分布式计算的初学者的指南
7基本概念和分布式计算在Python中成功
进入分布式宇宙
越来越多的数据科学家正在冒险进入分布式计算的世界扩大他们的计算和处理大数据集的更快。但从你的分布式计算的旅程可以有点像进入另一个宇宙:势不可挡,恐吓和混淆。


但这是一个好消息:你不需要了解分布式计算开始。
这有点像去度假一个country你不懂的语言。它会多余学习如何保持整个谈话之前当地政治体系错综复杂的飞行。但它可能是聪明的知道足以让周围和寻求帮助当你需要它。
这篇文章解释了7基础概念你需要开始使用分布式计算。掌握这些基本概念在早期会节省你的时间研究和昂贵的错误。将演示代码在Python中使用的概念Dask。
就让我们一探究竟吧。
1。懒惰的评价
懒惰的评价编程策略,延迟一个表达式或变量的评价,直到它的价值是必要的。这是相反的严格的或即时抓取表达式的计算时直接调用。懒惰的评价可以增加优化计算和减少内存负载,避免不必要的重复评价。


让我们用一个思想实验来加以说明。
满足我们thrice-knighted茂丘西奥,分布式计算米老鼠小人。


茂丘西奥将是参与一个实验。茂丘西奥这个实验的目的是找到最快捷的方式通过一个迷宫的最终目的地:一块美味的切达干酪。通过迷宫的路径将被定义为把面包屑指导茂丘西奥。这个实验的目的是尽可能快的奶酪,茂丘西奥将失去1点每一个面包屑他吃。
在场景1中,茂丘西奥开始行走(“执行”计算计算)后立即将你从第一个面包屑和遵循面包屑导航。当然,这样他会最终到达Cheddastination。他将也有发生5 -点,每个面包屑经过(吃)。这不是一个错误的解决问题的办法而不是最优的,。
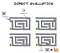
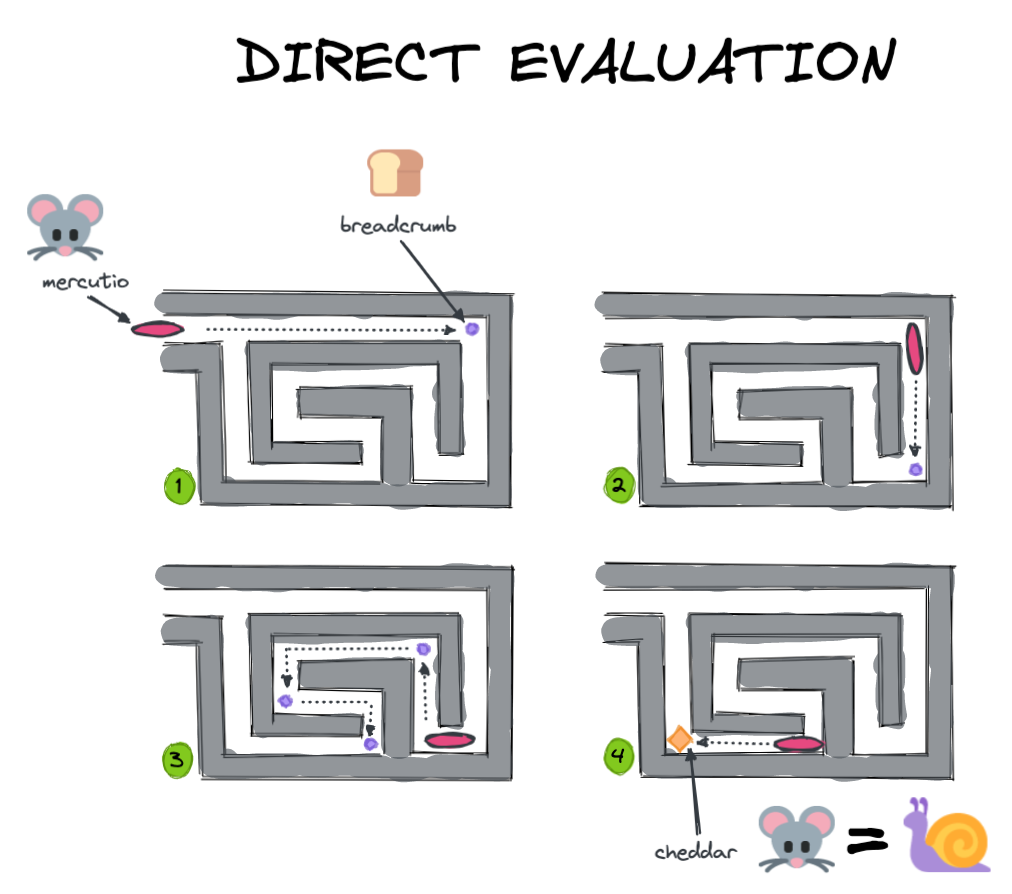
然而,如果茂丘西奥延迟他直到你放下奶酪和执行然后评估情况,他已经能够看到整个问题,找出最快的方法来解决这个问题。

茂丘西奥的实现所需的结果(吃奶酪!),但是懒惰或“延迟”评价茂丘西奥能够更快、更有效地这样做。
代码示例
让我们用一个例子说明在Python代码使用熊猫(即时抓取)和Dask(懒惰的评价)。在以下代码中,我们将创建一个DataFrame,称之为DataFrame然后建立groupby计算特定列。注意熊猫立即返回结果,而Dask只有当你明确告诉它开始计算。
熊猫作为pd导入#创建一个dataframe
df = pd.DataFrame ({
“名称”:[“茂丘西奥”、“提伯尔特”,“夫人蒙塔古”),
“年龄”:3、2、4,
“皮毛”:[“灰色”、“灰色”、“白”)}
)#叫DataFrame
df
#定义一个groupby计算
df.groupby(“皮毛”).Age.mean ()
我们看到熊猫我们急切地评估每个语句定义。DataFrame定义和groupby计算的结果都是立即返回。这是熊猫和预期行为工作时很好使用相对较小的数据集时,适合您的机器的内存。
问题在于当你DataFrame包含更多的数据比你的机器可以保存在内存中。熊猫别无选择试一试将数据加载到内存…和失败。
这就是为什么像Dask评估懒洋洋地:分布式计算库
进口dask。dataframe像弟弟#把df变成Dask dataframe
dask_df = dd.from_pandas (df, npartition = 1)#叫dataframe(没有返回的内容)
dask_df
#定义相同的groupby计算如上(没有返回结果)
dask_df.groupby(“皮毛”).Age.mean ()
Dask不返回结果当我们调用DataFrame时,或当我们定义groupby计算。它只返回一个模式或轮廓,结果。
只有当我们专门打电话.compute ()将Dask实际执行计算并返回结果。这样它可以等待寻找最优路线所需的结果,就像茂丘西奥在场景2。
#触发计算
.compute dask_df.groupby(毛皮).Age.mean () ()


懒惰的评价是允许图书馆像Dask优化大规模计算通过识别部分的计算令人尴尬的是平行的。
2。令人尴尬的是平行的
“高度平行”这个词是用来描述计算或问题,可以很容易地划分成更小的任务,每一个都可以独立运行。这意味着没有任务之间的依赖关系,它们可以以任意顺序和并行运行。这些类型的问题有时也被称为“完全平行”或“高兴地并行”。

让我们回到我们的思想实验。
我们的好朋友茂丘西奥已经加入了两位切片机也将参与一个懒惰评价cheese-finding使命。我们将设置两个不同的实验的三个米老鼠小人。
在实验1中,切达干酪块被分成三个相等的部分,每个部分是放置在一个不同的迷宫。在实验2中,整个块奶酪停留,放在一个锁着的箱子迷宫的尽头3。迷宫1和2各包含一个锁箱到下一个关键的迷宫的盒子。这意味着鼠标1需要得到关键的迷宫并将其传递给老鼠2,谁会需要做同样的鼠标3。两个实验的目的是为整个块奶酪吃。
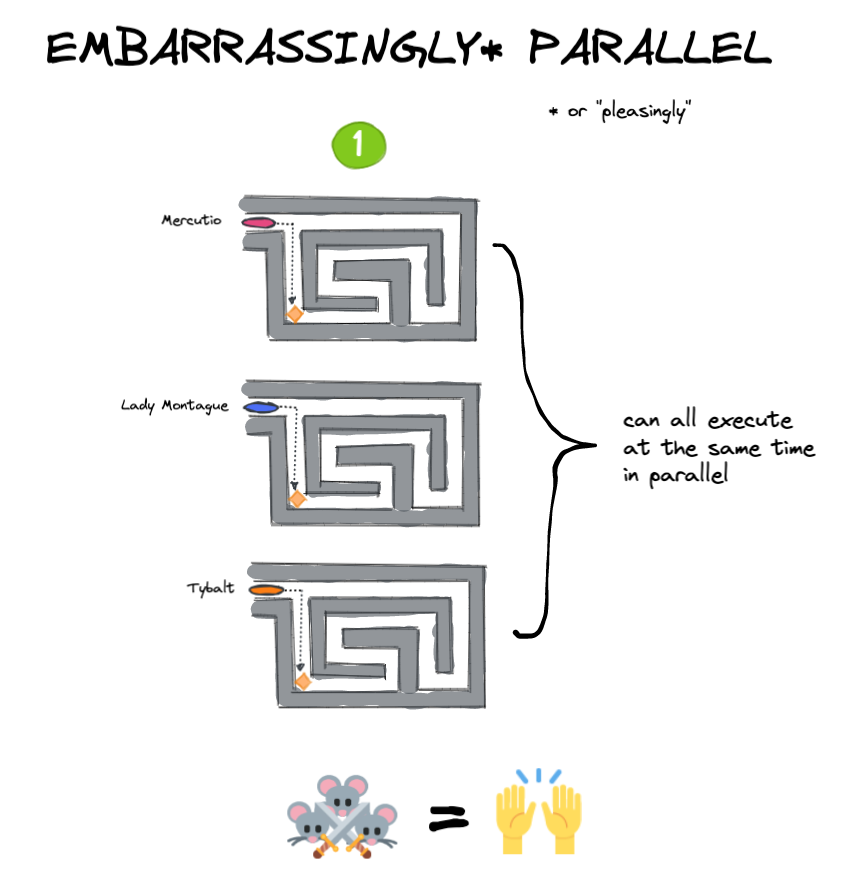
实验1(上图)的一个例子令人尴尬的是平行的米老鼠小人可以独立解决自己的问题:每一个迷宫,从而完成整个任务并行(吃奶酪的块)。
实验2(下图)是一个问题,不能由:解决每个迷宫首先取决于解决以前的迷宫。
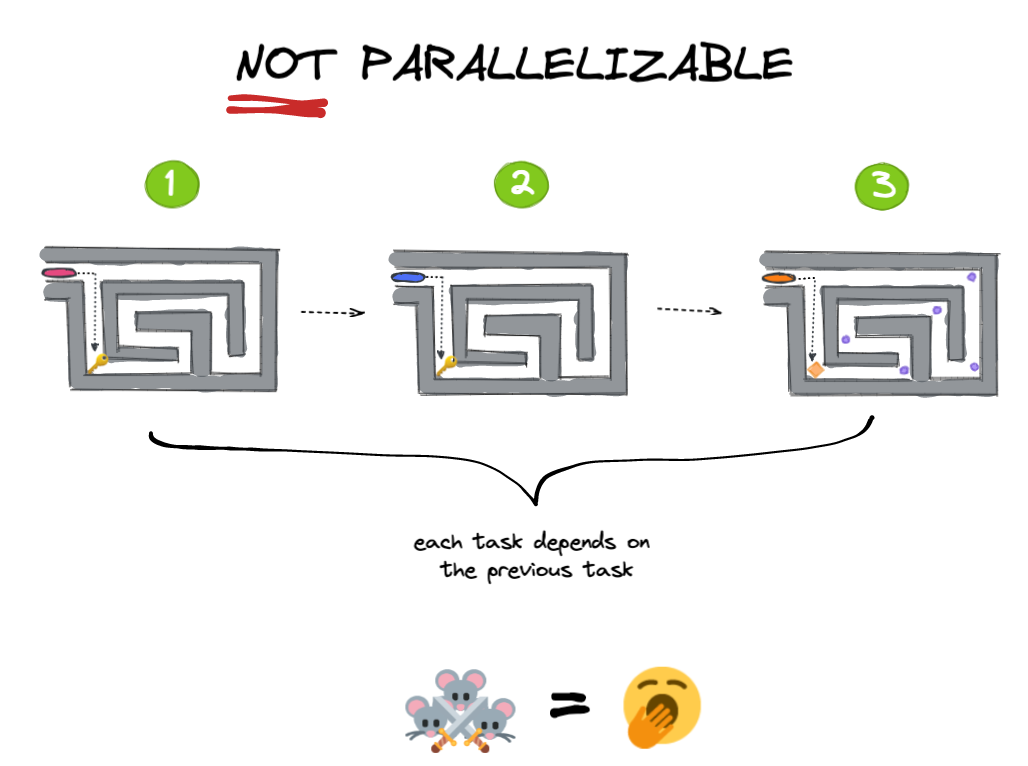
在现实中,你会遇到的问题在分布式计算将介于之间的频谱完全高度平行,不parallelisable。在大多数情况下,你的计算可以很容易地当别人不能并行运行。分布式计算库像Dask将为您解决这。
代码示例
一个简单的for循环是一个常见的例子高度平行问题:循环的每次迭代可以独立运行。蒙特卡罗模拟是一个更复杂的例子:它是一个模拟,使用重复随机抽样估计概率。每一个随机抽样独立运行,不以任何方式影响其他采样。
#一个简单的for循环是一个尴尬的并行问题因为我在范围(0,5):
x =我+ 5
打印(x)
分区铺文件读入一个Dask DataFrame的另一个例子是一个尴尬的并行问题。
df = dd.read_parquet (“test.parquet”)
df.visualize ()
比较,这里的任务图groupby计算在同一dataframedf:
这显然是不图中一个高度平行的问题:一些步骤取决于前面的步骤的结果。这并不意味着问题不能并行;Dask仍然可以并行化部分计算除以你的数据分区。
3所示。分区
一个分区一个逻辑划分,可以处理的数据独立于其他分区。分区被用在许多领域的分布式计算景观:拼花文件分为分区,以及Dask DataFrames和火花抽样。这些批次的数据有时也被称为“块”。
在上面的高度平行实验1中,我们“分区”实验的目标(块奶酪)为3独立分区,或块。每一个米老鼠小人可以做必要的工作在一个单独的分区,一起实现的总体目标吃块的奶酪。

Dask DataFrames也分为分区。每个分区在Dask DataFrame是一个独立的熊猫DataFrame可以发送到一个单独的工作要处理。
当你写一个Dask DataFrame拼花,每个分区将被写入自己的拼花分区。
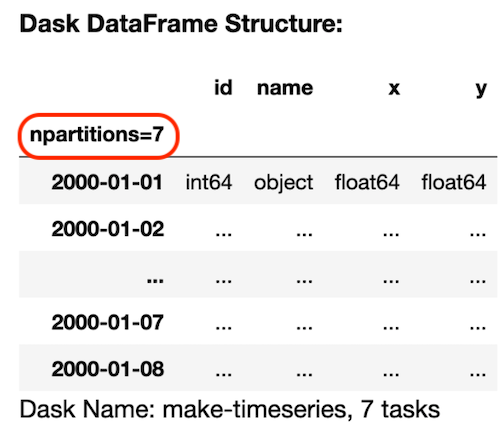
df = dask.datasets.timeseries (
“2000-01-01”,
“2000-01-08”,
频率= " 1 h”,
partition_freq = " 1 d "
)df.npartitions> > 7df

#每个dask分区写入单独的镶花分区
df.to_parquet (“test.parquet”)
并把我们一起到目前为止讨论的概念,分区铺文件加载到一个Dask DataFrame将是一个高度平行问题,因为每个拼花分区可以加载到自己的Dask DataFrame分区没有任何依赖于其他分区:
df = dd.read_parquet(“测试”)
df.visualize ()
像上面这样的任务图的创建和委托的调度器。
4所示。调度器
一个调度程序计算机过程协调的分布数据和计算数据的编制你的分布式计算系统。确保数据处理高效、安全地在多个进程同时基于可用资源和分配工作负载。

在一个简单的像parallelising尴尬的并行问题为循环,它是相对容易跟踪谁在做什么。但这将变得更加困难在处理数据集包含数百万,甚至数十亿的行数据。这机器的哪一部分数据?我们如何避免重复?如果有重复的,我们应该使用复制呢?我们如何分区的正确有意义的整体回吗?
回到茂丘西奥和他的朋友们,让我们说三个米老鼠小人每个负责准备一个独立组件的复杂的食物:洋葱煎茂丘西奥,提伯尔特光栅奶酪,蒙太古夫人蒸花椰菜。


现在想象一下,没有3但30老鼠一起工作在这个厨房和他们的活动必须精心协调和同步最好的利用可用的厨房用具。如果我们离开这个任务协调30老鼠本身,就很快被混乱:每个老鼠都忙着做自己的独立的作品能够保持清晰的了解大局和分配任务和资源以最有效的方式。老鼠将会提示使用相同的盘子,刀和那顿饭可能不会准时完成吃晚饭。
进入大厨。


大厨(又名“调度”)拥有权威的配方为这顿饭并将委派任务,并将资源分配给每个烹饪鼠标。当单个元素的餐有充分的准备,每个鼠标将返回的结果他们工作的大厨将它们合并成最终的产品。

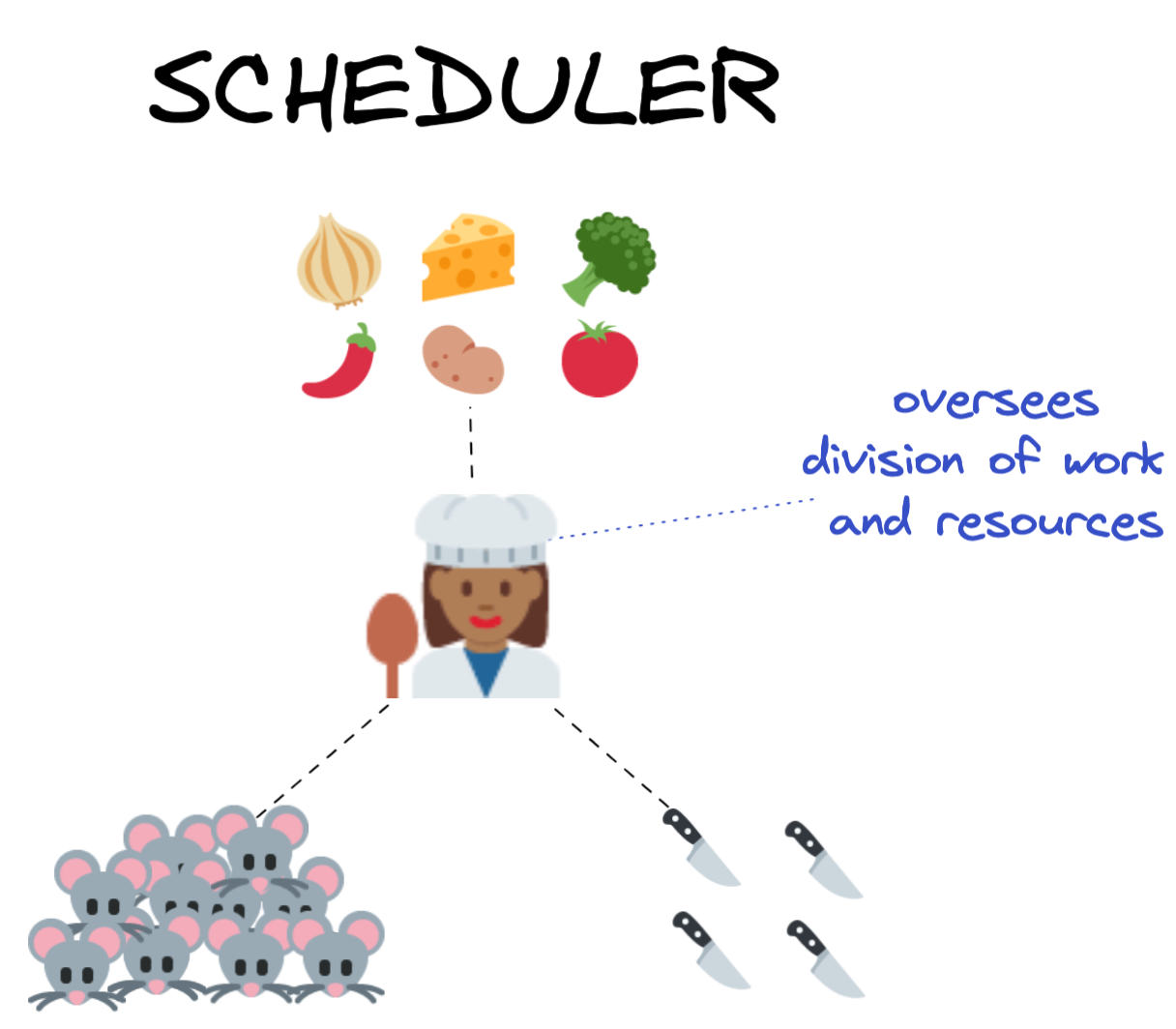
有许多不同种类的调度器,它可能是有用的学习更多有关的特定选项您计划使用分布式计算的解决方案。取决于你在本地或远程集群工作,调度程序可以在单个机器或独立的进程完全自主的计算机。
调度器是任何分布式计算的中心枢纽集群。
5。集群
集群是一群计算机或计算过程执行作为一个单元一起工作。集群形成一个分布式计算系统的核心架构。
集群有很多共同的元素,无论具体的实现或架构:一个客户,一个调度器和工人。
的客户端就是你写的代码包含了计算指令。Dask而言,它是你iPython会话或Jupyter笔记本(或者无论你正在编写和运行您的Python代码)。
的调度器是电脑的过程,协调你的分布式计算系统。在本地集群的情况下你的笔记本电脑,它仅仅是一个独立的Python的过程。对于大型超级计算机集群或远程集群在云中,调度程序往往是一个自治计算机。
的工人计算机程序做的实际工作上运行计算分区的数据。在你的笔记本电脑本地集群,每个工人是一个位于一个单独的过程你的机器的核心。在一个偏远的集群中,每个工人经常被自己的自治(虚拟)的机器。
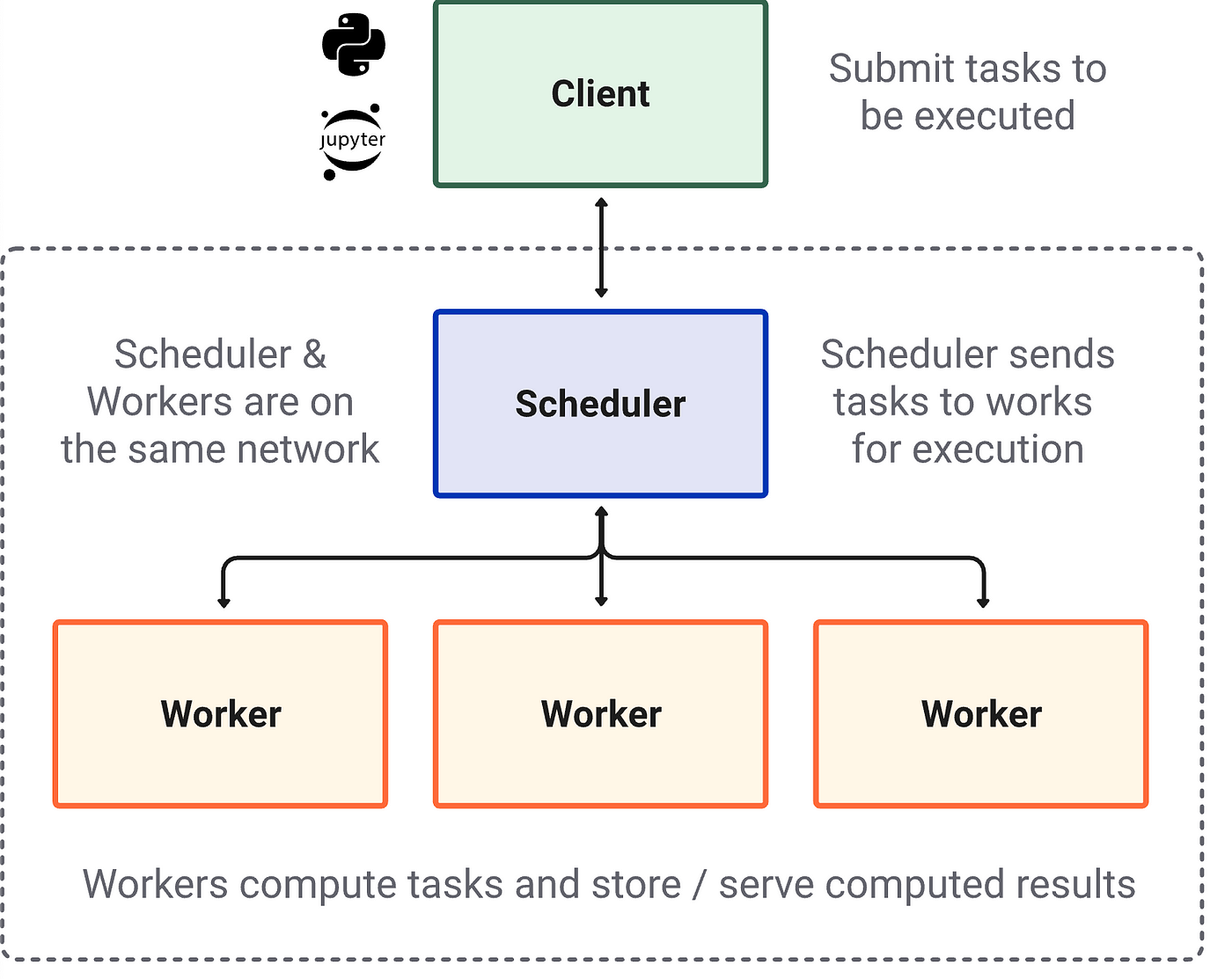
集群可以存在在本地在一台机器或远程分布在不同的服务器上(虚拟)机器或在云中。这意味着集群可以用:
- 多核在一个机器,
- 多个物理机器在相同的物理空间(高性能超级计算机),
- 多个虚拟机在物理空间(云计算集群)
6。加强和扩展
在分布式计算环境中工作时,你会经常听到人们使用术语“扩大”和“扩展”。这是指使用的区别当地的对一个远程集群。”扩大”的意思是使用更多的资源在本地。“扩展”的意思是使用更多的资源远程。

例如,过渡运行计算与熊猫(只使用一个单一的核心在你的计算机)使用当地的Dask集群的一个实例扩大。相同的工作负载从熊猫在移动远程Dask集群与盘绕就是一个例子扩展了。
#计算到云计算集群规模#推出云计算集群盘绕
进口卷
集群= coiled.Cluster (n_workers = 20)#连接Dask集群
从dask。分布式导入客户端
客户=客户(集群)#运行在远程云计算在40 gb +数据集群
地区指定基金= dd.read_parquet (
s3: / / coiled-datasets / timeseries / 20年/拼花/ '
).compute ddf.groupby(“名字”).x.mean () ()
扩大还涉及到过渡从cpu、gpu,即“硬件加速”。Dask可以使用cudf而不是熊猫DataFrame操作转移到你的gpu加速。(谢谢你雅各布·汤姆林森阐述这一点。)
7所示。并行与分布式计算
并行和分布式计算的区别执行计算的过程是否使用一个共享内存。


使用多个处理器并行计算执行任务,共享一个记忆。这个共享内存是必要的,因为单独的进程一起工作在相同的任务。并行计算系统由处理器的数量是有限的,可以连接到共享内存。
分布式计算,另一方面,执行任务使用多个自治计算机没有一个共享内存;使用消息传递计算机相互通信。这意味着一个工作单元分为单独的任务和一个中心调度器整理每个任务的结果并把最终结果返回给用户。分布式计算系统理论上是无限可扩展。
喷气背包,你走吧!
7概念提出和解释在本文中给您找到你基础的必要基础的大宇宙的分布式计算。现在是时候带喷气背包,继续探索自己。
的Dask教程对任何人来说都是个好下一步认真探索分布式计算的可能性。这是一个自学教程,你可以在1 - 2小时完成。
感谢您的阅读!在LinkedIn关注我定期更新分布式计算和软件了。
请考虑成为媒介支持写社会成员:















