如何建立面板数据集的OLS回归模型
并使用Python和statmodels对其拟合优度进行了详细分析
在这篇文章中,我们将了解面板数据集,我们将学习如何建立和训练一个合并OLS回归模型使用statmodels和Python获取真实世界的面板数据集。
训练Pooled OLSR模型后,我们将学习如何使用调整后的r平方、对数似然、AIC和回归的f检验来分析训练模型的拟合优度。我们将通过对剩余误差的详细分析,更深入地研究模型的拟合优度。
伴随着Fixed的影响,随机效应,以及随机系数模型,合并OLS回归模型恰好是面板数据集的一个常用模型。事实上,在许多面板数据集中,Pooled OLSR模型经常被用作比较其他模型性能的参考或基线模型。
什么是面板数据?
面板数据集包含在一段时间内为一个或多个唯一可识别的个人或“事物”收集的数据。在面板数据术语中,为其收集数据的每个个体或“事物”称为一个单位.
以下是面板数据集的三个真实例子:
弗雷明汉心脏研究字体弗雷明汉心脏研究是一项长期实验,于1948年在马萨诸塞州的弗雷明汉市开始。每年收集5000多人的健康数据,目的是确定心血管疾病的危险因素。在这个数据集中,单位是一个人。
格伦菲尔德投资数据:这是一个流行的研究数据集,包含了10家美国公司20年的业绩数据。在这个数据集中,单位是一家公司。
英国家庭小组调查这是对英国家庭的抽样调查。自1991年以来,每个抽样家庭的成员都被问及一系列问题,并记录下他们的回答。接下来的每一年,同样的家庭样本都会被再次采访。这项调查的目的是分析英国发生的社会经济变化对英国家庭的影响。在这个数据集中,单位是一个家庭。
在构建面板数据集时,研究人员测量一个或多个称为变量为每一个单位并以表格形式记录它们的值。变量的例子包括个人的性别、种族、体重和血脂水平或员工数量、公司的流通股和EBITDA。请注意,有些变量可能会随着时间的推移而变化,而其他变量则保持不变。
这个数据收集练习的结果是一个三维数据集其中,每行代表一个唯一的单元,每列包含来自该单元的一个测量变量的数据,z轴包含跟踪该单元的时间周期序列。
面板数据集产生于纵向研究其中,研究人员希望研究测量变量对一个或多个的影响响应变量比如一个公司每年的投资,或者一个国家的GDP增长。
一个真实世界的面板数据集
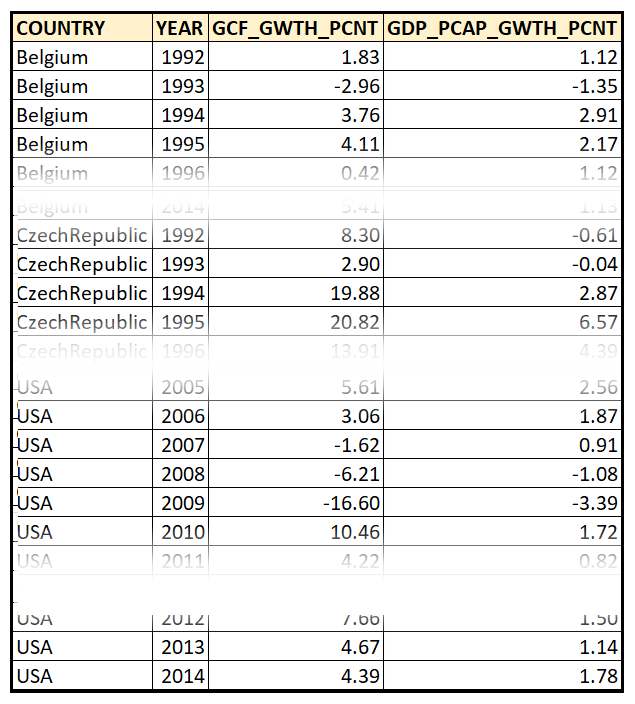
下面的面板数据集包含了七个国家从1992年到2014年的人均GDP同比增长率。除了GDP增长数据,面板还包含了每个国家的总资本形成年率%的增长:

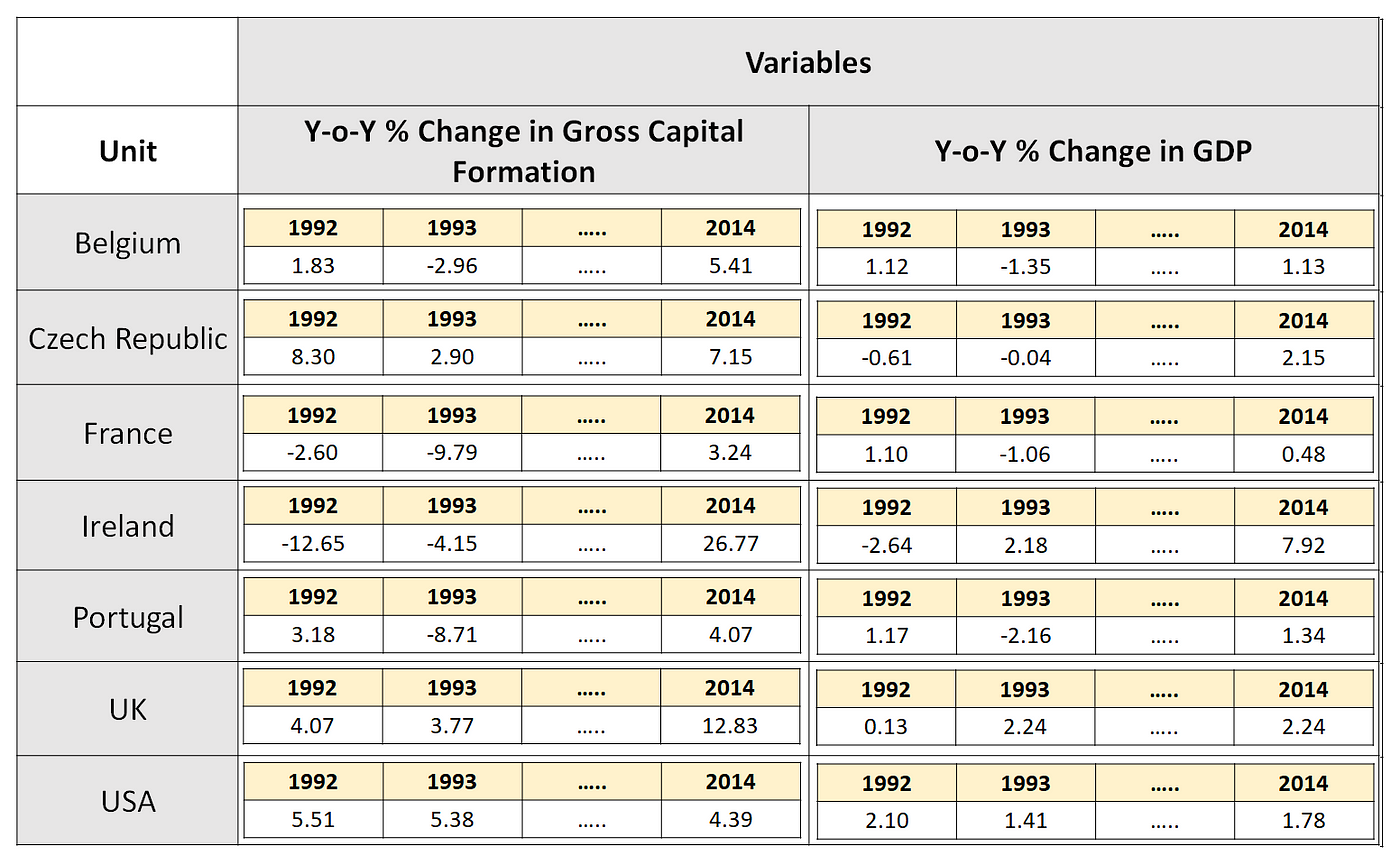
在上面的数据集中,每个国家(“单位”)在相同数量的时间段内被跟踪,从而产生所谓的a平衡板.一个面板不平衡或不平衡是指在不同的时间段内跟踪不同的单位。
上面的数据集也是一个例子固定面板(相对于旋转面板)因为我们在每个时间段追踪的都是同一组国家。
在本文的其余部分中,我们将研究这些数据面板固定而且平衡.
在面板数据集中,属于一个单元的数据点集称为集团.在讨论面板数据集时,通常会互换使用“单位”和“组”这两个词。
回到世界银行的数据集,假设我们希望研究总资本形成增长与一国GDP增长之间的关系。为此,我们形成以下回归目标:
回归的目标
我们的目标是精确地定义一个国家的总资本构成增长与该国经历的年度GDP增长之间的关系。
回归策略
我们的策略将是选择并拟合一个适合面板数据集的回归模型,特别是WB面板数据。我们的回归模型应该允许我们表达每年的GDP增长经历的国家我时间(年)t,作为某个函数f()。国家资本形成总额的年增长率我在那段时间内t.
用符号表示:

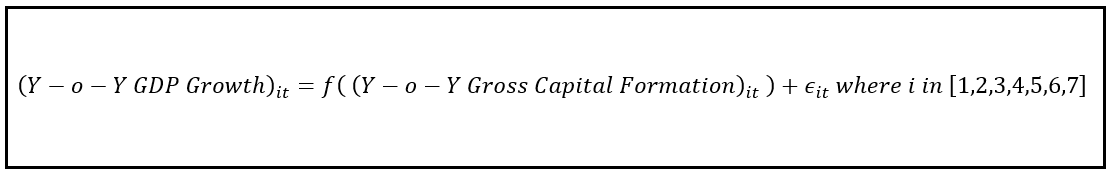
在上述回归方程中,ε_it是回归的残差,它捕捉了国家Y-o-Y增长的方差我在一年t这个模型不是能够“解释”。
Pooled OLS回归模型
如前所述,Pooled OLS回归模型通常是一个很好的起点,也是几个面板数据集的参考模型。我们将研究它对世界银行数据集的适用性。
为此,我们将通过将国家和年份视为两列来“平化”面板数据,使其看起来像这样:

我们的因变量(内生变量)和解释变量(外生变量)如下:
因变量y= GDP_PCAP_GWTH_PCNT
解释变量X= GCF_GWTH_PCNT
该数据集可供下载在这里.
