通过配置两个文件来实现:
让-这个文件包含项目中使用的库的列表,每行一个;config.ini-该文件允许配置一些基本信息,如团队名称和运行任务的cron。
现在,我可以配置一些环境变量,包括数据库类型(在我的例子中是sqlite)和名称(vdk-cities.db对我来说)。我可以直接从我的终端配置这些变量:
出口VDK_DB_DEFAULT_TYPE = SQLITE
出口VDK_INGEST_METHOD_DEFAULT = sqlite
出口VDK_INGEST_TARGET_DEFAULT = vdk-cities.db
出口VDK_SQLITE_FILE = vdk-cities.db
的vdk-cities.db文件就是我的数据湖。
2.4摄食工作
我已经准备好从我的数据湖中摄取数据了。首先,我下载数据集我把它放到一个叫源,位于Data Job父目录中。
其思想是将数据集摄取到名为城市.这可以通过两种方式实现:
- 编写数据作业
- 使用
vdk-csv插件。
2.4.1写入数据作业
我定义了一个初始Data Job步骤,该步骤将删除表城市,如果它存在,以确保总是有一个新版本的表:
删除表,如果存在城市;
我将此步骤保存在Data Job目录中为10 _drop_cities_table.sql.的10在名称的开头将确保该步骤将首先执行。
现在我定义了第二个Data Job步骤,它定义了将导入数据集的表模式。数据作业步骤对应于以下简单的SQL代码:
创建表城市(城市NVARCHAR,
city_ascii NVARCHAR,
lat真实,
液化天然气的真实的,
国家NVARCHAR,
iso2 NVARCHAR,
iso3 NVARCHAR,
admin_name NVARCHAR,
资本NVARCHAR
人口的整数,
id的整数
);
我将此步骤保存为20 _create_cities_table.sql.
最后,我可以上传数据集城市表格我可以编写下面的Python脚本,它将数据集加载为Pandas数据框架,将其转换为字典,然后将字典的每一项通过job_input.send_object_for_ingestion ()功能,由万能数据工具箱提供:
导入日志
从vdk.api。job_input导入IJobInput
进口熊猫作为pdlog = logging.getLogger(__name__)(job_input: IJobInput)
log.info(f"开始作业步骤{__name__}")
Df = pd.read_csv('source/worldcities.csv')Df_dict = df.to_dict(orient='records')
对于range(0, len(df_dict))中的行:
job_input.send_object_for_ingestion (
有效载荷= df_dict(行),destination_table =“城市”)
注意run ()函数,以使Python脚本被识别为数据作业Python步骤。
现在我已经准备好运行数据作业步骤了。我移动到Data Job父目录并运行以下命令:
VDK运行world-cities-vdk
数据库vdk-cities.db在当前目录中创建并使用城市表格我可以查询数据库或通过vdk查询命令或通过传统sqlite命令:
vdk sqlite-query -q 'SELECT * FROM cities'
2.4.2使用vdk-csv插件
将数据集加载到数据湖的另一种方法是使用插件。在我的例子中,我将使用vdk-csv插件。我可以很容易地安装它皮普:
PIP安装quickstart-vdk vdk-csv
然后我可以通过以下命令摄取数据集:
VDK ingest-csv -f source/worldcities.csv -t cities
2.5处理作业
的视图,作为Processing Job创建城市这个表格只包含了位于美国的城市。为了做到这一点,我定义了两个Processing job:
- 如果视图存在,则删除该视图
- 创建视图并将其保存在默认的Data Lake中。
首先,我编写一个进一步的数据作业步骤,命名为40 _drop_usa_cities_view.sql:
DROP VIEW如果存在usa_cities;
然后我创建另一个Data Job步骤,创建视图:
创建视图usa_cities
作为
SELECT *
从城市
WHERE country = 'United States';
我再次运行所有的数据作业:
VDK运行world-cities-vdk
视图被添加到数据湖中。
总结
在本文中,我概述了通用数据工具包,这是一个非常强大的框架,可以有效地管理数据。
此外,我还用数据作业摄取和处理举例说明了该框架的一个初始用例。更多细节,你可以阅读万能数据工具包用户指南.
本教程的完整代码可以从我的Github存储库下载。
如对万能数据套件有疑问或疑问,可直接加入他们的公共空闲工作区或他们的邮件列表或在Twitter上关注他们.
如果你已经读到这里,对我来说今天已经很多了。谢谢!你可以在这篇文章.
你愿意支持我的研究吗?
你可以每月订阅几美元,解锁无限的文章点击这里.
相关文章
免责声明:这不是一篇赞助文章。我与万能数据工具包或它的作者没有任何关系。本文对工具包进行了公正的概述,旨在使更多人能够使用数据科学工具。





