分布式计算的初学者指南
7个基本概念在Python中取得分布式计算的成功
输入分布式宇宙
越来越多的数据科学家正在进入分布式计算的世界,以扩大其计算并更快地处理更大的数据集。但是,开始您的分布式计算旅程可能有点像进入替代宇宙:压倒性,令人生畏和混乱。


但这是个好消息:您无需了解有关分布式计算的所有内容即可开始。
这有点像去c度假o在您不会说语言的地方举动。在开始飞行之前,学习如何在当地政治体系的复杂性上进行整个对话是过于杀人的。但这可能很聪明足够了解并寻求帮助当您需要时。
这篇文章解释了7基础概念,您需要开始分布式计算。尽早掌握这些基本概念将为您节省数小时的研究和昂贵的错误。这些概念将使用Python中的代码证明dask。
让我们潜水。
1.懒惰评估
懒惰的评估是一种编程策略,延迟表达式或变量的评估,直到需要其值。这是相反的严格的或者渴望评估在调用时直接评估表达式。懒惰评估可以通过避免不必要的评估重复来增加计算和减少内存负载的优化。


让我们用思想实验来说明。
与Mercutio见面,这是我们三次旋转的分布式计算鼠标。


Mercutio将参加实验。该实验的目的是让Mercutio找到通过迷宫到最终目的地的最快方法:一件美味的切达干酪。通过放置面包屑来指导默达蒂奥,可以定义穿过迷宫的路径。该实验的目的是要尽快到达奶酪,因此,Mercutio将为他吃的每个面包屑输掉1分。
在方案1中,放置第一个面包屑并从面包屑到面包屑后立即开始行走(按计算术语执行”(以计算方式执行”)。这样,他当然会最终到达他的切达斯坦。他会的还已经产生了5个负数,一个他经过(和吃)的每个面包屑。这不是解决问题的方法,而是最佳解决方案。
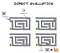
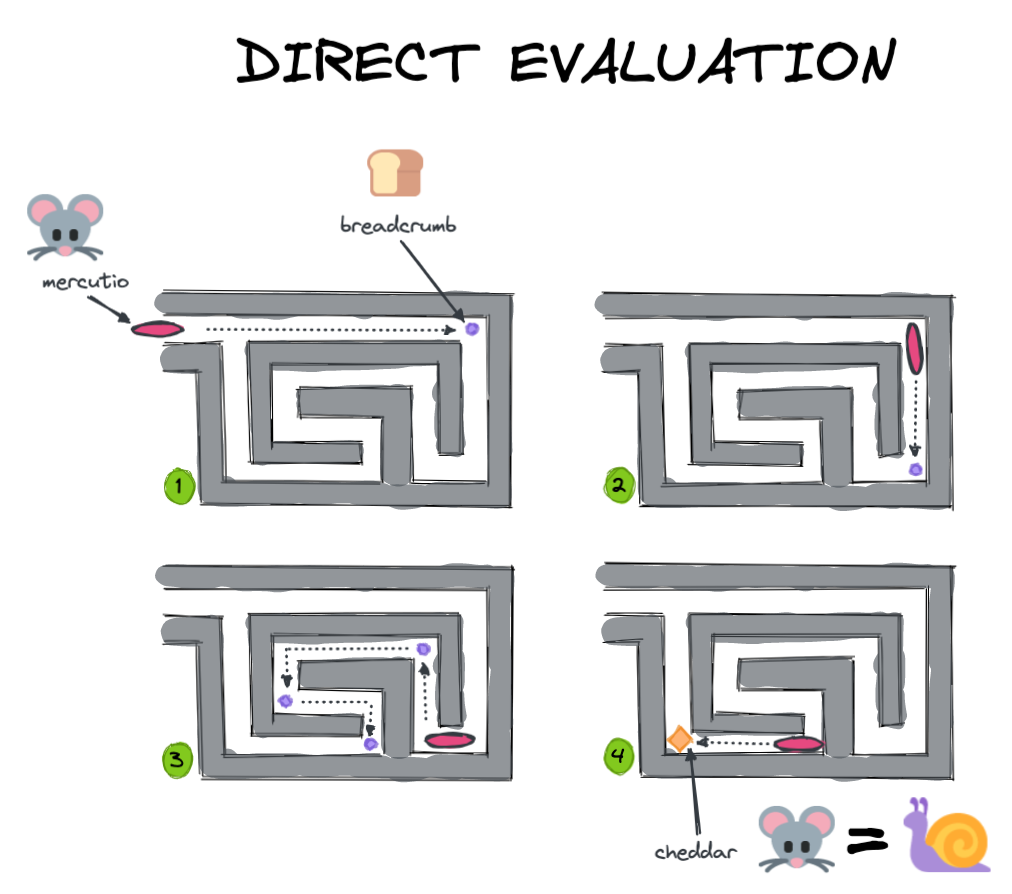
但是,如果Mercutio有延迟他的处决,直到您放下奶酪和然后评估情况,,,,他将能够看到整个问题,并找出解决问题的最快方法。

Mercutio都取得了预期的结果(吃奶酪!),但是懒惰或“延迟”评估Mercutio能够更快,更有效地做到这一点。
代码示例
让我们以pandas(急切的评估)和dask(懒惰评估)中的python代码中的示例演示。在下面的代码中,我们将创建一个数据框架,调用该数据框架,然后在特定列上设置一个GroupBy计算。请注意,大熊猫如何立即返回结果,而Dask仅当您专门告诉它开始计算时才这样做。
导入大熊猫作为pd#创建一个数据框
df = pd.dataframe({
“名称”:[“ Mercutio”,“ Tybalt”,“ Lady Montague”],
“年龄”:[3,2,4],
“ fur”:[“灰色”,“灰色”,“白色”]}
)#调用数据框
DF
#定义一个集体计算
df.groupby('fur')。age.mean()
我们看到大熊猫热切地评估我们定义的每个陈述。数据帧定义和组计算的结果都立即返回。这是在大熊猫工作时的预期行为,并且在使用相对较小的数据集时可以舒适地适合您机器的内存。
当您的数据框中包含的数据比计算机在内存中保留的数据还要多时,就会出现问题。熊猫别无选择,只能尝试将数据加载到内存中……然后失败。
这就是为什么像Dask这样的分布式计算库评估懒惰的原因:
导入dask.dataframe作为DD#将DF变成DASK数据帧
dask_df = dd.from_pandas(df,npartitions = 1)#调用DataFrame(未返回任何内容)
dask_df
#定义与上述相同的组计算(未返回结果)
dask_df.groupby('fur')。age.mean()
dask不返回结果当我们调用数据框,或定义GroupBy计算时。它仅返回结果的模式或概述。
只有当我们专门致电时。计算()将DASK实际执行计算并返回结果。这样,它可以等待找到达到所需结果的最佳路线,就像上面方案2中的Mercutio一样。
#触发计算
dask_df.groupby('fur')。age.mean()。compute()


懒惰评估允许诸如Dask之类的库来通过识别计算的一部分来优化大规模计算尴尬地平行。
2.尴尬地平行
“尴尬平行”一词用于描述可以轻松分为较小任务的计算或问题,每个任务都可以独立运行。这意味着任务之间没有依赖性,并且可以按任何顺序并行运行。这些类型的问题有时也称为“完全平行”或“令人愉悦的平行”。

让我们回到我们的思想实验。
我们亲爱的朋友Mercutio已与两名同伴一起参加,他们还将参加懒惰的评估奶酪调查任务。我们将为三个Mouseketeer设置两个不同的实验。
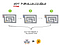
在实验1中,切达干酪的块分为3个相等的部分,每个部分都放在不同的迷宫末端。在实验2中,奶酪块保持整体,并放在迷宫末端的锁定盒子内,迷宫1和2每个包含一个锁定的盒子,该盒子容纳了下一个迷宫盒的钥匙。这意味着鼠标1将需要从迷宫中获取钥匙并将其传递给鼠标2,后者需要对鼠标进行相同的操作。3的目标是将整个奶酪块食用。
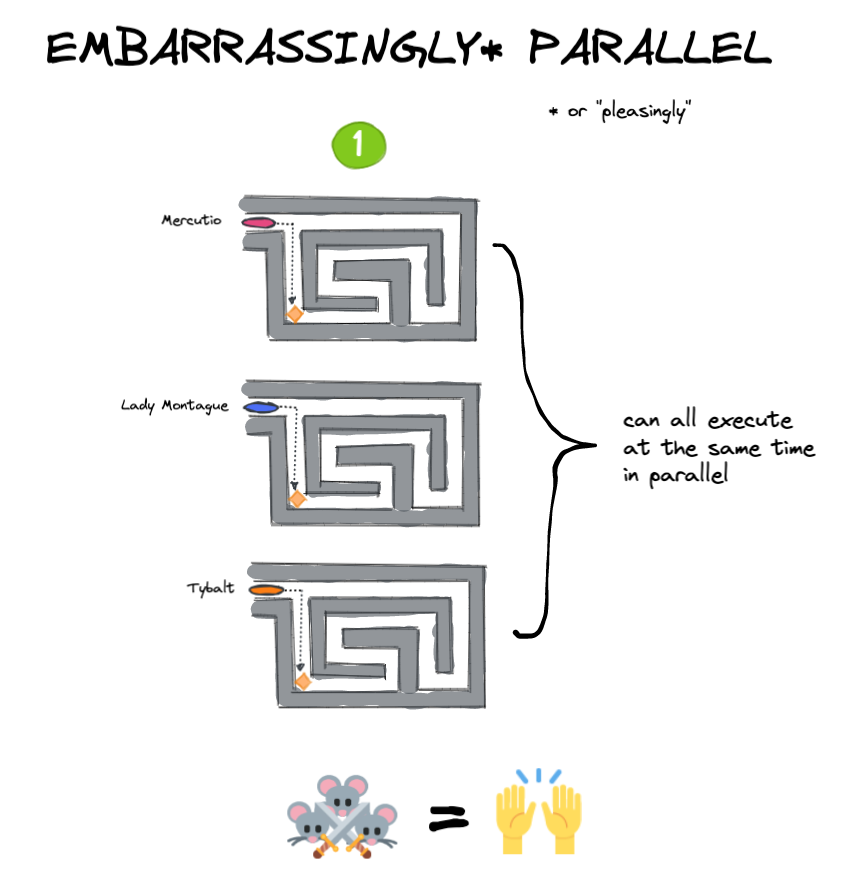
实验1(上图)是一个例子尴尬地平行问题:每个MouseKeteer都可以独立解决自己的迷宫,从而并行完成整体任务(吃奶酪块)。
实验2(下图)是一个根本无法平行的问题的示例:解决每个迷宫取决于首先解决先前的迷宫。
事实上,您在分布式计算中遇到的问题将落在完全令人尴尬的平行且根本不平行之间的频谱上。在大多数情况下,计算的一部分可以轻松并行运行,而其他部分则无法并行运行。诸如DASK之类的分布式计算库将为您解决。
代码示例
一个简单的循环是一个常见的尴尬并行问题的一个示例:循环的每次迭代都可以独立运行。蒙特卡洛模拟是一个更复杂的示例:它是一种使用重复的随机抽样来估计概率的模拟。每个随机抽样均独立运行,并且不会以任何方式影响其他采样。
#简单的循环是一个令人尴尬的平行问题对于我的范围(0,5):
x = i + 5
打印(x)
将分区的镶木材料读取到DASK数据框架中是一个令人尴尬的并行问题的另一个示例。
df = dd.read_parquet(“ test.parquet”)
df.visalize()
为了比较,这是在同一数据框架上进行组计算的任务图DF:
这显然是不是一个令人尴尬的并行问题:图中的某些步骤取决于先前步骤的结果。这并不意味着问题根本无法平行。dask仍然可以平行部分通过将您的数据划分为计算分区。
3.分区
一个分区是可以独立于其他分区处理的数据的逻辑分割。分区用于分布式计算景观的许多区域:镶木点文件分为分区,以及DASK数据范围和Spark RDD。这些批次数据有时也称为“块”。
在上面的令人尴尬的并行实验1中,我们将实验(奶酪块)的目标“划分”为3个独立的分区或块。然后,每个Mouseketeer都可以在单独的分区上进行必要的工作,从而实现食用奶酪块的整体目标。

DASK数据框也分为分区。DASK数据框架中的每个分区都是一个独立的PANDAS数据框架,可以将其发送到要处理的单独工人。
当你将dask数据框架写入parquet,每个分区将写入自己的镶木隔板。
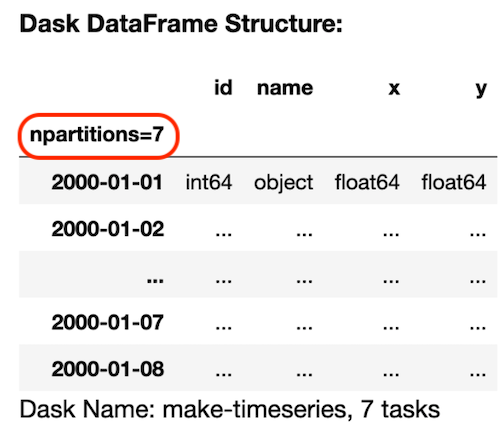
df = dask.datasets.timeseries(
“ 2000-01-01”,
“ 2000-01-08”,
freq =“ 1H”,
partition_freq =“ 1d”
)df.npartitions>> 7DF

#将每个DASK分区写入单独的镶木隔板
df.to_parquet(“ test.parquet”)
为了将我们到目前为止讨论的概念汇集在一起,将分区的镶木木材文件加载到dask数据框架中将是一个令人尴尬的并行问题,因为每个镶木木隔板都可以加载到其自己的DASK数据框架分区中,而无需对其他分区的任何依赖性:
df = dd.read_parquet(“测试”)
df.visalize()
如上所述的任务图由A创建和委派调度程序。
4.调度程序
调度程序是一个计算机流程,该流程可以安排数据的分布以及在分布式计算系统中该数据上的计算编排。它可以确保同时对数据进行有效,安全地处理数据,并根据可用资源分配工作负载。

在一个简单的令人尴尬的并行问题中,例如平行为了循环,跟踪谁在做什么是相对容易的。但是,当使用包含数百万甚至数十行数据的数据集时,这变得更加困难。哪个机器有哪一部分?我们如何避免重复?如果有重复,我们应该使用哪个副本?我们如何正确地将所有分区拼凑成一个有意义的整体?
要返回Mercutio和他的朋友,假设我们的三个Mouseketeers都负责准备一顿复杂餐的独立组成部分:Mercutio油炸洋葱,泰巴尔(Tybalt)在奶酪上磨碎奶酪,而蒙塔古(Montague)夫人却蒸西谷。


现在想象一下,没有3只小鼠在这个厨房里一起工作,他们的活动必须仔细协调并同步,以最佳使用可用的厨房用具。如果我们本身将这项协调任务留给了30只老鼠,那么很快就会混乱:每只鼠标都忙于做自己的独立工作,以至于能够清楚地概述整体情况,并以最有效的方式分配任务和资源。老鼠会提示使用相同的锅和刀,而这顿饭可能不会按时完成晚餐。
输入大厨。


大厨(又名“调度程序”)拥有餐点的权威食谱,并将根据需要将任务委托并为每个单独的烹饪鼠标分配资源。当餐食的各个元素得到充分准备时,每只鼠标都会将其工作结果归还给将它们合并到最终产品中的大师。

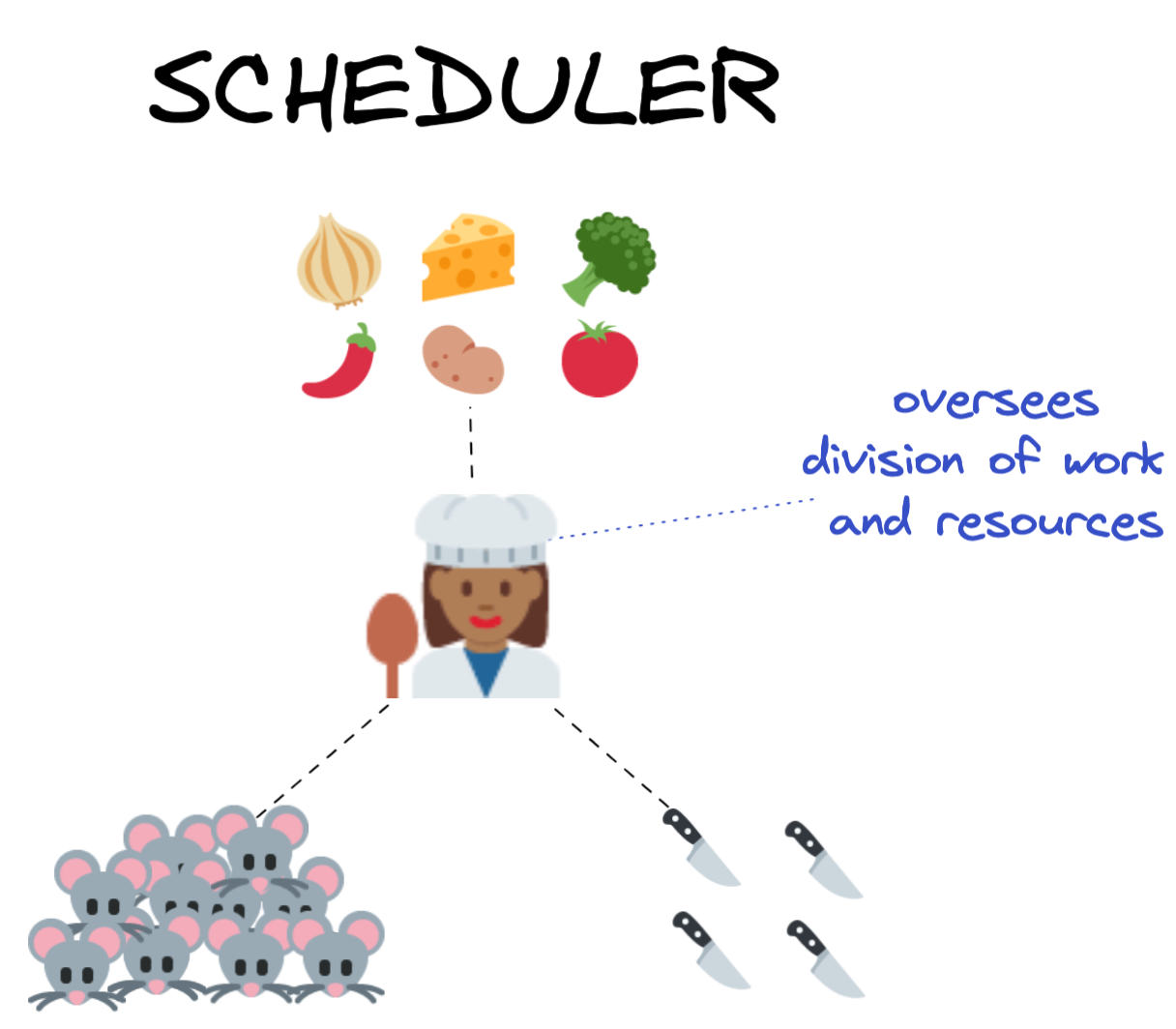
有许多不同类型的调度程序,对于您计划使用的分布式计算解决方案的特定选项,可能会很有用。根据您是在本地还是远程群集上的工作,调度程序可能是单个计算机或完全自动驾驶计算机中的单独流程。
调度程序是任何分布式计算的中心枢纽簇。
5.集群
集群是一组计算机或计算过程,它们共同执行工作作为单个单元。群集构成分布式计算系统的核心体系结构。
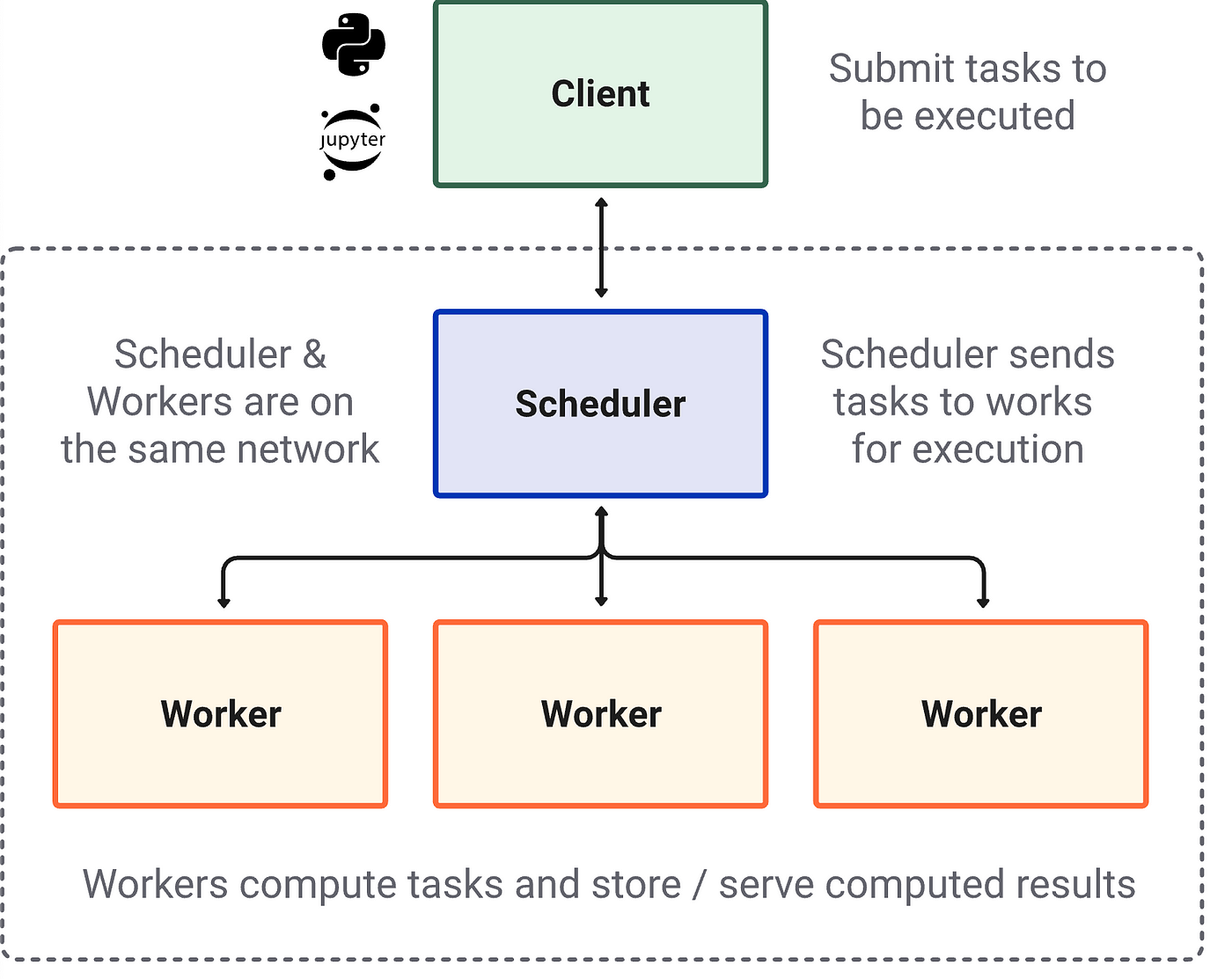
群集有许多共同的元素,无论特定的实现或体系结构如何:客户,调度程序和工人。
这客户是您编写包含计算说明的代码的地方。对于DASK,它是您的Ipython会话或Jupyter Notebook(或您在何处编写和运行Python代码)。
这调度程序是协调分布式计算系统的计算机流程。如果笔记本电脑上的本地群集,它只是一个单独的Python过程。对于大型超级计算机群集或云中的远程群集,调度程序通常是自动级计算机。
这工作人员是在数据分区上运行计算的实际工作的计算机过程。在笔记本电脑上的本地群集中,每个工人都是位于计算机单独核心上的过程。在远程群集中,每个工人通常都是自己的自主(虚拟)机器。
群集可以存在本地在一台机器中或远程,在服务器或云中的各种(虚拟)机器上分布。这意味着可以构建集群:
- 多个内核内一台机器
- 多个物理机器内相同的物理空间(高性能超级计算机),
- 多个虚拟机分布在物理空间(一个云计算集群)上
6.扩展与扩展
在分布式计算设置中工作时,您经常会听到人们使用“扩展”和“扩展”术语。这用于指代使用当地的vs a偏僻的簇。’扩展’意味着使用更多资源本地。“扩展”意味着使用更多资源远程。

例如,从熊猫(仅使用计算机中的单个核心)从运行计算过渡到使用当地的dask群集是扩大。将同样的工作量从熊猫移动到偏僻的盘盘是一个例子扩展。
#比例计算到云集群#带有盘绕的发射云集群
导入盘绕
cluster = coiled.cluster(n_workers = 20)#将群集连接到dask
来自dask.distribed Import客户端
客户端=客户端(群集)#在远程云集群上在40GB+数据上运行计算
ddf = dd.read_parquet(
's3:// coiled-datasets/limeseries/20年/parquet/'
)ddf.groupby('name')。x.Mean()。compute()
扩大还可以涉及从CPU过渡到GPU,即“硬件加速度”。Dask可以使用cudf而不是熊猫将您的数据框架操作转移到GPU中,以获得巨大的加速。(谢谢至雅各布·汤姆林森对于这一点的详细说明。)
7.并行与分布式计算
并行计算和分布式计算之间的区别是执行计算的过程是否使用单个共享内存。


并行计算使用共享单个内存的多个处理器执行任务。此共享内存是必要的,因为单独的过程正在同一任务上共同使用。并行计算系统受到可以连接到共享内存的处理器数量的限制。
另一方面,分布式计算使用没有单个共享存储器的多个自动计算机执行任务;计算机使用消息传递相互通信。这意味着将工作单位分为单独的任务,并且中央调度程序整理了每个单独任务的结果,并将最终结果送回用户。分布式计算系统在理论上是无限可扩展的。
喷气背包开出来!
本文中提出和解释的7个概念为您提供了在分布式计算的大宇宙中找到基础的必要基础。现在是时候系上那个喷气背包并继续自己探索了。
这Dask教程对于认真探索分布式计算的可能性的任何人来说,都是下一步的好。这是一个自节奏的教程,您可以在1-2小时内完成。
谢谢您的阅读!在LinkedIn上关注我用于常规分布式计算更新和黑客。
并且请考虑成为支持写作社区的中型成员:















