为什么阵列作为一个通用数据模型
对数据管理的应许之地

这些都是激动人心的时刻对于任何数据问题,作为数据行业一样热hyp一如既往。湖泊众多的数据库、数据仓库、数据,lakehouses、特色商店、元数据存储、文件管理等已经触及市场在过去的几年中。我花了我的整个职业生涯数据管理,但与市场趋势,我一直非常困惑,我们继续创建一个新的数据系统为每一个不同的数据类型和应用。英特尔实验室和麻省理工学院的时候,在2014 - 2017年我在那儿当数据库研究员,我问自己一个简单的问题:,而不是建立一个新的数据系统每次我们的数据需求发生变化,我们可以建立一个单一的数据库可以存储,管理,和处理所有数据,表格,图片,视频,基因组学、激光雷达、特性、元数据、平面文件和任何其他数据类型可能在未来出现。
这个问题出生从简单的观察,所有数据库系统(变化)分享重要的相似之处,包括铺设数据的存储介质的选择,和打它处理基于特定的查询工作负载。因此,要回答上面的问题,我不得不问一个稍微不同的问题:有一个数据模型,能够有效地捕获所有数据从所有应用程序?因为如果存在这样一个通用数据模型,它可以作为构建一个通用数据库的基础与所有子系统常见数据库(查询规划师、遗嘱执行人身份,事务管理器,api,等等)。在这篇文章里我认为确实存在这样一个模型,它是基于多维数组。
在阐述为什么数组是普遍之前,我需要回答另一个问题:你为什么要关心一个通用数据模型和通用数据库?这里有几个重要的原因:
- 数据的多样性。你可能认为这是关于表格数据的传统数据仓库(或数据湖,或lakehouse)可以达到同样的效果,但在现实中组织拥有大量的其他非常有价值的数据,如图像、视频、音频、基因组学、点云,平面文件和更多。和他们希望执行各种操作这些数据收集,数据分析,科学和机器学习。
- 供应商优化。为了能够管理他们的不同数据,组织采取购买很多不同的数据系统,例如,一个数据仓库,加上一个毫升的平台,加上一个元数据存储,加上一个文件管理器。金钱和时间成本;钱因为一些供应商的重叠功能,你支付两次(如身份验证、访问控制等),和因为团队必须学会经营许多不同的系统,和争论数据时需要获得的见解通过结合不同的数据源。
- 全面的治理。即使组织与许多供应商都是快乐的,每个不同的数据系统都有自己的访问控制和日志记录功能。因此,如果一个组织需要实施集中治理所有的数据,它需要建立内部。花费更多的钱和时间。
即使我已经设法说服你的通用数据库的重要性,我要最后一个至关重要的评论。通用数据库不可用,如果不提供性能优良服务的所有数据类型。换句话说,一个通用数据库必须执行高效专用的,否则会有很多怀疑采用。这是通用数据库的困难所在,为什么今天没有人建立这样一个系统(好吧,几乎没有人)。
在这个博客我表明,多维数组是正确的选择不仅对他们的普遍性,但也为他们的性能。在充分披露,我的创始人和首席执行官TileDB公司正在建设一个通用数据库和多维数组作为一等公民。我将包括很多重要决定时我们在TileDB数组数据模型,设计一个高效的磁盘格式和一个强大的存储引擎来支持它。我的目标是强调通用阵列原则,希望这篇文章可以作为一个小一步从专用数据系统转向开发更多通用的数据库。
深呼吸,我们是要一个技术潜水!
其余的博客是你的:
- 您使用一个数据类型(表、基因组学、激光雷达、成像等)和潜在使用专用数据系统,但你想深入了解多维数组可以提供一个优雅的和更多的高性能解决方案为您的用例。
- 您使用不同的数据,还可以从许多别的来源使用现代本机工具,和想了解的技术设计选择使多维数组和适应任何数据集或负载能力通过一个通用格式,引擎和接口。
- 重要的是你理解的基础工具使用和比较,探索,需要确定他们精心设计的现在和将来来满足您的需求。
数组的数据模型
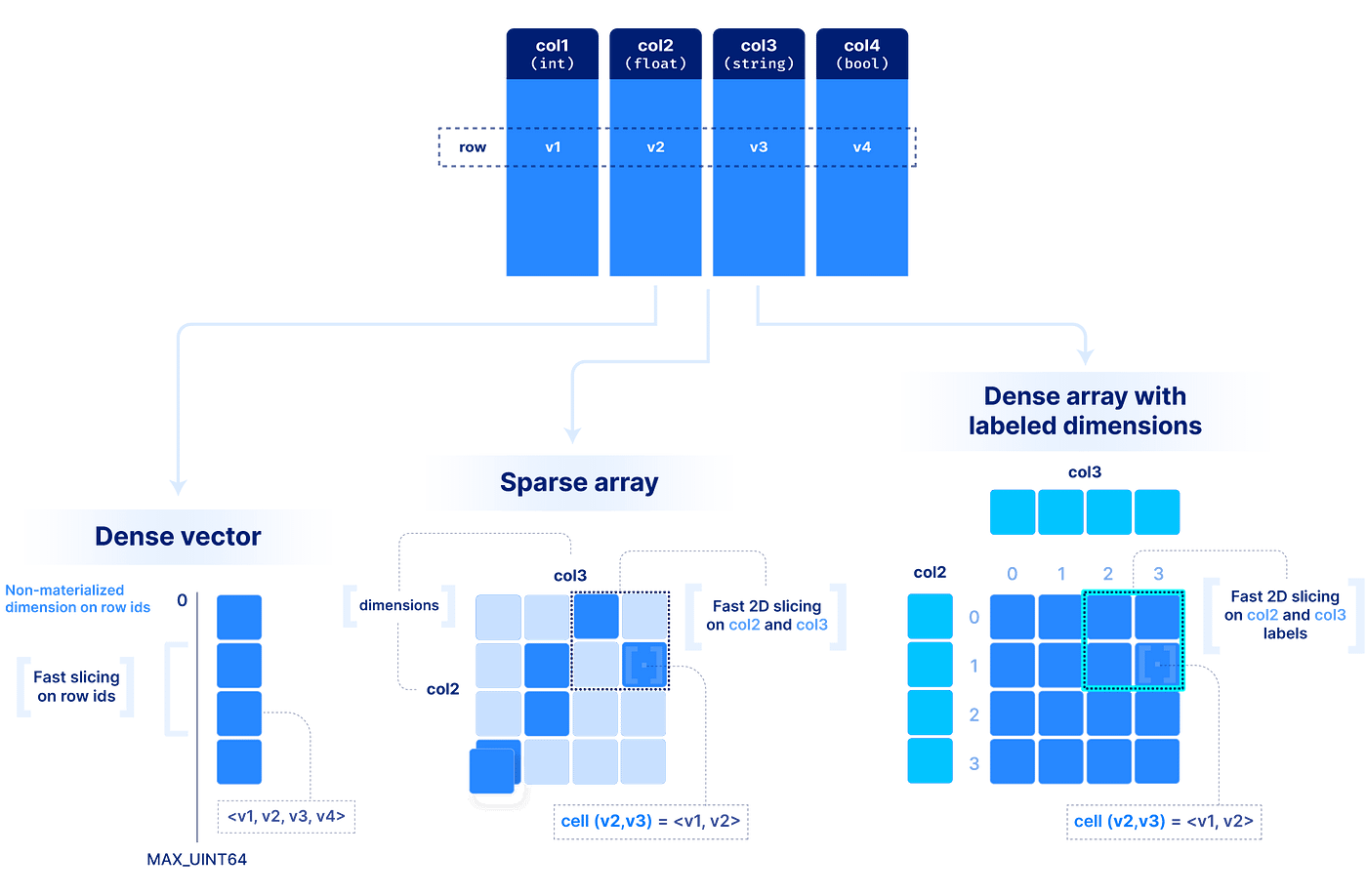
我们遵循TileDB基本数组模型如下图所示。我们做一个重要的区别密集的和一个稀疏的数组中。密集的数组可以拥有任意数量的维度。每个维度与整数值必须有一个域,和所有维度具有相同的数据类型。数组元素是由一组独特的维度定义的坐标,它被称为细胞。在一个密集的数组,所有的细胞都必须存储一个值。一个逻辑单元可以存储多个值可能不同类型(可整数、浮点数、字符串等)。定义了一个属性值具有相同类型的集合在所有细胞。密集阵列可能与一组任意键-值对,称为数组的元数据。


稀疏阵列密度非常类似于数组,但它有三个重要的区别:
- 细胞稀疏阵列可以是空的。
- 尺寸可以有异构类型,包括浮点数和字符串(即。域可以“无限”)。
- (即细胞多样性。,细胞具有相同维度坐标)是允许的。
决定是否模型数据的稠密或稀疏阵列取决于应用程序,它可以极大地影响性能。还额外应该小心当选择模型数据字段作为一个维度或一个属性。这些决定在下面的性能部分详细介绍,但是现在,你应该知道:阵列系统优化的快速执行范围的条件在维坐标。数组也可以支持高效的条件属性,而是通过设计大多数优化选择性能将来自查询维度,原因很快就会变得清晰。
范围条件维度通常被称为“切片”和结果构成“片”或“子数组”。一些例子如下图所示。在numpy符号,(0:2,1:3)是一片,由细胞与坐标0和1的值在第一维度,并协调1和2在第二个维度(假设一个属性)。另外,这可以用SQL编写选择attr从d1 > = 0和d1 < = 1和d2 > = 1和d2 < = 2,在那里attr是一个属性,d1和d2的二维数组一个。还要注意切片可以包含一个以上的范围/维度(多量程片/子数组)。


上述模型可以扩展到包括“维度标签”。这个扩展可以应用于密集和稀疏阵列,但标签在密集阵列尤其有用。简要地说,一个维度可以接受一个标签向量映射值任意数据类型的整数维坐标。下面展示了一个例子。这是非常强大的应用程序中,数据相当密集(即。,没有太多空细胞),但维度字段不是整数或不出现连续的整数域。在这种情况下,多维切片是由第一有效查找标签的整数坐标向量,然后应用如上所述的切片。为什么这可能是比简单的建模数据稀疏阵列将在下面的性能部分变得清晰。


用例被多维数组
多维数组已经存在了很长一段时间。然而,有两个误解数组:
- 数组是仅仅在科学应用程序使用。这主要是由于他们的大规模使用在Python中,Matlab, R,机器学习和其他科学应用。是绝对没有错的阵列捕捉科学的用例。相反,这样的应用程序是很重要的和具有挑战性的,毫无关系数据库,可以有效地容纳它们(原因很快就会变得清晰)。
- 数组只是密集。大多数阵列系统(即。存储引擎或数据库)之前TileDB集中密集的数组。尽管他们是否适合广泛的用例,密集的数组是稀疏问题的不足,如基因组学、激光雷达和表。稀疏阵列被忽视了,因此没有阵列系统能够声称普遍性。
没有限制的适用性系统,支持稠密和稀疏阵列。密度图像是一个二维数组,其中每个细胞是一个像素,可以存储RGBA颜色值。同样一个视频是一个3 d密集阵列,两个维度为帧图像和第三个时间。激光雷达是一种三维稀疏阵列与浮动坐标。基因组变异可以通过3 d建模数组的尺寸样品名称(字符串),染色体(字符串)和位置(整数)。时间序列蜱虫可以建模数据由一个二维数组,随着时间的推移和蜱虫象征标示尺寸(这当然可以扩展任意ND稠密或稀疏阵列)。同样,天气数据可以建模与2 d密集阵列浮动标签(真正纬度/经度坐标)。图表可以建模为邻接矩阵(稀疏的2 d)。最后,一个平面文件可以存储密度作为一个简单的一维数组,每个单元存储一个字节。


但表格数据呢?数组有很大的灵活性。在最做作的场景中,我们可以将一个表存储为一组1 d数组,每列(类似于一个拼花对于那些熟悉)。这是有用的,如果我们想要片一系列行。或者,我们可以将一个表存储为一个ND稀疏阵列,使用列的一个子集作为维度。允许快速切片维列上。最后,我们可以使用标签密集阵列如前所述的蜱虫方面的时间序列数据。

你可能想知道我们如何做出这些决定维度和属性和密集和稀疏的为每个应用程序。为了回答这个问题,我们需要了解密集和稀疏阵列数据存储介质,切片时,哪些因素影响性能,这是下一节的重点。
为什么阵列性能数据管理
在系统性能的第一步建立在上面的数组模型计算出磁盘格式。支配着IO成本通常占主导地位的查询工作负载。我将首先解释一些我们带的架构决策TileDB嵌入式建立一个高效的数组的格式。我将解释这种格式导致高效切片操作和总结所有的性能因素。
磁盘格式
让我们先从我们如何存储维度坐标和属性值。为了有效地支持云对象商店和版本写道,我们选择一个多文件格式,以及每个维度或属性值存储在一个单独的文件中。密集阵不实现维度坐标,而稀疏阵列必须。下图显示了一个密集和稀疏阵列的例子。观察到每个单元格值在所有维度和属性出现在相同的绝对位置在对应的文件。此外,在变长属性或维度,一个单独的文件需要存储字节偏移量的值文件中的每个值开始的地方。


这个布局相同类型的值被组合在一起是理想的压缩、向量化,构造子集在属性/维度查询(类似于其他柱状数据库)。因为典型的查询片这些值的子集,我们不压缩整个文件作为一个blob。相反,我们瓷砖(即。成更小的块,块)。因此,我们需要一种机制来创建组织的细胞。每个瓷砖的细胞会出现连续的在相应的文件,如上图所示。瓷砖是IO和压缩的原子单元,(以及其他潜在的过滤器,如加密、校验和,等等)。
一个问题出现了:我们如何从一个多维空间的值,在一维的文件。此订单将决定每个单元格的位置在其相应的瓷砖,瓷砖在文件的位置。我们称之为命令全球秩序细胞的数组。我将解释全球秩序和瓷砖单独密集和稀疏阵列。
密集阵,全球秩序和瓷砖是由三个参数:
- 每个维度空间瓷砖程度。
- 细胞在每个瓷砖
- 瓷砖的顺序
下图描述了三个不同的订单我们改变上述参数。观察到的形状和大小完全由空间决定每个瓷砖瓷砖区段。


稀疏阵列的情况略有不同,因为瓷砖只基于空间瓷砖可能导致非空细胞的高度不平衡数字在每个瓷砖,可以进一步压缩和切片性能的影响。在稀疏阵列,全球秩序可以确定如下:
- 通过指定相同的三个参数在密集的情况下,或
- 通过使用一个希尔伯特空间曲线
一旦确定了全球秩序,瓷砖是指定一个额外的参数,称为瓷砖的能力,即在每个瓷砖,非空细胞的数量。下图描述了不同的全球订单所有上述参数的不同选择稀疏阵列(一个非空单元描述了深蓝色)。
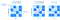

为什么全球秩序和瓷砖大不了吗?全球秩序应尽可能保留co-locality你的查询结果,对于大多数典型的切片形状。记住,数组是多方面的,而文件存储一维数组数据。你有一个机会(除非你想支付冗余),您的数据在一个1 d秩序。这完全决定你的多维查询的性能。原因是您的研究结果发表在《文件越近,越快的IO操作来检索它们。瓷砖的大小也会影响性能,因为瓷砖将从存储到内存中获取积分。下面的例子演示了一些好的和坏的全球订单和瓷砖对于给定的切片,专注于一个密集的数组(类似参数可以为稀疏的情况下)。
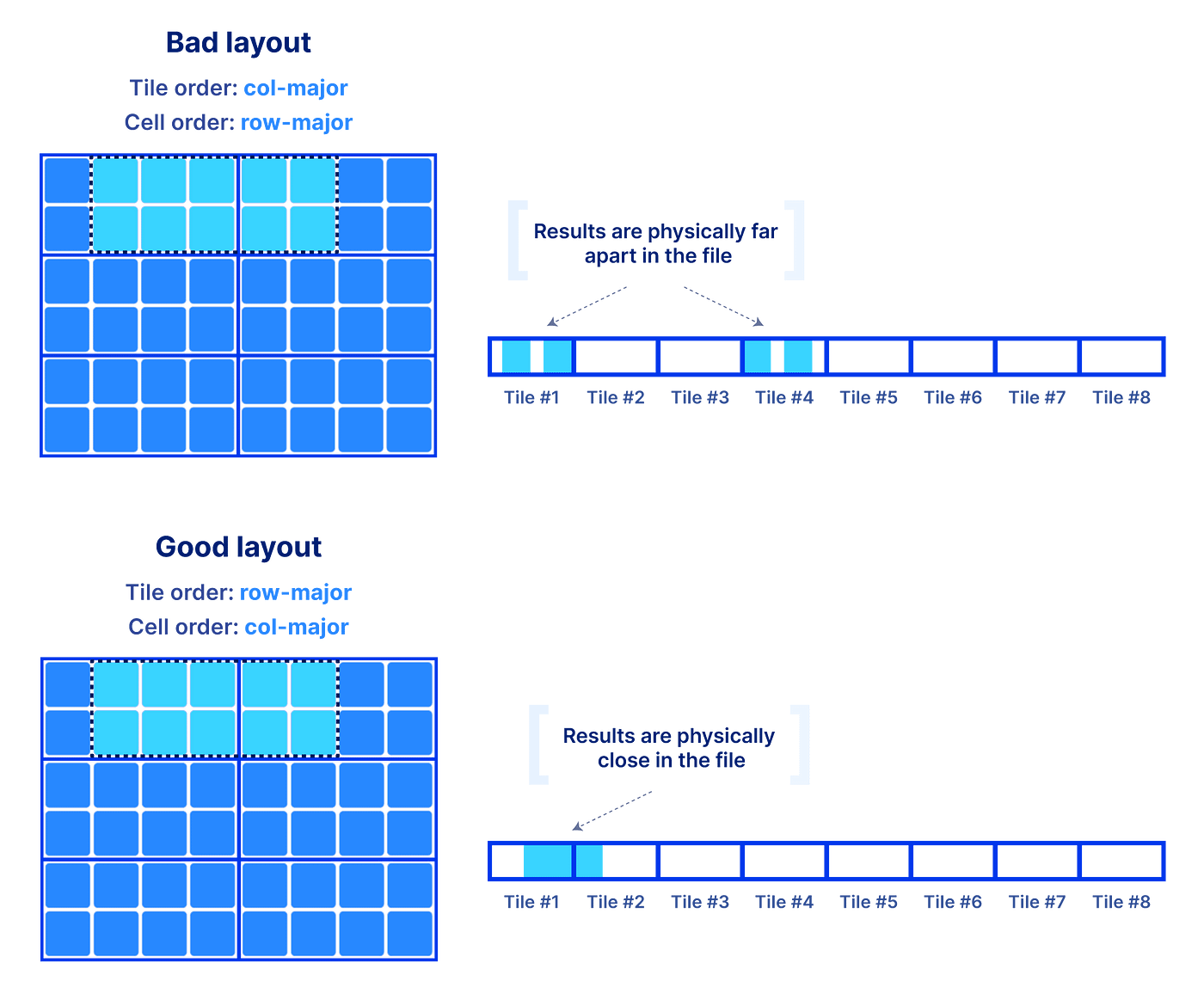
敏锐的你会说,“我需要知道我的片的形状来选择全球秩序”。在很多应用程序中,我们一直在努力,典型的查询模式确实是已知的。如果不是,数组仍然给你机会来定义一个订单导致可接受的性能大多数你的查询模式。最重要的这里是数组为您提供简单和灵活的手段操纵你的磁盘上表示数据以达到理想的性能,对所有类型的数据和应用程序。数组是普遍的原因是这样的吗?
访问数组索引和数据
现在我们发现磁盘上的格式,我们如何有效地片数组,我们选择什么指标构建促进查询?首先,我们专注于一个密集的数组和使用下图中的示例。除了切片查询,我们知道以下几点:维度的数量,全球秩序,瓷砖,事实没有空的细胞数组。这个信息是统称为数组模式。使用数组完全模式和简单的算术,我们可以计算数量,大小和位置细胞板(即。组连续的细胞在磁盘上),包括查询结果,没有任何额外的索引。因此,我们可以设计一个高效的多线程算法可以从磁盘获取相关的瓷砖,解压,并将细胞板复制到结果缓冲区,在平行的。如果适当算法开发和全球秩序和明智地选择瓷砖,切片密集阵列是真正快速!


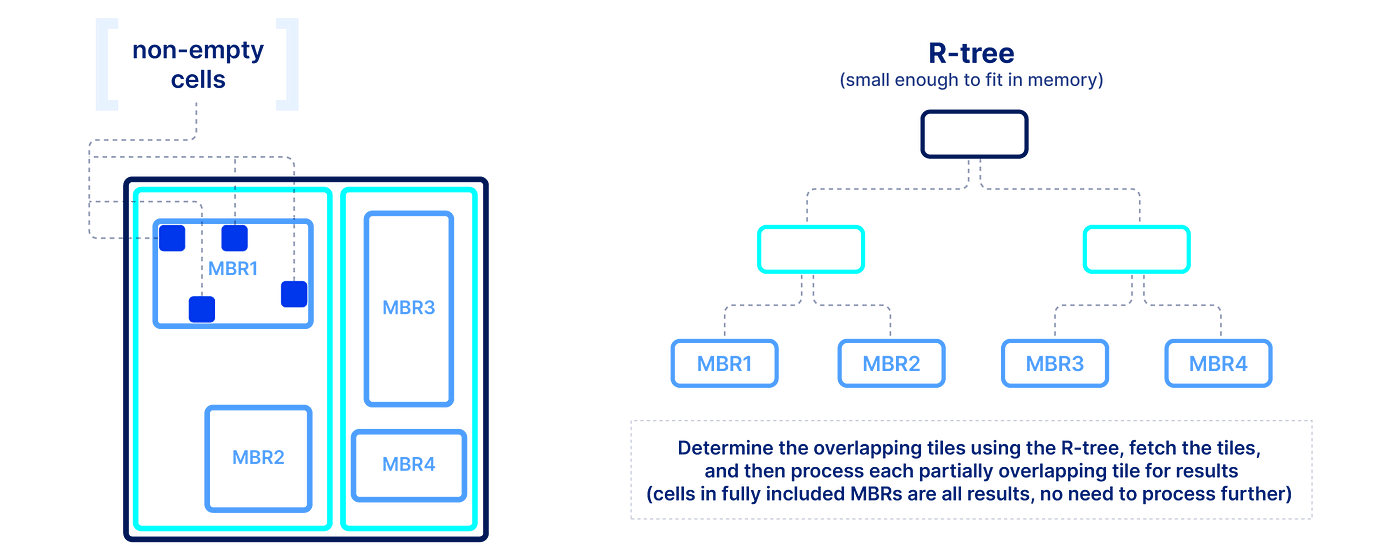
切片在稀疏阵列更困难,因为我们不知道空的细胞到数组的位置。因此,与密集的数组,我们需要显式地存储的坐标非空细胞,并建立索引上。索引必须小,以便它可以快速查询提交时加载到内存中。在TileDB我们使用一个r - tree索引,但其他多维索引存在。r - tree组的坐标非空细胞最小边界矩形(mbr),每瓦,然后递归地组织这些mbr,成一个树状结构。下图显示了一个示例。然后切片算法遍历的r - tree找到重叠瓷砖mbr,查询,获取这些瓷砖从存储并行,并解压缩。然后每部分重叠的瓷砖,算法需要进一步检查坐标来确定他们是否落在一个接一个查询部分。这个简单的算法,如果开发有效(使用多线程和向量化),会导致非常有效的多维切片。

摘要对性能
我已经提到的某些方面数组格式如何影响性能,但是下面我总结:
- 维度和属性。数据字段应该被建模为一个维度如果大多数查询工作负载(即有一系列条件。、切片)。否则,它应该被建模为一个属性。
- 数量的维度。随着维数的增加,你的经验收益递减。你应该选择4 - 5维度是高度选择性(即为您查询。修剪,也有很高的权力)。这个数字是经验和为每个应用程序不同。
- 全球秩序。全球秩序决定细胞的位置查询和可以极大地影响总成本。
- 瓷砖的大小。如果查询块瓦片太小,太大,很多冗余数据从存储、获取解压,和加工,因此性能降低。相反,如果片太大但瓷砖太小,额外的开销发生处理众多的瓷砖。
- 密集和稀疏。如果数组中所有的细胞都必须有一个值,这个数组应该密集。如果是空的,绝大多数细胞数组应该是稀疏的。如果数组相当密集,但维坐标值从一个非整数域或不连续的整数,那么数组应该的标签尺寸。
最后的话,应该清楚数组表格数据可以有效地模型,但不是亦然,这将进一步证明为什么关系数据库(或表格格式像拼花)从来没有发现在科学领域取得成功。比如一个简单的2 x2密集的数组[[1、2],[3,4]]。回想一下,密集阵列不实现细胞的坐标,而推断结果所在地模式(即从数组中。维度,全球秩序和花砖)。数组中引擎,将序列化为数组值1、2、3、4在文件(假设没有瓷砖区段和行细胞顺序),和数组在细胞能够定位价值(1,0),即第二行,第一列,像3。然而,没有表格格式的维数的概念。如果一个表格格式存储在一个列的数组值1、2、3、4,它将没有必要的信息,第一两个值对应于第一行,第二个2本示例的第二行。因此,就没有办法定位单元格的值(1,0)明确,除非我们创建了两个额外的列存储每个值的坐标和扫描表,这将带来了相当大的不必要的成本。如果你发现这个例子简单,试着想象它多么复杂的多个维度,瓷砖和不同的瓷砖和细胞的订单。
建立存储引擎,而不是格式
到目前为止,我们已经设计了一个巨大的数据模型和一个关联的磁盘格式可能导致性能优良,但我们要从这里去哪里?回答之前,我要指出一些陷阱,我们观察到与其他阵列系统:
- 专注于茂密的数组。其他三大阵列系统我们知道,SciDB, HDF5 Zarr,集中密集的数组。正如上面提到的,密集的数组有广泛的应用,但不能支持用例与稀疏数据,如激光雷达、基因组学、表和更多。
- 建立一个语言。例如,Zarr始建于Python,因此它不能使用从其他语言。这限制了其可用性。其他Zarr实现新兴,但工程造价平价非常高。
- 建立有限的后端。例如,HDF5是建立在单个文件格式的想法。这是一个很好的选择为HPC环境和分布式文件系统和光泽,但它不工作对云存储的所有文件/对象是不可变的对象。对象存储构成其他约束延迟,需要考虑读算法的高效的IO。
- 关注规范的格式。没有错,数组定义和披露格式规范。格式规范的最大问题是实现负担留给了更高级别的应用程序(例如,MariaDB等SQL引擎,或计算框架如火花)。这又带来了两个问题:(1)有很多轮的改造建设的存储层解析和处理格式,和(2)不同的社区需要同意发展规范的格式,因为改变将导致所有应用程序使用它来休息。
我认为数据模型和格式规范是不够的。我们需要关注建设一个强大的存储引擎来支持和发展数组数据模型和格式,使用以下设计原则(我们随后在TileDB嵌入式):
- 对稠密和稀疏阵列的支持,这样我们就可以达到普遍性。
- 建在c++的性能,但是包裹在众多api (C, c++, c#, Python, R, Java, Javascript)为更广泛的采用。这些api也可以促进与SQL引擎的集成,计算框架、机器学习库和其他特定于域的工具。
- 优化后端(基于posix HDFS, S3, GCS, Azure Blob存储、MinIO,甚至RAM),通过抽象IO层内的存储引擎,并且使其扩展。
- 专注于存储引擎,而不是规范的格式。更高层次应用应结合存储引擎和使用它的api。他们应该完全无视底层格式规范。这将允许存储引擎迅速发展和完善格式,没有打破更高层次的应用。
上面的只是“基本”功能存储引擎。为了构建一个通用的基础数据库,还需要一些更高级的功能:
- 版本控制和时间旅行,这对于任何数据库系统是至关重要的。
- 计算下推,如条件属性和group by聚合等更复杂的查询。这可以消除不必要的数据复制和运动。
主要结论是多维数组可以支持的强大如果正确的存储引擎。和建立一系列精心设计引擎是相当的任务。幸运的是,今天有这样一个引擎,称为TileDB嵌入式麻省理工学院的许可下,它是开源的。我希望它的设计原则将激励新数组引擎出现。
结论
在这个博客我提出,多维数组是一个功能强大的数据模型,可以作为一个通用的基础数据库,可以捕获所有的数据类型和应用程序。我解释了普遍性的好处和数组数据模型。然后我描述一个有效的磁盘阵列格式和阐述了为什么它会导致通过技术深入的性能优良。最后,我认为数组模型和磁盘格式不够,没有建立一个强大的存储引擎来支持和发展。
我总是期待着社区的反馈。你能找到我和我的团队在TileDB松弛的工作区和论坛,或者你可以联系我们直接。为进一步阅读,我建议的TileDB文档和下面的博客/在线研讨会:
一个巨大的感谢整个TileDB团队让这一切成为可能!











