分布式计算初学者指南
在Python中成功使用分布式计算的7个基本概念
进入分布式宇宙
越来越多的数据科学家正在冒险进入分布式计算的世界,以扩大他们的计算规模,更快地处理更大的数据集。但是开始分布式计算之旅会感觉有点像进入了另一个宇宙:压倒性的、令人生畏的和令人困惑的。


但这里有个好消息:您不需要了解分布式计算的所有知识就可以开始学习。
这有点像去度假o去你不会说那种语言的地方试试。在上飞机之前,要学会如何就当地错综复杂的政治制度进行完整的对话,那就太过分了。但这可能是明智的有足够的知识去四处走动并寻求帮助当你需要的时候。
这篇文章解释了开始使用分布式计算时需要的7个基本概念。尽早掌握这些基本概念可以为你节省大量的研究时间,避免日后犯昂贵的错误。这些概念将使用Python代码进行演示Dask.
让我们开始吧。
1.懒惰的评价
惰性求值是一种编程策略,将表达式或变量的求值延迟到需要它的值时。恰恰相反严格的或即时抓取其中表达式在调用时直接求值。惰性求值通过避免不必要的计算重复来增加计算的优化和减少内存负载。


让我们用一个思想实验来说明。
来见见马库修,我们的三次分布式计算鼠标管理员。


马库修要参加一个实验。这个实验的目标是让马库修找到穿过迷宫到达最终目的地的最快方法:一块美味的切达奶酪。通过迷宫的路径将通过放置面包屑来定义,以引导马丘西奥前进。这个实验的目的是为了尽快拿到奶酪,所以马库修每吃一个面包屑就会丢1分。
在场景1中,在您放置第一个面包屑后,Mercutio立即开始行走(在计算术语中为“执行”),并跟随您从一个面包屑到另一个面包屑。当然,这样他最终会到达他的目的地。他将也被扣5分,每吃一个面包屑就扣1分。这不是问题的错误解决方案,但也不是最佳方案。
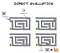
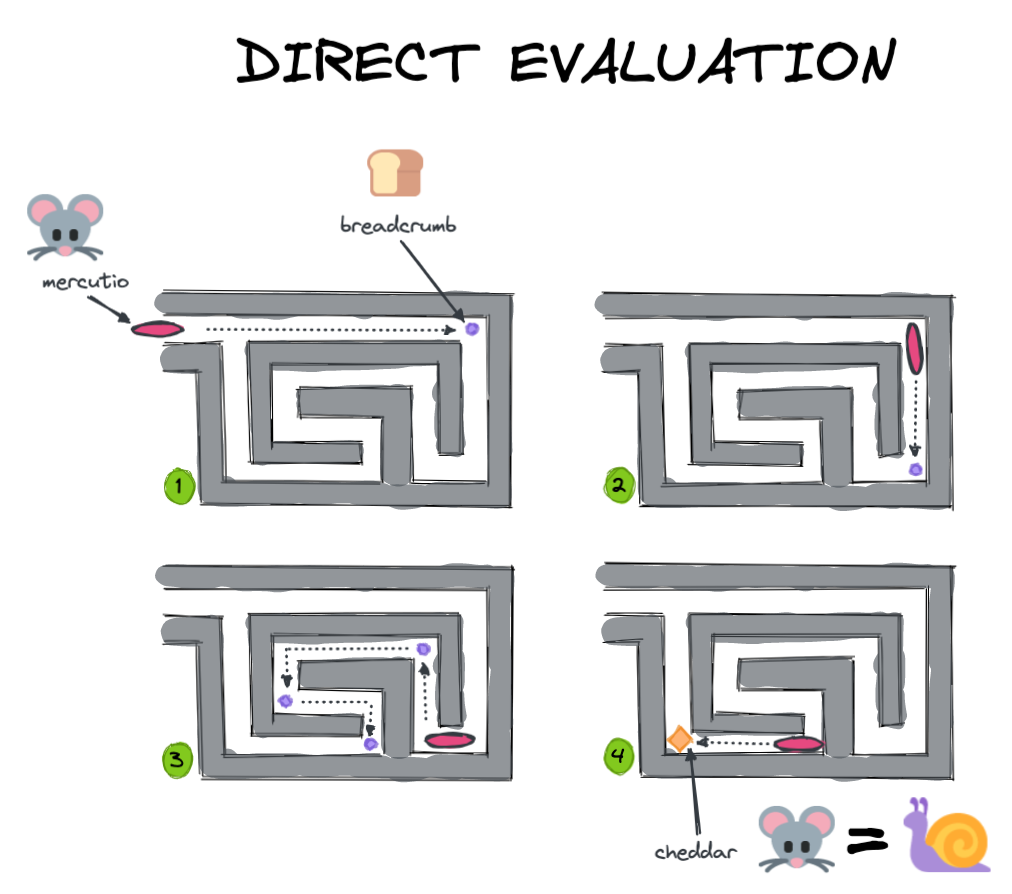
然而,如果马库修延迟他的死刑直到你放下奶酪然后评估情况,他应该能够看到整个问题并找出最快的解决方法。

两种马库修都达到了预期的效果(吃奶酪!懒惰或“延迟”计算Mercutio能够更快更有效地做到这一点.
代码示例
让我们在Python代码中使用pandas(快速求值)和Dask(惰性求值)演示一个示例。在下面的代码中,我们将创建一个DataFrame,并将其命名为DataFrame,然后在特定的列上设置一个groupby计算。注意pandas是如何立即返回结果的,而Dask只有在您明确地告诉它开始计算时才这样做。
进口熊猫作为pd#创建一个数据框架
Df = pd。DataFrame ({
“姓名”:[“马库修”,“提伯尔特”,“蒙塔古夫人”],
“年龄”:[3,2,4],
“皮毛”:[“灰色”,“灰色”,“白色”]}
)#调用数据帧
df
#根据计算量定义一个组
df.groupby(“皮毛”).Age.mean ()
我们看到熊猫热切地评价我们定义的每一个语句。DataFrame定义和groupby计算的结果都立即返回。在pandas中工作时,这是预期的行为,并且在处理相对较小的数据集(适合机器内存)时很好。
当您的DataFrame包含的数据超过您的机器在内存中可以容纳的数据时,问题就出现了。熊猫别无选择试一试将数据加载到内存中…然后失败。
这就是为什么像Dask这样的分布式计算库会懒惰地计算:
进口dask。数据帧作为dd#把df变成Dask数据框架
Dask_df = dd.from_pandas(df, npartitions=1)#调用dataframe(没有返回内容)
dask_df
#定义与上面相同的groupby计算(没有返回结果)
dask_df.groupby(“皮毛”).Age.mean ()
Dask不返回结果当我们调用DataFrame时,或者当我们通过计算定义组时。它只返回结果的模式或大纲。
只有我们特意打电话的时候.compute ()Dask将实际执行计算并返回结果。这样它就可以等待找到到达期望结果的最佳路径,就像上面场景2中的Mercutio一样。
#触发计算
.compute dask_df.groupby(毛皮).Age.mean () ()


惰性求值允许像Dask这样的库通过识别计算的部分来优化大规模计算令人尴尬的是平行的.
2.令人尴尬的是平行的
“尴尬的平行”这个词被用来描述计算或问题可以很容易地划分为较小的任务,每个任务都可以独立运行。这意味着任务之间没有依赖关系,它们可以以任何顺序并行运行。这类问题有时也被称为“完全平行”或“令人愉快的平行”。

让我们回到我们的思想实验。
我们的好朋友马库西奥和另外两个小伙伴一起参加了一个懒惰的奶酪评估任务。我们将为三个守鼠人设置两个不同的实验。
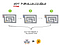
在实验1中,切达奶酪块被分成3等份,每部分都被放在不同迷宫的末端。在实验2中,奶酪块保持完整,并被放在迷宫3尽头的一个上锁的盒子里。迷宫1和2都有一个上锁的盒子,里面有打开下一个迷宫盒子的钥匙。这意味着老鼠1需要从迷宫中获取钥匙,并将其传递给老鼠2,老鼠2需要为老鼠3做同样的事情。这两个实验的目的都是要把整块奶酪吃完。
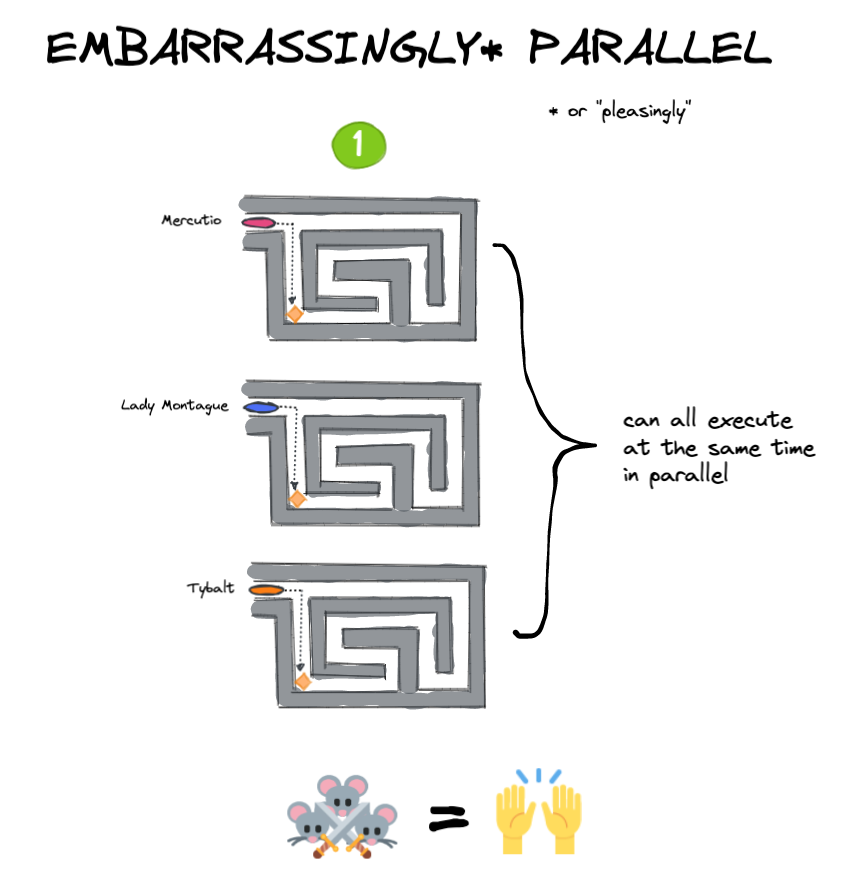
实验1(上面)是一个例子令人尴尬的是平行的问题:每个Mouseketeer都可以独立解决自己的迷宫,从而并行完成整个任务(吃奶酪块)。
实验2(下图)是一个完全不能并行的问题的例子:解决每个迷宫取决于先解决前一个迷宫。
在现实中,您将在分布式计算中遇到的问题将落在完全并行和根本不可并行之间的某个频谱上。在大多数情况下,部分计算可以很容易地并行运行,而其他部分则不能。像Dask这样的分布式计算库将为您整理这些问题。
代码示例
简单的for循环是常见的令人尴尬的并行问题的一个例子:循环的每次迭代都可以独立运行。蒙特卡罗模拟是一个更复杂的例子:它是一个使用重复随机抽样来估计概率的模拟。每个随机抽样都独立运行,不以任何方式影响其他抽样。
# a simple for循环是一个令人尴尬的并行问题对于I在(0,5)范围内:
X = I + 5
打印(x)
将分区的Parquet文件读入Dask DataFrame是另一个令人尴尬的并行问题的例子。
Df = dd.read_parquet(" test.parquet ")
df.visualize ()
为了进行比较,这里是同一个数据帧上的分组计算的任务图df:
这很明显不一个令人尴尬的并行问题:图中的某些步骤依赖于前面步骤的结果。这并不意味着这个问题根本不能并行化;Dask仍然可以并行化部分将数据分成分区。
3.分区
分区是一种数据的逻辑划分,可以独立于其他分区进行处理。分区被用于分布式计算领域的许多领域:Parquet文件被划分为分区,以及Dask dataframe和Spark rdd。这些数据批次有时也被称为“块”。
在上面令人尴尬的平行实验1中,我们将实验的目标(奶酪块)“划分”为3个独立的分区或块。然后,每个鼠友可以在单独的分区上做必要的工作,共同实现吃奶酪块的总体目标。

Dask数据框架也被划分为分区。Dask DataFrame中的每个分区都是一个独立的pandas DataFrame,可以发送给单独的worker进行处理。
当你写一个Dask数据帧到Parquet,每个分区将被写入到自己的Parquet分区。
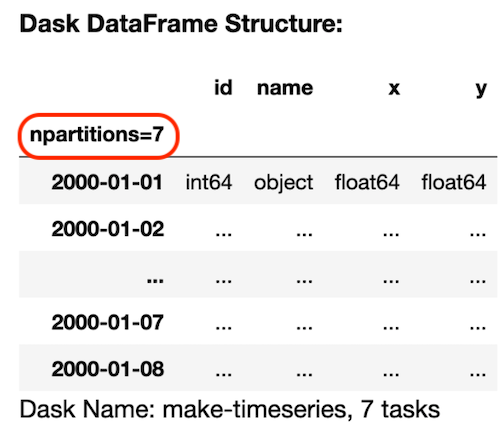
Df = dask.datasets.timeseries(
“2000-01-01”,
“2000-01-08”,
频率= " 1 h”,
partition_freq = " 1 d "
)df.npartitions> > 7df

#将每个dask分区写入单独的Parquet分区
df.to_parquet(“test.parquet”)
把我们到目前为止讨论的概念放在一起,加载一个分区的Parquet文件到Dask DataFrame将是一个尴尬的并行问题,因为每个Parquet分区可以加载到它自己的Dask DataFrame分区,而不依赖于其他分区:
Df = dd.read_parquet(" test ")
df.visualize ()
任务图(如上图所示)是由调度器。
4.调度器
调度程序是一种计算机进程,用于在分布式计算系统中编排数据的分布和对该数据的计算的编排。它确保同时跨多个进程高效安全地处理数据,并根据可用资源分配工作负载。

在一个简单的令人尴尬的并行问题中,比如并行a为循环,它相对容易跟踪谁在做什么。但是,当处理包含数百万甚至数十亿行数据的数据集时,这就变得困难得多。哪台机器有哪部分数据?我们如何避免重复?如果有副本,我们应该用哪一份?我们如何正确地将所有分区重新组合成一个有意义的整体?
让我们回到马库修和他的朋友们,假设我们的三个老鼠管家每人的任务是为一顿复杂的饭准备一个独立的组成部分:马库修煎洋葱,提伯尔特磨奶酪,蒙塔古夫人蒸西兰花。


现在想象一下,在这个厨房里一起工作的不是3只而是30只老鼠,它们的活动必须仔细协调和同步,以最大限度地利用可用的厨房用具。如果我们把这个协调的任务交给30只老鼠自己,很快就会出现混乱:每只鼠标都忙于自己独立的工作,无法清晰地了解全局,并以最有效的方式分配任务和资源。老鼠会被提示使用相同的锅和刀,这顿饭可能无法按时完成。
《厨艺大师》登场了。


Master Chef(又名“Scheduler”)掌握着一餐的权威食谱,并根据需要将任务和资源分配给每只烹饪鼠标。当食物的各个元素完全准备好后,每只老鼠将把它们的工作结果返回给主厨,由主厨将它们组合成最终产品。

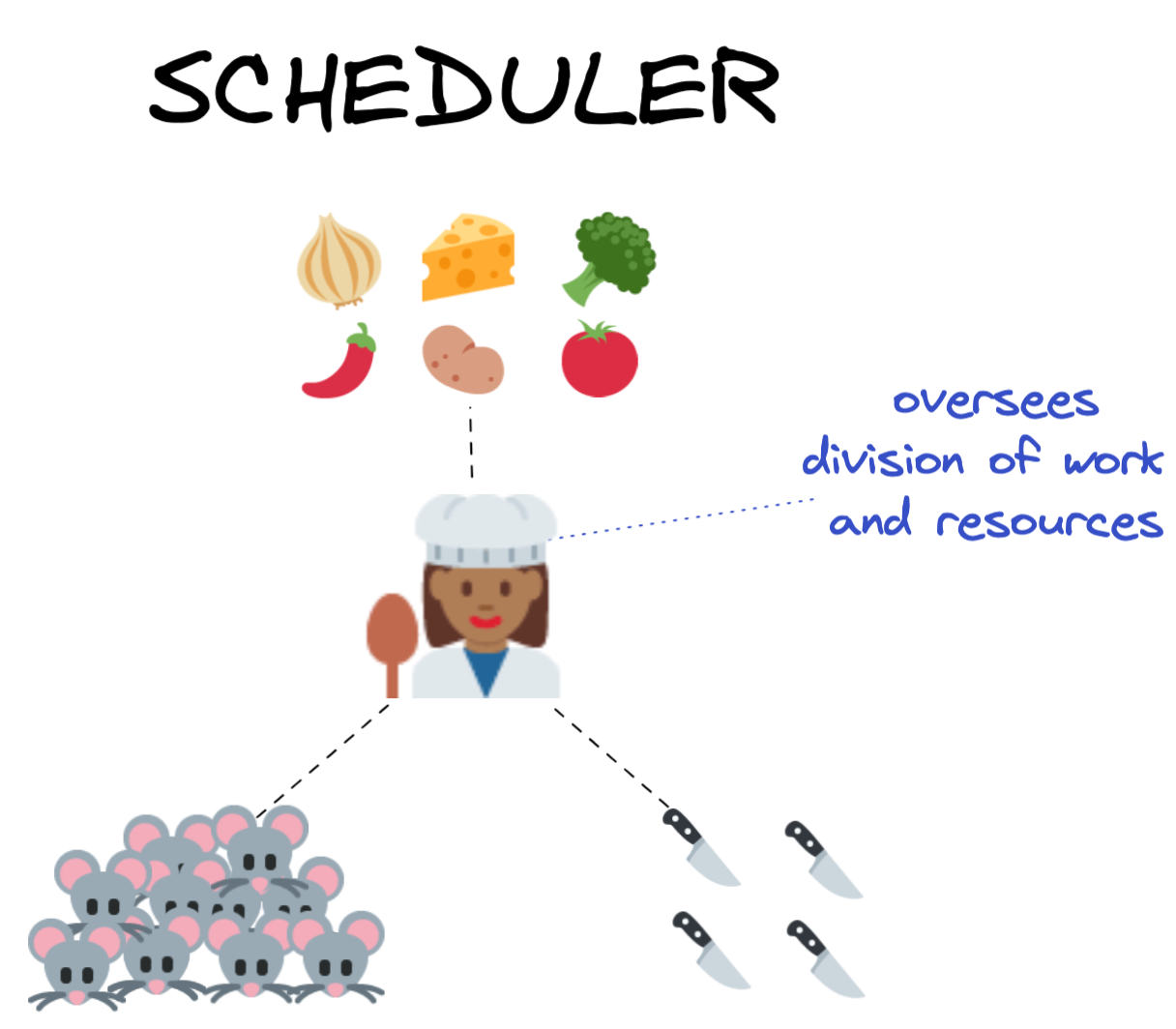
有许多不同种类的调度器,了解更多关于您计划使用的分布式计算解决方案的特定选项可能会很有用。根据您是在本地群集上还是在远程群集上工作,调度器可以是单机中的独立进程,也可以是完全自主的计算机。
调度器是任何分布式计算的中心枢纽集群.
5.集群
集群为一组计算机或计算进程,它们作为一个单独的单元一起工作以执行工作。集群构成了分布式计算系统的核心体系结构。
无论具体的实现或体系结构如何,集群都有许多共同的元素:客户机、调度器和工作者。
的客户端是您编写包含计算指令的代码的地方。在Dask的情况下,它是你的iPython会话或Jupyter Notebook(或任何你正在编写和运行Python代码的地方)。
的调度器是编排分布式计算系统的计算机进程。在笔记本上的本地集群的情况下,它只是一个单独的Python进程。在大型超级计算机集群或云中的远程集群的情况下,调度器通常是一台自主计算机。
的工人是在数据分区上执行实际计算工作的计算机进程。在笔记本电脑上的本地集群中,每个worker都是位于计算机独立核心上的一个进程。在远程集群中,每个worker通常是它自己的自治(虚拟)机器。
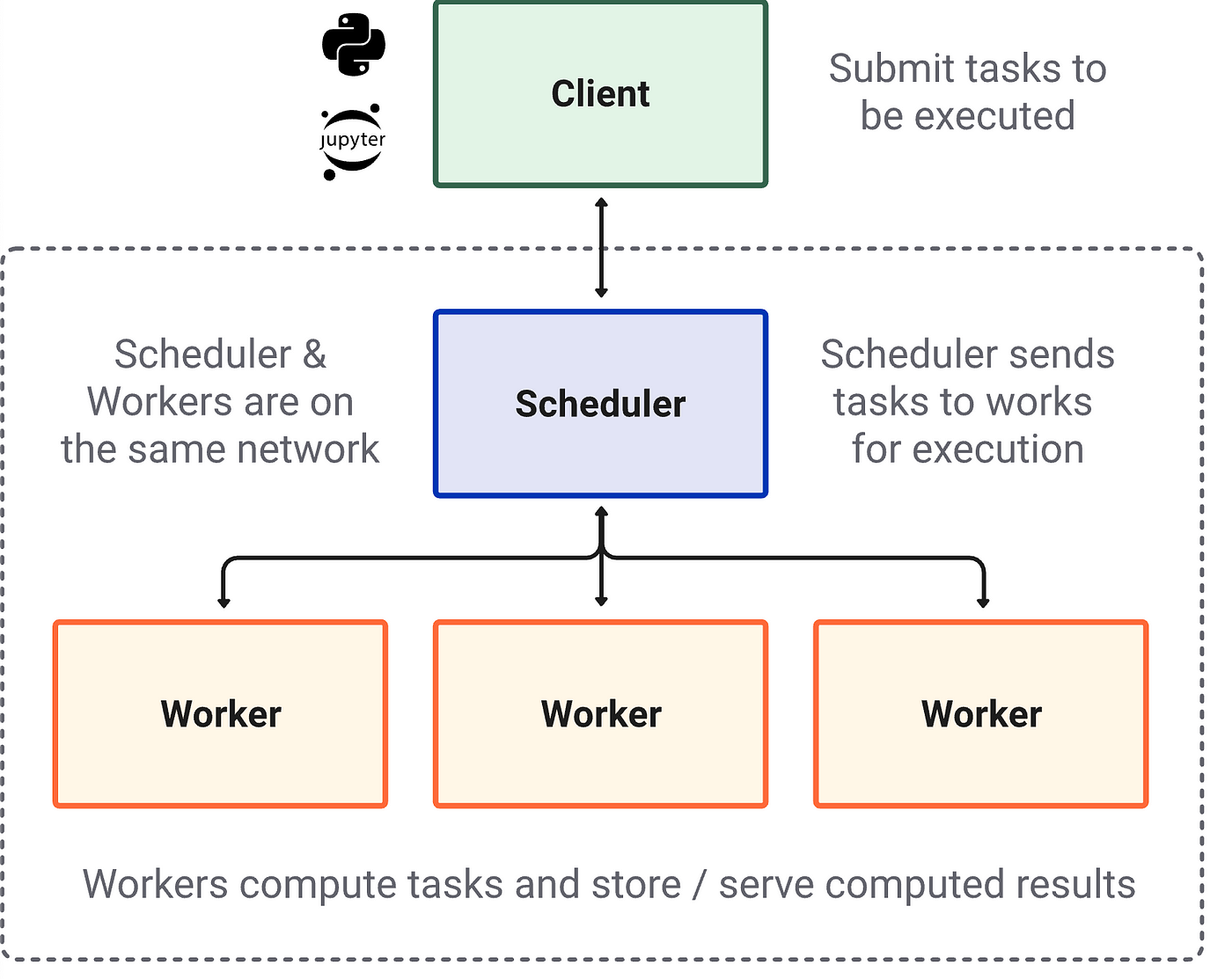
集群也可以存在在本地在一台机器内或远程分布在服务器或云中不同的(虚拟)机器上。这意味着集群可以由以下内容构建:
- 多核在一台机器,
- 多台物理机在同一个物理空间(一台高性能超级计算机),
- 多个虚拟机分布在物理空间上(云计算集群)
6.向上扩展还是向外扩展
在分布式计算环境中工作时,您经常会听到人们使用术语“向上扩展”和“向外扩展”。这是用来指使用之间的区别当地的对一个远程集群。”“扩大规模”意味着使用更多的资源在本地.“向外扩展”意味着使用更多的资源远程.

例如,从使用pandas(只在计算机中使用一个核心)运行计算过渡到使用a当地的Dask集群的一个实例扩大.将相同的工作负载从熊猫转移到a远程Dask集群与盘绕是一个例子扩展了.
#扩展计算到一个云集群使用Coiled启动云集群
进口卷
cluster (n_workers=20)#连接集群到Dask
从dask。分布式导入客户端
客户端=客户端(集群)在远程云集群上运行40GB以上的数据
DDF = dd.read_parquet(
s3: / / coiled-datasets / timeseries / 20年/拼花/ '
).compute ddf.groupby(“名字”).x.mean () ()
扩大还包括从cpu到gpu的转换,即“硬件加速”。Dask可以使用cudf而不是熊猫将你的DataFrame操作转移到你的gpu上进行大规模的加速。(谢谢你雅各布·汤姆林森对于这一点的阐述。)
7.并行计算与分布式计算
并行计算和分布式计算的区别在于执行计算的进程是否使用单个共享内存。


并行计算使用共享单个内存的多个处理器执行任务。这种共享内存是必要的,因为不同的进程一起执行相同的任务。并行计算系统受到可以连接到共享内存的处理器数量的限制。
另一方面,分布式计算使用多个自主计算机执行任务,而没有单个共享内存;计算机之间使用消息传递进行通信。这意味着一个工作单元被划分为独立的任务,中央调度器会整理每个任务的结果,并将最终结果返回给用户。分布式计算系统理论上是无限可扩展的。
JetPack On and Off You Go!
本文中介绍和解释的7个概念为您在分布式计算的大宇宙中找到立足点奠定了必要的基础。现在是时候带上喷气背包,继续自己探索了。
的Dask教程对于任何认真探索分布式计算可能性的人来说,都是一个很好的下一步。这是一个自定节奏的教程,你可以在1-2小时内完成。
感谢您的阅读!在领英上关注我用于定期的分布式计算更新和黑客。
请考虑成为媒体的一员,以支持写作社区:















