主成分分析(PCA)视力为零的数学解释
主成分分析(PCA)是一个不可或缺的工具,可视化和数据科学降维,但通常是埋在复杂的数学。很困难,至少可以说,充实我的大脑,为什么,很难欣赏美丽的全谱。
虽然数字证明的有效性很重要的概念,我相信这是同样重要的是分享数字背后的故事,一个故事。
主成分分析是什么?
主成分分析(PCA)是一种技术,将高维数据转换成低维度空间,同时保持尽可能多的信息。
主成分分析是非常有用的在处理数据集时,有很多功能。常见的应用,如图像处理、基因组研究总是要处理成千上万,如果不是数以万计列。
虽然有更多的数据总是伟大的,有时他们有如此多的信息,我们早就不可能模型训练时间和诅咒的维度开始成为一个问题。有时,少即是多。
我喜欢比较PCA和写一本书总结。
找到时间去读一本1000页的书是奢侈品,很少人能用得起。不是很好如果我们能总结最重要的点在2或3页,甚至很容易消化的信息最繁忙的人吗?在这个过程中我们可能会失去一些信息,但嘿,至少我们得到了大局。
主成分分析是如何工作的呢?
这是一个两步的过程。我们不能写一本书总结如果我们没有阅读或理解这本书的内容。
PCA是同样的方式,理解,然后总结。
理解数据的主成分分析方法
人类理解的意思故事书通过使用富有表现力的语言。不幸的是,PCA不讲英语。它必须在我们的数据中发现意义通过其首选语言,数学。
这里的百万美元问题是…
- PCA能理解,我们的数据是很重要的一部分吗?
- 我们可以在数学上量化嵌入的信息量的数据?
好吧,方差可以。
方差越大,越多的信息。亦然。
对大多数人来说,差异并不是一个陌生的词。在高中我们学到,方差措施平均程度不同于每一点的意思。


但它并没有把方差与信息。所以这个协会来自哪里?为什么它有意义吗?
假设我们和我们的朋友玩一个猜谜游戏。这个游戏很简单。我们的朋友会遮住脸和我们需要猜谁是谁完全基于他们的身高。我们是好朋友,我们每个人都记得高。


我先走了。

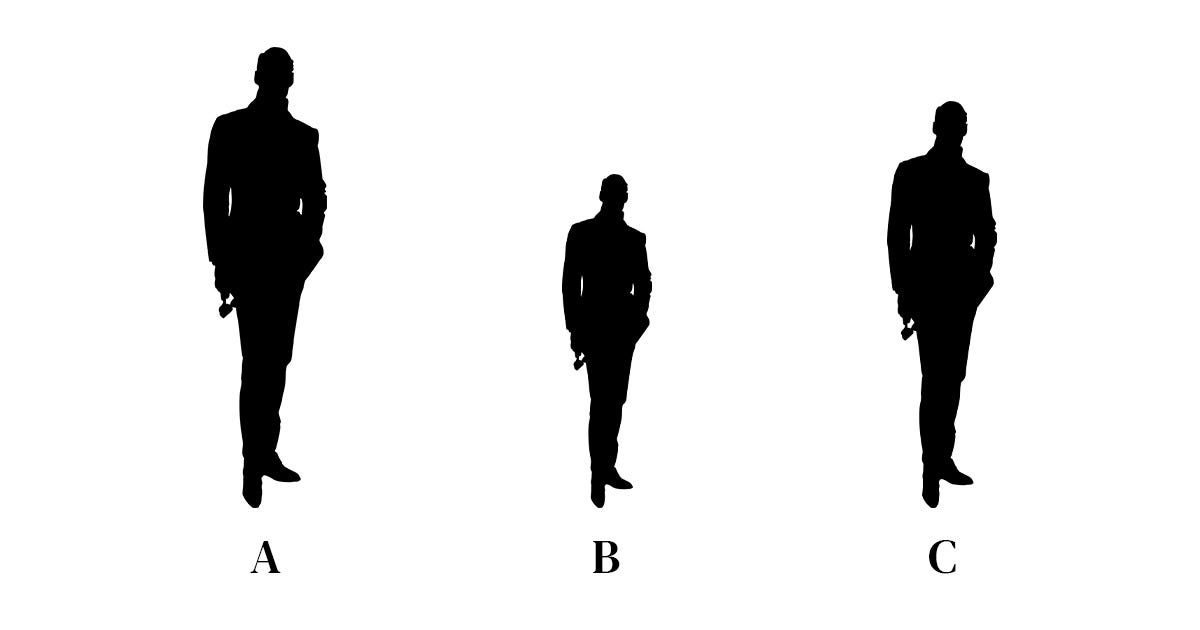
毫无疑问,我要说的这个人是克里斯,B是亚历克斯,C是本的人。
现在,让我们试着猜另一群朋友。

轮到你。


你能猜出谁是谁吗?困难当他们在高度非常相似。
早些时候,我们没有麻烦区分一个185厘米的人从一个160厘米和145厘米的人因为他们的身高不同很多。
同样的,当我们的数据有更高的方差,它拥有更多的信息。这就是为什么我们总是听到PCA和最大方差相同的句子。我想正式通过引用维基百科的一个片段。
PCA的定义是正交线性变换将数据转换到一个新的坐标系统,最大方差一些标量数据的投影来躺在第一个坐标(称为第一主成分),第二大方差在第二个坐标,等等。
在PCA的眼睛,方差是客观和数学方法量化信息的数据量。
方差是信息。
驱动点回家,我提议的复赛猜谜游戏,只是这一次,我们去猜测谁是谁根据自己的身高和体重。
第二轮。


一开始,我们只有高度。现在,我们基本上翻了一倍的数据量在我们的朋友。会改变你的猜测策略?
这是一个很好的过渡到下一节,主成分分析总结了我们的数据,或者更确切地说,降低维数。
总结数据与主成分分析
就我个人而言,重量差异如此之小(a.k.。一个小方差),它不帮我区分我们的朋友。我仍然不得不主要依靠高度让我猜测。
直觉上,我们刚刚降低我们的数据从二维到一维。我们的想法是我们可以选择性地保持较高的变量方差,然后忘记变量方差较低。
但如果,只是如果身高和体重相同方差吗?这意味着我们不能再减少数据集的维数?我想说明这与样本数据集。




在这种情况下,很难选择我们想要的变量删除。如果我扔掉的一个变量,我们扔掉一半的信息。
我们可以保持这两个吗?
也许,不同的角度。
最好的故事书总是隐藏主题不但是写的隐含。阅读每一章单独不会有意义。但是如果我们读它,它给了我们足够的上下文来块拼图在一起,底层的情节出现。
到目前为止,我们只看身高和体重的方差。而不是限制自己只选择一个或另一个,为什么不把它们呢?
当我们仔细审视我们的数据,方差的最大数量不在于轴,不是轴,而是一个斜线。第二大方差将线穿过第一个90度。


代表这2行,主成分分析结合身高和体重来创建两个新的变量。可能是身高和体重70% 30%,13.8%或87.2%的身高和体重,或任何其他组合根据我们的数据。
这两个新的变量被称为第一主成分(PC1)和第二主成分(PC2)。而不是使用两个轴上的身高和体重,我们可以使用分别PC1和PC2。


后所有的诡计,让我们看一看差异。




PC1仅可以捕获的总方差身高和体重的总和。PC1以来所有的信息,你已经知道钻——我们可以在去除PC2很舒服,知道我们的新数据仍然是原始数据的代表。
实际数据时,通常情况下,我们不会得到主成分捕获100%的方差。执行主成分分析将给我们N的主成分,其中N等于原始数据的维数。从这个列表的主要组件,我们一般选择最少的主要组件,可以解释最多的原始数据。
一个伟大视觉援助将帮助我们做出这个决定是一个小石子的阴谋。

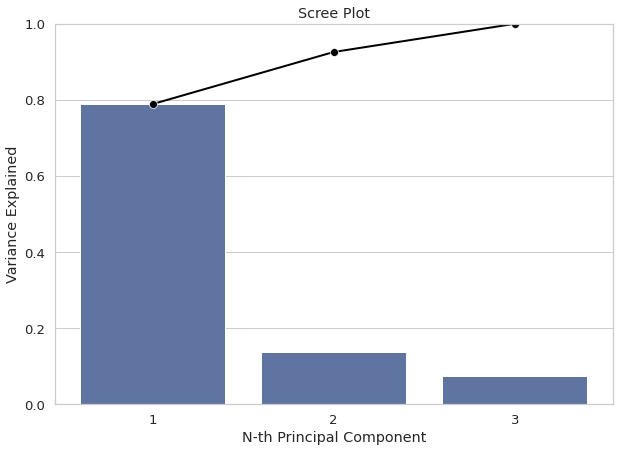
条形图的比例告诉我们每个主成分的方差解释道。另一方面,叠加线图表给我们解释方差的总合直到n主成分。理想情况下,我们希望能获得至少90%的方差只有2 - 3个因子,这样足够的信息保留在我们仍然可以想象我们的数据图表。
看图表,我会感觉舒服使用2主成分。
电脑离他而去
因为我们没有选择的所有主要组件,我们不可避免地失去一些信息。但我们还没有完全描述我们正在失去什么。让我们深入研究的一个新玩具的例子。

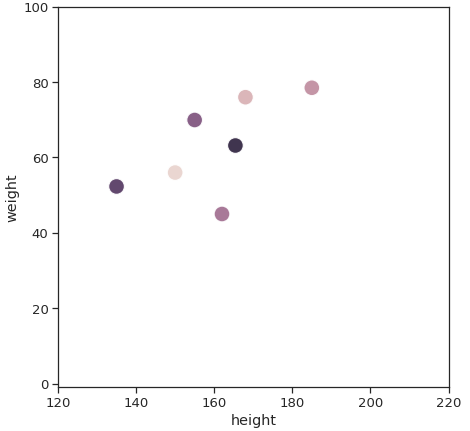
如果我们给数据通过PCA模型,将开始通过第一主成分之后,第二主成分。当我们改变我们的原始数据从二维到二维,一切保持不变,除了取向。我们只是旋转数据,以便在PC1最大方差。这里没有最新进展。

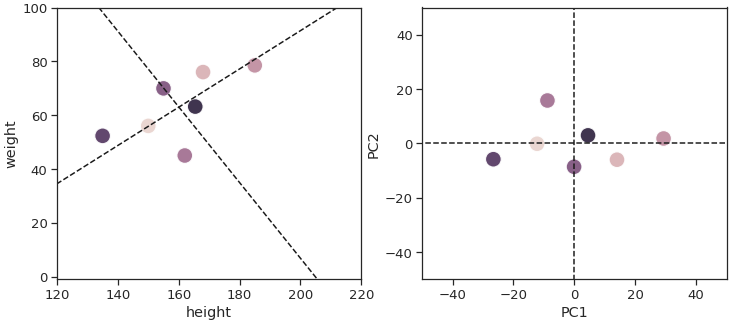
然而,假设我们已经决定只保留第一主成分,我们将项目所有数据点到第一主成分,因为我们不再有轴。


我们将失去的是距离在第二主成分,下面用红色突出了线。


这影响了每个数据点的距离。如果我们看看两个特定点(a.k.之间的欧氏距离。成对的距离),你会发现一些原始数据的点是更远比转换后的数据。


PCA是一个线性变换,所以本身不会改变距离,但是当我们开始删除维度,距离变得扭曲。
变得棘手——并不是所有两两距离得到同样的影响。
如果我们把这两个最远的点,你会发现他们几乎平行于主轴。虽然他们的欧几里得距离仍然是扭曲的,它是一个较小的程度。


原因是主成分轴绘制的方向,我们有最大的方差。根据定义,方差当数据点之间的距离进一步增加。所以很自然的,点之间的距离最远的会使自己更好的与主轴。
说了那么多,减少维度与PCA的距离变化数据。它在维护大两两距离比小成对的距离。
这是为数不多的缺点减少维度与PCA和我们需要注意的,特别是当使用欧几里德基于距离的算法。
有时,它可能是更有益的原始数据上运行你的算法。这就是你,一个数据科学家需要做出决定根据你的数据和你的用例。
毕竟,数据科学是一门科学。
实现PCA在Python中
有更多的PCA超出了本文的前提。真正欣赏美丽的PCA的唯一方法是自己经验。因此,我想在这里分享一些代码片段任何人想弄脏手。完整的代码可以被评估在这里与谷歌Colab。
首先,我们把进口的并生成一些数据,我们将一起工作。
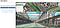
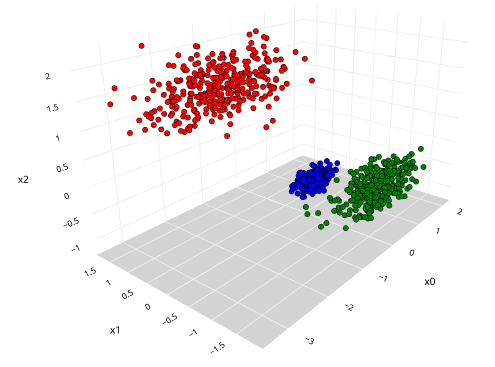
玩具数据集有3个变量——x0, x1, x2,分布式的方式聚集在一起,三种不同的集群。“cluster_label”告诉我们,属于集群的数据点。

它总是一个好主意来可视化他们尽可能。

数据似乎准备PCA。我们要试着降低维数。幸运的是,Sklearn PCA很容易执行。即使我们花了2000多单词解释主成分分析,我们只需要三行来运行它。
这里有两个移动部件。当我们满足我们的数据Sklearn PCA的函数,它的所有重型多一点回报我们一个PCA模型和转换数据。
众多的模型给我们访问属性,如特征值,特征向量,原始数据的均值,方差解释说,这样的例子不胜枚举。这些都是非常深刻的,如果我们想了解PCA所做的与我们的数据。
我想强调的是一个属性pca.explained_variance_ratio_这告诉我们每个主成分方差解释的比例。我们可以想象这一块小石子。


图表告诉我们,使用2主成分代替3很好因为他们可以捕捉+ 90%的方差。
除此之外,我们还可以看看每个主要组件创建的变量的组合pca.components_ * * 2。我们可以使用一个热图来展示这一点。


在我们的示例中,我们可以看到,PCA1是由34%的x0, 30%的x1, x2的36%。PCA2主要是由x1。
有很多由Sklearn提供更有用的属性。对于那些有兴趣,我建议看看PCA的属性部分Sklearn文档。
现在我们更好地理解主成分,我们可以做出最终决定我们想要保持的主成分。在这种情况下,我觉得2个主成分就足够了。
所以,我们可以重新运行PCA模型,但是这一次的n_components = 2论点,它讲述了PCA只保留前2个主成分。
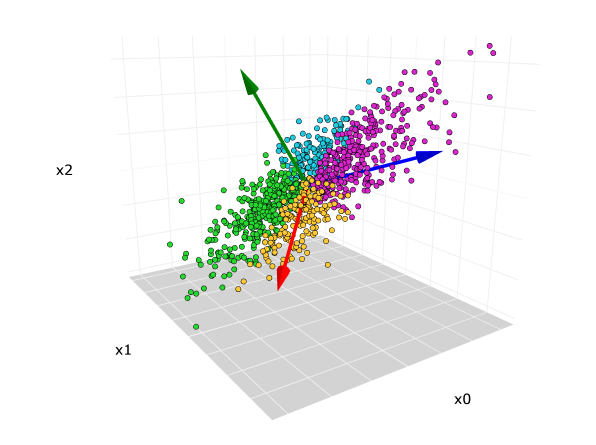
这将返回我们的DataFrame前两个主成分。最后,我们可以画一个散点图可视化数据。


最后的评论
PCA是一个数学上美丽的概念,我希望我能够传达一个随意的语气那样就不会觉得不知所措。对于那些急于考虑细节,我附上了一些有趣的讨论/下面的参考资料,供细阅。
谢谢你的时间,祝你有美好的一天。
[1]:中等,Farhad马利克(2019年1月7日)。特征值和特征向量是什么?
https://medium.com/fintechexplained/what - -特征值和特征向量- -必须知道-概念- -机-学习- 80 d0fd330e47
[2]:GitHub。深入:主成分分析
https://jakevdp.github.io/PythonDataScienceHandbook/05.09-principal-component-analysis.html
[3]:课件,whuber(2013年2月21日)。应该删除一个高度相关的变量在PCA干什么?
https://stats.stackexchange.com/questions/50537/should-one-remove-highly-correlated-variables-before-doing-pca
[4]:课件,ttnphns(2017年4月13日)。PCA和比例的方差解释道https://stats.stackexchange.com/questions/22569/pca-and-proportion-of-variance-explained
[5]:课件、变形虫(2017年4月13日)。是什么意思PCA保留只大两两距离?
https://stats.stackexchange.com/questions/176672/what-is-meant-by-pca-preserving-only-large-pairwise-distances
[6]:课件、变形虫(2015年3月6日)。进行主成分分析,特征向量和特征值
https://stats.stackexchange.com/questions/2691/making-sense-of-principal-component-analysis-eigenvectors-eigenvalues/140579 # 140579