使用熊猫,我们将这个扁平的面板数据集加载到内存中,并使用Seaborn,我们会密谋密谋y与X。
我们将从导入所有必需的包开始,包括我们将在本文后面使用的包:
进口熊猫作为pd
进口scipy.stats作为圣
进口statsmodels.api作为sm
进口statsmodels.graphics.tsaplots作为的东西
从statsmodels.compat进口lzip
从statsmodels.stats.diagnostic进口het_white
从matplotlib进口pyplot作为plt
进口seaborn作为sns
将扁平化数据集加载到Pandas数据帧中:
Df_panel = pd。read_csv(' wb_data_panel_2ind_7units_1992_2014.csv ',头= 0)
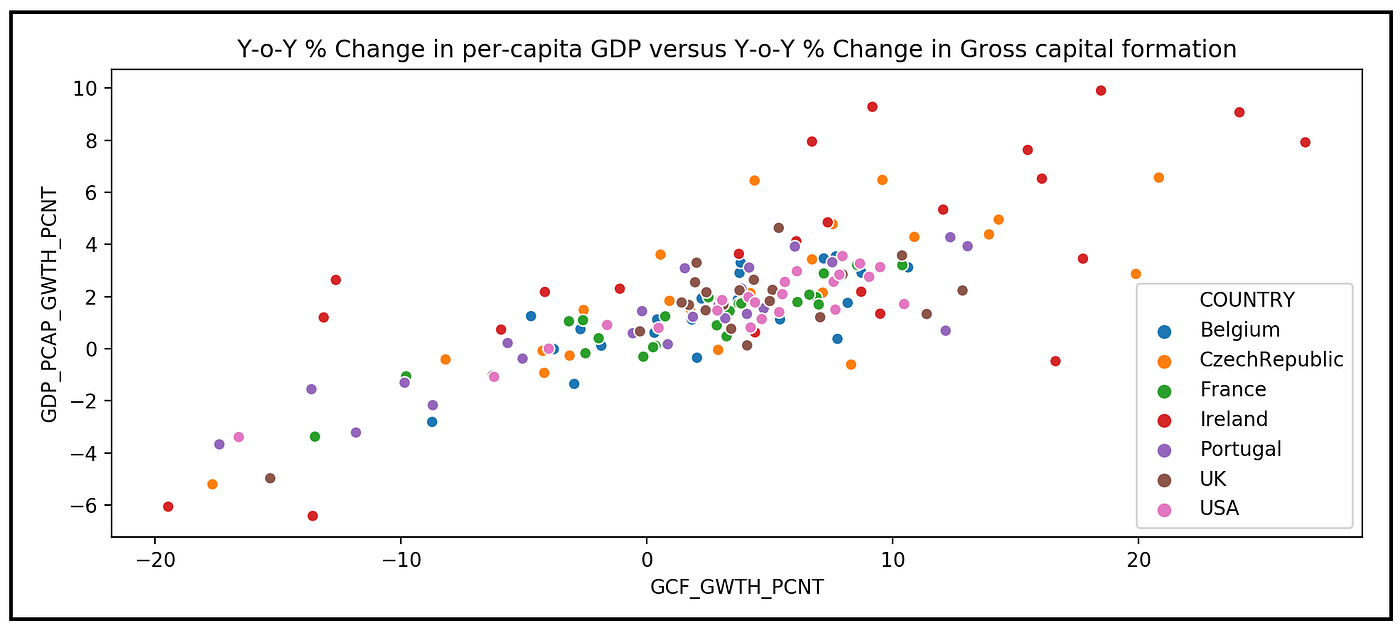
使用Seaborn绘制所有时期和所有国家的GDP增长与总资本形成增长的关系:
sns。散点图(x= df_panel [“GCF_GWTH_PCNT”],
y= df_panel [“GDP_PCAP_GWTH_PCNT”],
色调= df_panel [“国家”])。集(标题=
“人均GDP年率变化百分比与总资本形成年率变化百分比”)plt。显示()
我们可以看到下面的情节:

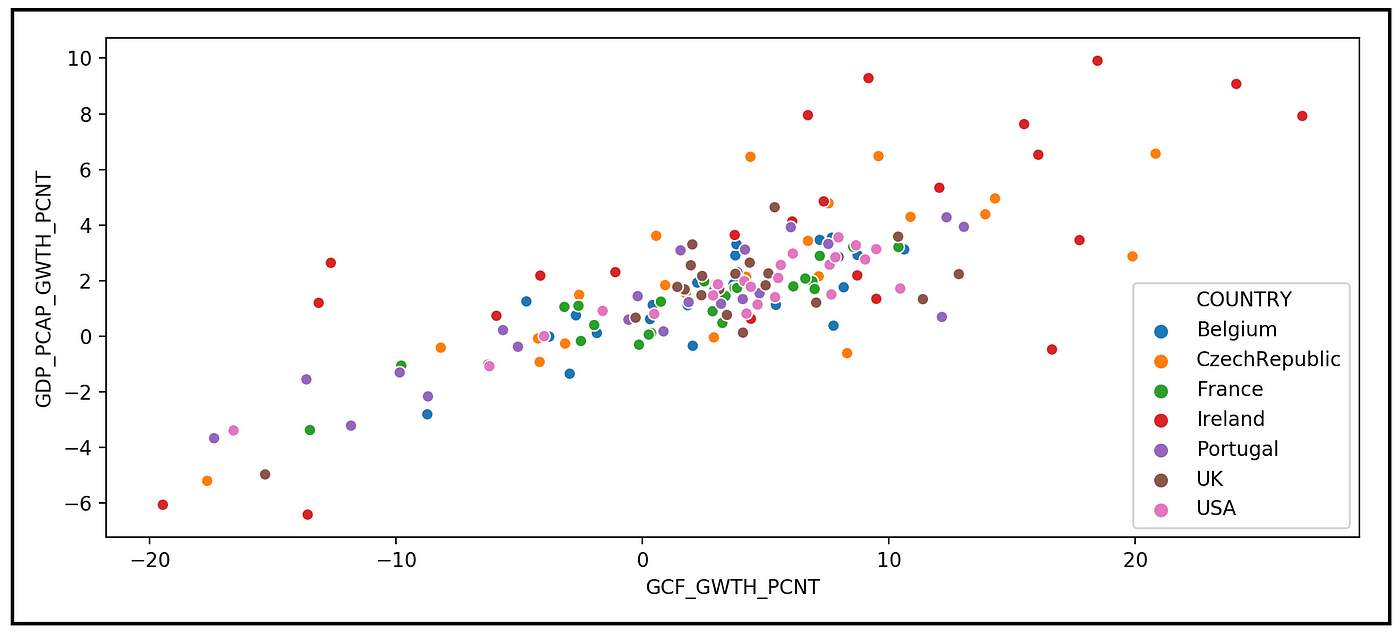
在数据面板中所有国家的GDP年增长率与资本形成总额年增长率之间似乎存在线性关系。这对于用OLS技术拟合线性模型是个好兆头。
然而,我们也观察到的迹象异方差性在响应变量GDP_PCAP_GWTH_PCNT。具体来说,对于GCF_GWTH_PCNT的不同值,GDP_PCAP_GWTH_PCNT中的方差不是常数。这对于使用OLS估计技术来说不是一个好兆头。
无论如何,让我们继续为这个扁平的数据面板拟合OLS回归模型。在本文的后面部分,我们将看到如何使用一系列拟合优度测试来衡量模型的适用性。
Pooled OLS的回归模型方程如下:

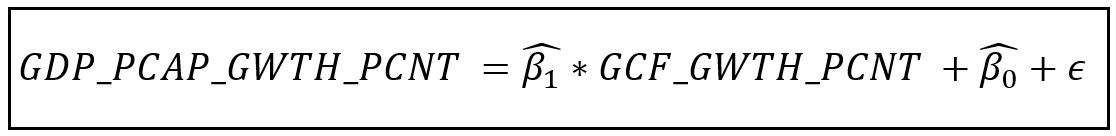
在面板数据集上训练模型的目的是找到拟合系数β_cap_1而且β_cap_0.“帽子”在里面β_cap表示它是模型估计的系数值,而不是真实的(总体水平)值β这总是未知的。
ε是拟合模型的残差,是具有一定均值和方差的随机变量。如果OLS估计技术正确地完成了它的工作,ε的平均值将为零,ε将有一个常数方差,条件是GCF_GWTH_PCNT(即。ε不会是异性恋),和ε不会是自相关的。
我们将使用statmodels的OLS类建立并拟合OLS回归模型,如下所示:
定义y而且X变量:
y_var_name =“GDP_PCAP_GWTH_PCNT”
X_var_names = [“GCF_GWTH_PCNT”]
开拓市场y数据面板中的向量:
pooled_y = df_panel [y_var_name]
开拓市场X来自数据面板的矩阵:
pooled_X = df_panel [X_var_names]
为回归拦截添加占位符。当模型拟合时,该变量的系数为回归模型的截距β_0.
pooled_X = sm。add_constant(pooled_X)
建立OLS回归模型:
Pooled_olsr_model = sm。OLS(endog= pooled_y,exog= pooled_X)
训练模型(y,X)数据集,获取训练结果:
Pooled_olsr_model_results = pooled_olsr_model。适合()
打印培训总结:
打印(pooled_olsr_model_results。总结())
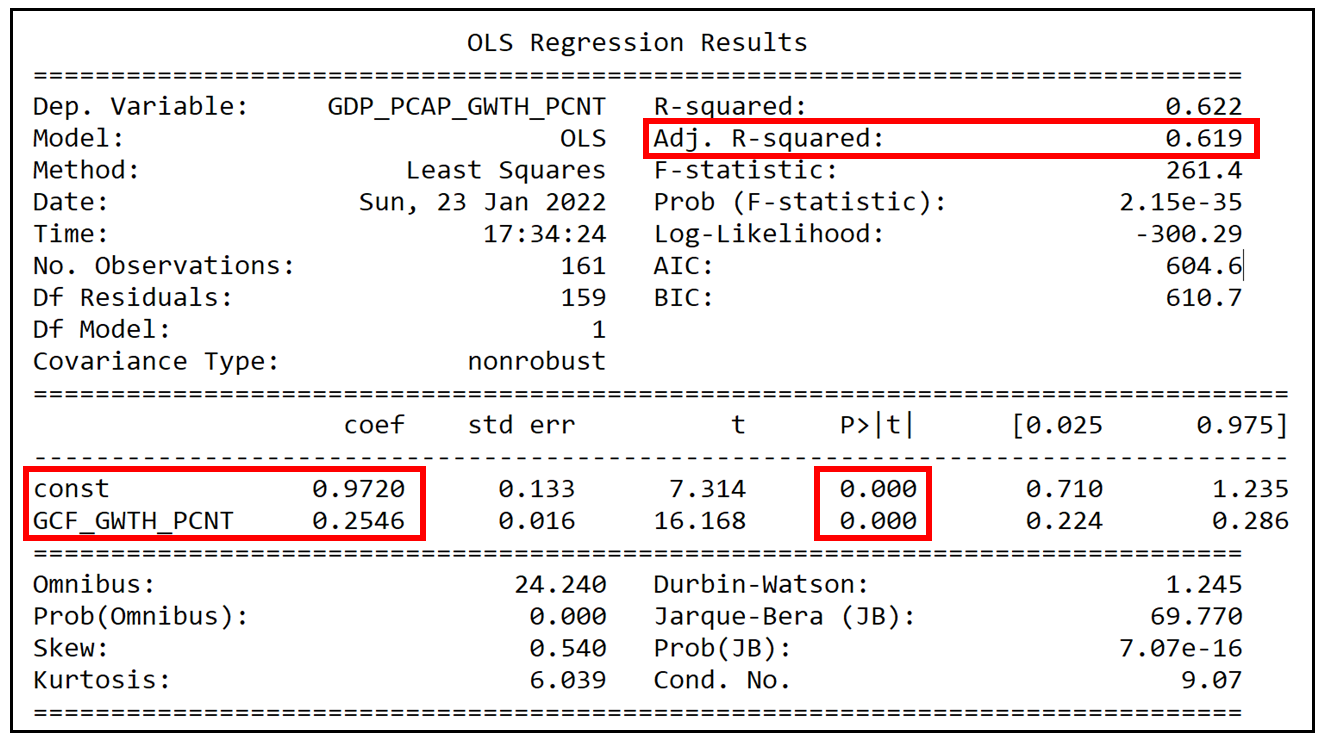
我们得到如下输出:

如何解释Pooled OLSR模型的训练输出
首先需要注意的是拟合系数的值:β_cap_1而且β_cap_0
β_cap_0 = 0.9720, β_cap_1=0.2546
估计这两个系数在p < .001时显著不同于0。这是个好消息。
经过训练的Pooled OLS模型方程如下:

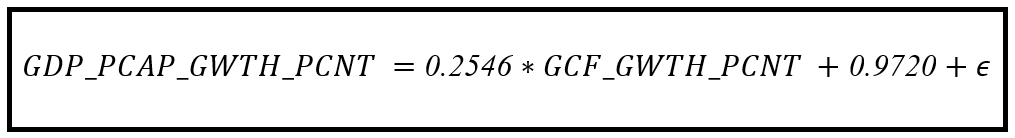
如何解释Pooled OLSR模型的性能
我们将分析Pooled OLS模型是否适合我们的回归问题。我们将使用直接测量和测试来分析模型的拟合优度,例如平方和野生,对数似然和另类投资会议分数,也间接通过残差分析。
通过r平方、f检验、对数似然和AIC分析拟合优度
的调整后的平方的总方差占比是多少y这是由X在考虑了由于包含回归变量而损失的自由度后是0.619或62%这当然不是一个糟糕的数字,但仍然没有什么值得兴奋的。
的回归f检验测量模型参数的共同显著性产生了261.4的检验统计量,p值为2.15e-35,从而使我们得出结论,模型的系数估计在p < .001时共同显著。
模型的log -似然值为-300.29另类投资会议得分604.6。这些拟合优度值本身是没有意义的,除非我们将它们与竞争模型的优度值进行比较。在我下周的文章中,我们将在相同的数据面板上使用固定效应模型,并使用这两种方法比较FE模型与Pooled OLSR模型的拟合质量。
残差分析
我们来分析一下剩余的错误的拟合模型正常,异方差性而且相关-影响线性模型拟合优度的三个属性。
回忆那每一个原始的残差ε_it = y_obs_it - y_pred_it即GDP_PCAP_GWTH_PCNT的观测值与预测值之差。让我们打印熊猫系列对象,包含训练模型的原始残差:
打印(pooled_olsr_model_results.resid)

残差均值为:
打印('残差均值='+str(pooled_olsr_model_results.resid。的意思是()))
残差均值=3.682354628259836 e-16
均值几乎为零,这是使用OLS估计技术的预期结果。
残差是否正态分布?
让我们绘制剩余误差的Q-Q图:
sm。qqplot(数据= pooled_olsr_model_results。渣油,行='45')plt。显示()

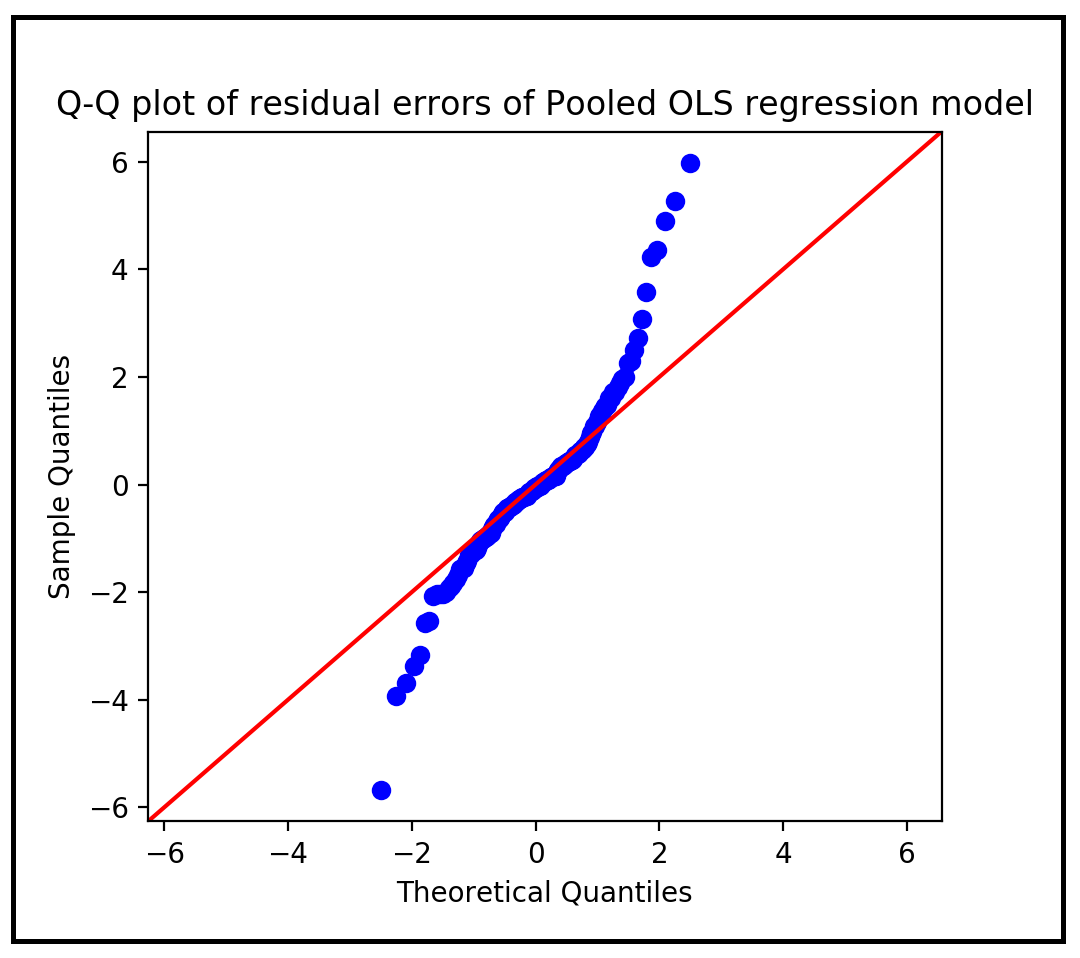
这里是我们观察问题的第一个迹象的地方。残差的Q-Q图是正态性的直观检验,它清楚地表明拟合模型的残差不是正态分布的。的输出备份Q-Q测试的结果Jarque-Bera和Omnibus测试对于训练总结底部面板中显示的正常情况。两个检验都表明残差不是正态分布在p < .001。


即使残差不是正态分布,Pooled OLS估计量仍然是面板数据回归问题的最佳线性无偏估计量(BLUE)。残差的非正态性不影响OLS回归模型的BLUE-ness。
残差不是正态分布的一个缺点是不能这样做建立可靠的置信区间用于模型的预测。我们可以容忍小的偏离正态,但大的偏离都不能使用正态分布或学生t分布。因此,不能(因此也不应该)计算可靠的置信区间。
残差是同方差的吗?
OLS估计器不是非常高效。(尽管它仍然无偏见的),如果OLSR模型的残差是异方差的,即残差的方差在所有值上都不是恒定的X.
让我们直观地检查残差,看看是否有任何趋势存在于残差对X:
图,ax = plt。次要情节()无花果。suptitle('合并OLS与X的原始残差')plt。ylabel('残差(y - mu)')plt。包含(“X =”+str(X_var_names [0]))斧子。散射(pooled_X [X_var_names [0]], pooled_olsr_model_results。渣油,年代= 4,c='黑色的',标签='残差')plt。显示()
我们可以看到下面的图。的不同值,残差似乎没有恒定的方差X.我用红色箭头标出了方差趋势:

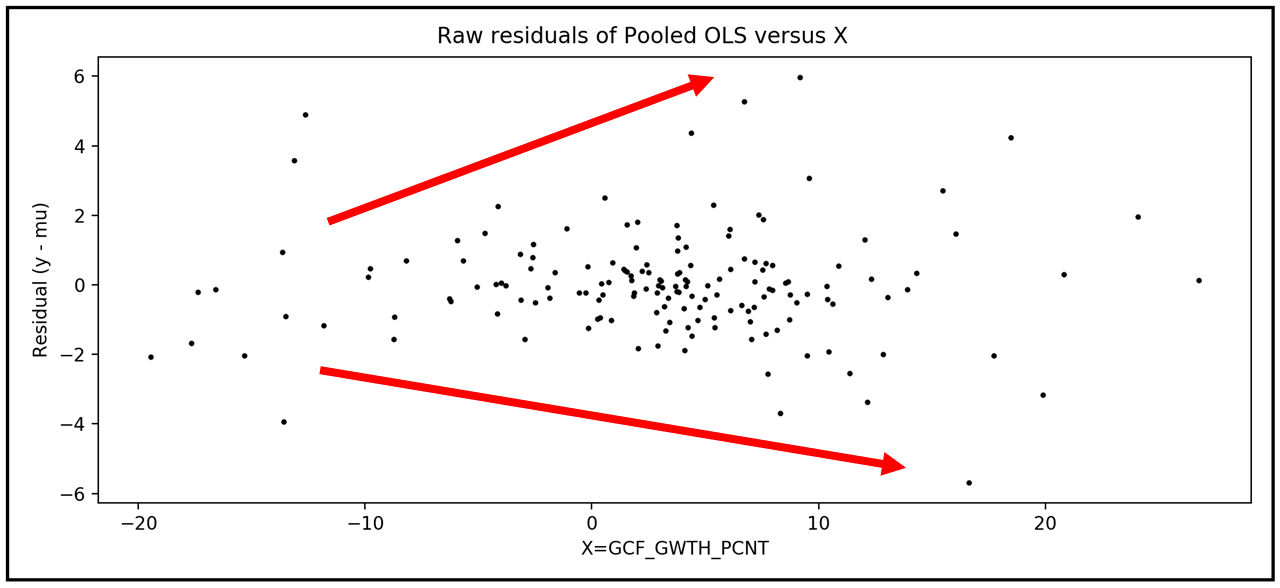
运行后可以证实其异方差白色的测试其中我们将回归残差的平方X并对得到的回归模型系数进行显著性检验:
钥匙= [“拉格朗日乘数统计:”,LM测试的p值:,
的f统计量:,F-test 's ' 'p-value:']结果=het_white(渣油= pooled_olsr_model_results。渣油,exog= pooled_X)打印(残差异方差White检验结果===>)
打印(lzip(结果)键)
我们看到如下输出:
残差异方差White检验结果===>
[('拉格朗日乘数统计:',9.918681580385458), (" LM检验的p值:",0.007017552347485667), (f统计量:,5.186450932829045),(“f检验的p值:”,0.006582734100668208)]
LM测试的p值< .001拒绝零假设证明残差是同方差的。
如前所述,即使拟合模型的残差是异方差的,Pooled OLS回归模型也将对总体值产生无偏估计。但是残差中的异方差会违反其中一个高斯-马尔可夫假设使OLS估计量成为手头问题的最佳线性无偏估计量。具体地说,当残差为异方差时,OLS估计量为效率低下的也就是说,它失去了在所有可能的线性无偏估计量中产生方差最小的预测的能力。当残差为异方差时,OLS估计器会低估或高估参数估计中的方差,从而导致参数估计的标准误差被遗漏。由于标准误差用于计算置信区间,参数估计的置信区间也变得不正确。与模型预测相关的标准误差和置信区间也出现了同样类型的缺失。
残差是否与响应变量y相关?
让我们绘制残差对y=GDP_PCAP_GWTH_PCNT的图:
图,ax = plt。次要情节()无花果。suptitle('合并OLS与y的原始残差')plt。ylabel('残差(y - mu)')plt。包含(' y ')斧子。散射(pooled_y pooled_olsr_model_results。渣油,年代= 4,c='黑色的',标签='残差')plt。显示()
我们得到如下图:

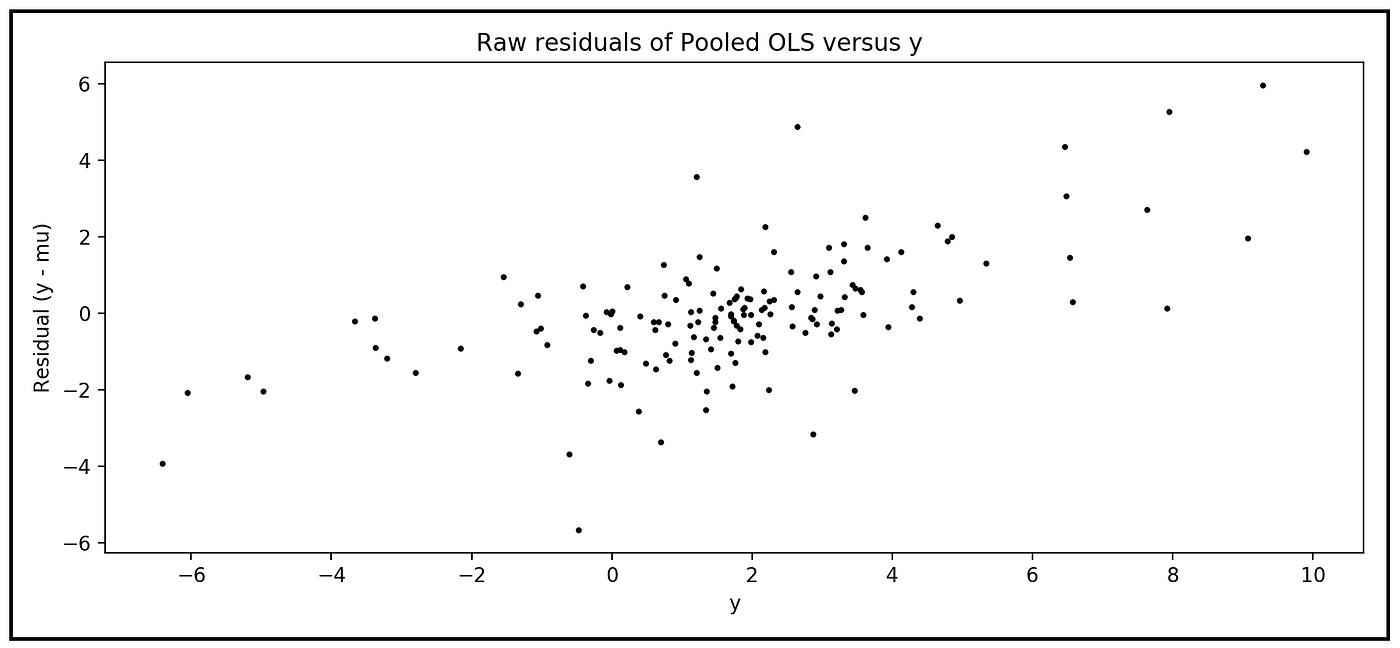
残差和之间似乎存在线性趋势y.相关性检验使用皮尔森是r证实了这个视觉判断:
钥匙= [”皮尔森\ ' s r:“,的假定值:]结果= st。pearsonr(x= pooled_y,y= pooled_olsr_model_results。渣油)打印(残差与响应变量y ===>相关性的Pearson r检验结果)打印(lzip(结果)键)
我们看到如下输出:
残差与响应变量y ===>相关的Pearson's r检验结果
((“皮尔森的r:, 0.6149931069935411), ('假定值:”,3.996454333518694 e-18))
第一个值0.61499是残差和之间的相关性(~ 61%)y,第二个值3.99645e-18为结果的p值。我们将忽略报告的p值,因为我们知道残差远远不是正态分布的。无论如何,报告的相关性(61%)本身明显大于零,因此是显著的。
回归残差与响应变量之间的高度相关性表明,我们的Pooled OLSR模型缺少重要的解释变量,否则这些解释变量将能够“解释”部分相关性。不论人均国内生产总值增长率(y),即总资本形成率(X)已无法解释已泄漏到残差的形式,两者的相关性y,以及异性性。
残差是否自相关?
让我们绘制残差的自相关函数(ACF)图:
的东西。plot_acf(x= pooled_olsr_model_results。渣油)plt,告诉()
我们可以看到下面的情节:

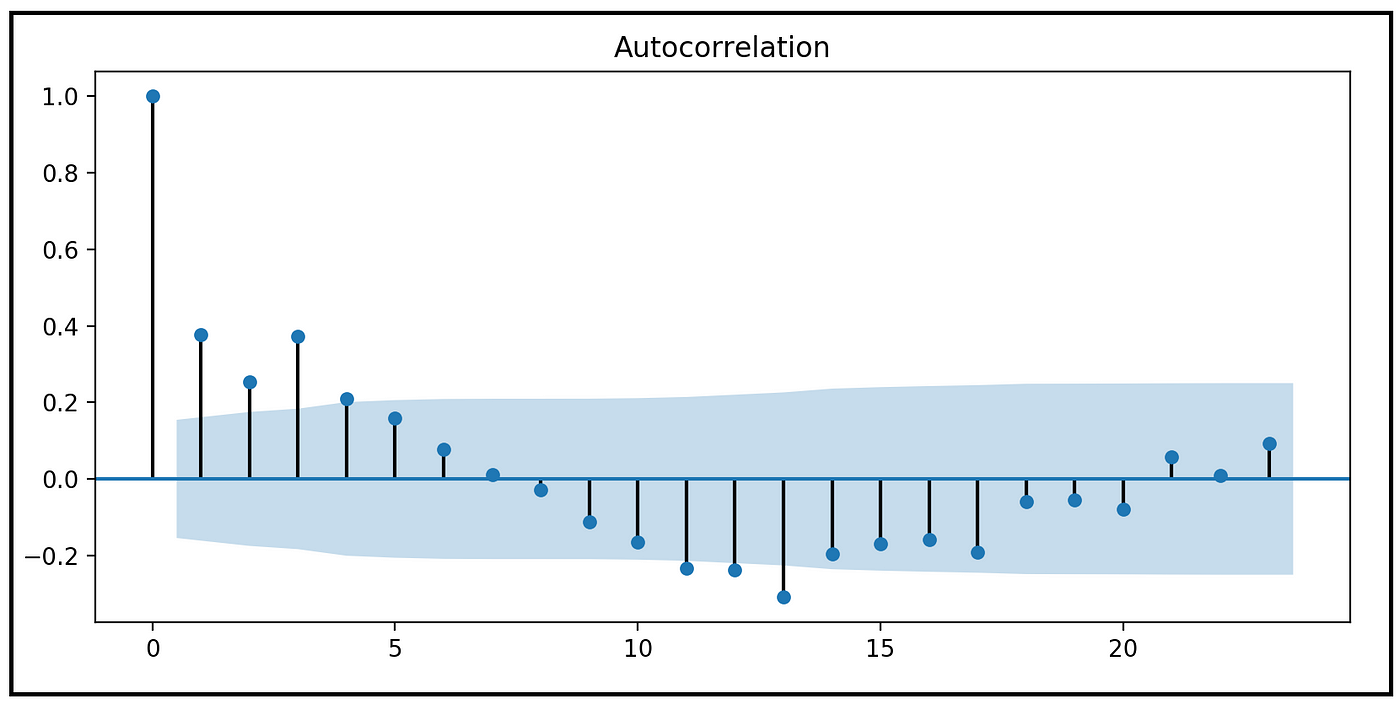
滞后0时1.0的完全相关可以忽略,因为一个数字总是与自身完全相关。但我们发现滞后1、2和3时的残差之间存在显著的自相关性。
正如残差中的异方差一样,残差中的自相关违反了使OLS估计量为BLUE的高斯-马尔可夫假设之一。具体来说,自相关残差会导致标准误差未被指定(低估),从而导致t值(或z值)被高估,以及参数估计的置信区间未被指定。实际上为零的系数,即不重要的系数,可能会被错误地报告为非零(重要)。
调查结果摘要
综上所述,我们发现我们为World Bank数据集建立的Pooled OLS回归模型具有以下属性:
- 它的调整后的r平方约为62%这对于真实世界的数据集来说还不错。
- 的模型的参数系数是显著的p <。001。
- f检验表明参数系数是共同显著的p <。001。
- 的模型的残差不是正态分布,这意味着与模型预测相关的标准误差和置信区间可能并不完全可靠。
- 的残差是异方差的说明模型参数的参数显著性t检验结果、参数估计的相应置信区间和f检验结果不完全可靠。该结论适用于与模型预测相关的标准误差和置信区间。
- 的残差与响应变量相关y这意味着该模型遗漏了重要的回归变量,否则将与之相关y,它们的缺失导致相关的平衡量泄漏到残差中。
- 的残差在滞后1、2和3时自相关这意味着模型参数估计的标准误差可能被低估,而报告的z值(或t值)也相应被高估。从功能上讲,残差中的自相关意味着回归模型的普遍缺失。
总的来说,对Pooled OLSR模型残差的分析指向了对手头问题的回归模型的错误规范。我们也许可以用另外两种回归模型中的一种做得更好,这两种回归模型是针对面板数据集的,即固定的影响和随机效应回归模型。
在我下周的文章中,我们将深入研究固定效应回归模型,并研究如何在世界银行数据集上建立和拟合固定效应模型。我们将比较它与Pooled OLSR模型的拟合优度。
这是下载链接为世界银行数据集使用本文。
下面是本文使用的完整源代码:
参考文献,引用和版权
数据集
世界发展指标数据来自世界银行CC BY 4.0许可证.下载链接
纸张及书籍连结
巴迪·h·巴尔塔吉,面板数据的计量经济学分析,第六版,施普林格
威廉·h·格林,计量经济学分析第八版,2018年,皮尔森
图片
本文中所有图片均为版权所有萨钦日期下CC-BY-NC-SA,除非图片下方注明了其他来源和版权。