神经网络
深前馈神经网络和ReLU激活函数的优点

介绍
我们,作为数据科学家,总是感到兴奋的任何性能提升我们可以实现模型。追逐这些改进推动社区继续试验,往往突破。
许多早期的实验侧重于网络的深度和如何使他们更有效率,让他们产生更精确的结果。
在这篇文章中,我将带你通过the的结构深前馈神经网络(DFF)。也,我将仔细看看ReLU(修正线性单元)激活函数并向您展示如何构建一个DFF神经网络在Python中使用Tensorflow和Keras库。
这篇文章是我的延续前一个前馈神经网络。如果你不熟悉神经网络基本知识,你可能会想读第一个:
内容
- 深前馈神经网络的机器学习在宇宙中的位置
- 前馈的区别(FF)和深前馈神经网络(DFF)
- 激活功能的目的是什么,为什么ReLU成为深层神经网络的默认吗?
- Python的例子如何构建和训练自己的DFF神经网络
DFF宇宙内的神经网络机器学习
而神经网络监督的方式最常用标签的训练数据,我觉得他们独特的机器学习方法需要一个单独的类别。
神经网络中的分支,DFF子类别下的前馈神经网络,通常也称为多层感知器(mlp)。
下面的图是互动,所以请点击不同的类别扩大并揭示更多。
如果你喜欢科学和机器学习的数据,请订阅得到一个电子邮件当我发布一个新的故事。
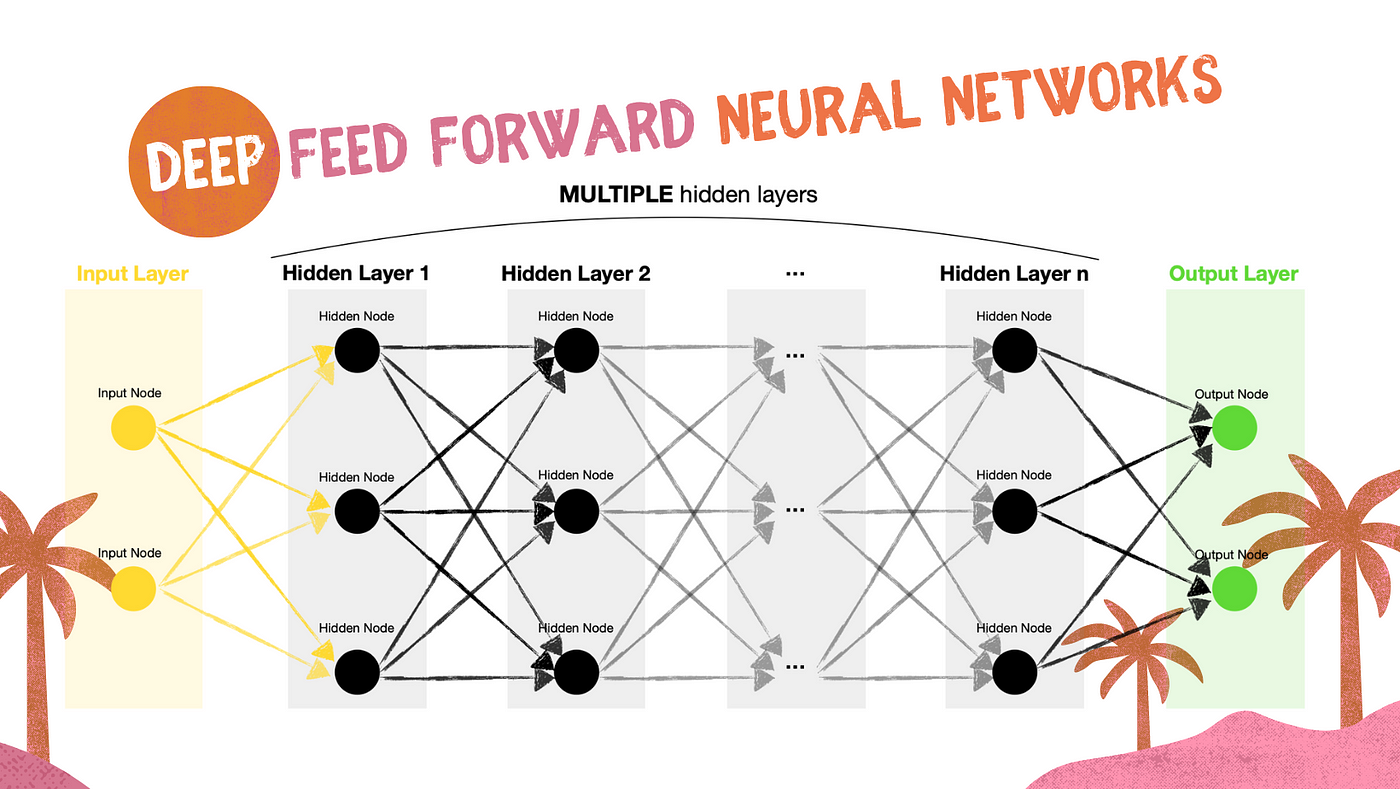
前馈的区别(FF)和深前馈神经网络(DFF)
结构
DFF的结构非常相似的FF。它们之间的主要区别是隐藏层的数量。
目前,人们把一个神经网络与隐层作为一个“浅”网络或只是一个前馈网络。与此同时,神经网络与多个隐藏层(2 +)网络。
如果我们画一个图结构对比FF DFF,就像这样:


深度的意义是什么?
通常你会发现比浅的深NNs表现得更好。然而,它并不总是需要使用网络。选择将在很大程度上依赖于手头的任务。
如果你正在与等输入图像数据,然后使用深前馈(DFF)或卷积神经网络(CNN)可能会产生更好的结果比简单的饲料刚愎的网络。
然而,假设你的任务是做一些基本的分类和数量有限的输入。在这种情况下,你可能会更好的使用一个简单的FF网络或甚至一个树型算法等XGBoost,随机森林,或者一个决策树。
回到点的深度,答案很简单,更深层次的网络倾向于提供更好的性能在更复杂的任务。有多个假设为什么深网络有更好的表现,从效率改善学习能力更抽象的表示。
下面是一些描述的假设这对课件详细回答:
1。一个浅比深层网络可能需要更多的神经元。
2。浅网络可能更难火车与我们当前的算法(例如,它可能有一个更严重的局部最小值,或者收敛速度可能较慢)
3所示。浅架构或许不适合我们通常试图解决的问题(如目标识别是一个典型的“深度”,分层过程)?
4所示。也许没有上面提到的是一个不同的原因。
不要犹豫来分享如果你遇到为什么更深更好的决定性证据。
激活功能的目的是什么,为什么ReLU成为深层神经网络的首选?
深层网络提出的挑战
一个神经网络架构激活功能里面隐藏的节点和输出节点。简而言之,激活函数的输入值输入节点,执行转换,然后将结果起传递给下一组神经元。
这是一个简单的例子前馈神经网络显示激活函数是什么样子(在这种情况下,softplus和乙状结肠)以及他们如何将神经网络中的数据。


传统上,两个最广泛使用的非线性激活函数乙状结肠和双曲正切(双曲正切)。然而,使用这些激活函数与深层神经网络提出了一个问题消失的梯度。
错误是backpropagated通过网络在训练过程中,用于更新权重。不幸的是,倾向于乙状结肠和双曲正切激活功能饱和。
这意味着巨大的消极和大型积极值转换为0和1和乙状结肠的1和1双曲正切。提供的饱和经常发生无论输入节点包含有用的信息。
随着饱和函数,导数变得接近于零。因此,有基本上没有梯度通过网络传播,使它具有挑战性的学习算法继续调整权重。
这是一个三个激活函数的例子:


修正线性单元(ReLU)激活函数
ReLU介绍了作为一个消失的梯度的问题解决方案,并迅速成为一个默认选择最深前馈(DFF)和卷积神经网络(CNN)。
它有一个非常简单的函数,它将所有负面的值设置为0,同时为所有积极输入返回相同的值。
ReLU (x) = max (x, 0)
ReLU当然是一个非线性函数。然而,它非常接近线性,使它保存的许多特性,使基于线性模型容易优化梯度方法。同时,它也倾向于归纳好。
Tensorflow ReLU的实现允许您设置几个参数来优化ReLU你的喜欢。例如:
- 你可以设置指定max_value或饱和阈值;
- 你可以把ReLU变成一个漏水的ReLU通过设置一个α参数,在α支配的斜率值低于0(或者另一个选择阈值)。
下面是一个例子的ReLU max_value设置为3和漏水的ReLUα为0.01。


您可以选择使用max ReLU帽子如果你遇到的问题爆炸的梯度在训练模型。正如你可能已经猜到了,爆炸的梯度是梯度消失,相反的问题,它的结果具有较大的权重。
尽管如此,一般来说,你可以避免爆炸梯度的问题如果你使用他的体重标准ReLU初始化。他的初始化:HeNormal,HeUniform)确保足够小的初始权重梯度爆炸的风险降到最低。
与此同时,一个漏水的ReLU可以是有益的,当你想避免“死”神经元,从负面结果输入被标准ReLU设置为0。


Python的例子如何构建和训练自己的DFF神经网络
现在是时候玩和发展我们自己的深层神经网络识别MNIST数字的能力。
设置
我们需要以下数据和库:
- MNIST手写的数字数据(版权持有和科琳娜雅安·勒存下议会Creative Commons Attribution-Share都3.0许可协议;的原始数据:MNIST数据库)
- 熊猫和Numpy对数据操作
- Matplotlib用于显示手写的数字
- Tensorflow / Keras的神经网络
- Scikit-learn图书馆对一些基本的模型评价
我们进口的所有库:
上面的代码输出包版本中使用这个例子:
Tensorflow / Keras: 2.7.0
熊猫:1.3.4
numpy: 1.21.4
sklearn: 1.0.1
matplotlib: 3.5.1
接下来,我们摄取MNIST手写的数字数据和显示前十位数与他们真正的标签上面的图像。
这是我们得到的运行上面的代码:


正如你所看到的,我们有60000图像训练集和10000年在测试集。注意,他们的尺寸是28 x 28个像素。然而,我们在使用前需要重塑数据训练DFF神经网络。
新的形状:
新X_train:形状(60000、784)
新X_test:形状(10000、784)
培训和评估深前馈神经网络
我在代码中提供了广泛的评论,所以我不会重复相同的文章的主体。然而,有一些事情我想强调:
- Softmax激活在输出层——这从所有10个节点函数值,并将它们转换成值在0和1之间,在这十值之和等于1。因此,你可以想象作为一种“概率的输出。“因为每个输出节点代表一个不同的数字0 - 9之间,最高的价值(“概率”)是神经网络认为是正确答案。
- 使用“SparseCategoricalCrossentropy”损失函数——当你的目标是二进制数据,您应该使用“BinaryCrossentropy。“当你有两个或两个以上的标签类,和你的数据OneHot编码,您应该使用“CategoricalCrossentropy。“在我们的场景中,我们有十类预测,但我们的目标数据不是OneHot编码。因此,我们需要使用“SparseCategoricalCrossentropy。”
- 预测的标签——因为预测给我们十值(一个为每个输出节点),我们需要通过结果通过argmax函数这需要它作为输入并返回最高的数字值(“概率”)。
这是一个总结和评价指标为我们深前馈神经网络,我们训练了五个时期。

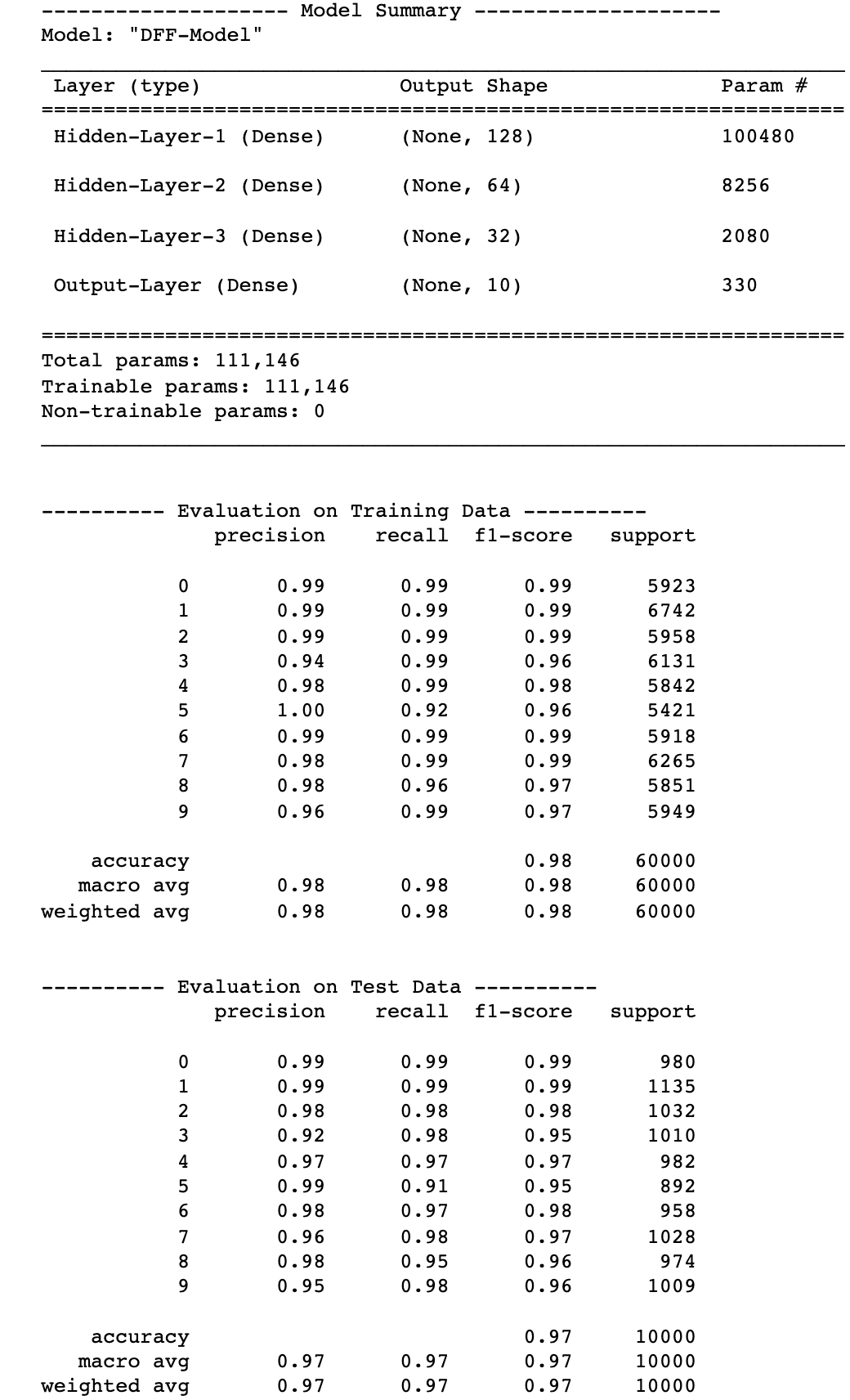
而97%的精度测试数据是非常不错的,你可以通过训练提高的结果更多的时代或尝试网络结构。所以给它一个,让我知道如果你设法击败我的分数!
结论
恭喜你!你现在可以成功创建深前馈神经网络,实验网络结构,选择激活功能和使用你的网络进行预测。
随意使用本文提供的代码为自己的项目。你也可以下载整个Jupyter笔记本从我GitHub库。
我试图让我的文章更有用的读者,我将很感激如果你可以让我知道是什么驱使你阅读这篇文章,以及它是否给了你正在寻找的答案。如果没有,缺少的是什么?
干杯!
扫罗Dobilas
如果你已经花了本月学习预算,下次请记得我。我的个性化链接加入培养基:















