数据库
开始使用Trino查询引擎
如何安装Trino一步一步的教程,连接到SQL server,并编写一个简单的Python客户机。
Trino是一个分布式开源SQL查询引擎进行大数据分析。它可以运行分布式和并行查询因此非常快。Trino可以运行在本地和云环境中,如谷歌、Azure和亚马逊。
在本教程中,我将介绍如何安装在本地Trino,连接到一个MySQL数据库(XAMPP提供的)和一个简单的Python客户机连接到它。可以在官方Trino文档这个链接。
1配置Trino搜索引擎
通常Trino排版o集群的sed的机器,一个协调器和许多工人。所有的工人连接到协调器,它提供了客户的访问点。
安装Trino之前,我应该确保运行一个64位的机器。然后我可以继续安装Python和Java:
- Python≥2.6
- JDK,发布的Azul祖鲁语(推荐)
一旦我已经安装了前面的要求,我可以下载Trino搜索引擎并打开它。在使用Trino之前,我必须配置它。
在打开的目录,我创建另一个目录,名为等,它将包含所有的配置文件。有三个主要的配置文件:
config.properties——Trino服务器的配置文件jvm.config——命令行选项用来启动Java虚拟机node.properties——特定的配置为每个节点。
的等文件夹也应该包含另一个文件夹,叫道目录的列表,其中包含所有数据源(即连接器)。可以在列表中所有可用的连接器这个链接。
1.1 config.properties
最小为服务器配置如下:
协调员= true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5 gb
query.max-memory-per-node = 1 gb
query.max-total-memory-per-node = 2 gb
discovery.uri = http://127.0.0.1:8080
在前面的例子中,参数node-scheduler.include-coordinator = true指定相同的主机行为作为协调员和工人。如果我想使用单独的机器协调员和工人,我不会使用前面的参数和使用协调员= true协调器和协调员= false为每一个工人。
在前面的例子中,我也发现URI指定,例如HTTP服务器的地址是可用的。在我的例子中,我利用本地地址。
其他参数指定的最大内存使用量。
1.2 jvm.config
这个文件包含命令行选项用于Java虚拟机运行。一个很好的例子,这个文件可能是下列之一:
-服务器
-Xmx16G
- xx:及
- xx: + UseG1GC
- xx: G1HeapRegionSize = 32米
- xx: + ExplicitGCInvokesConcurrent
- xx: + ExitOnOutOfMemoryError
- xx: + HeapDumpOnOutOfMemoryError
- xx: -OmitStackTraceInFastThrow
- xx: ReservedCodeCacheSize = 512
- xx: PerMethodRecompilationCutoff = 10000
- xx: PerBytecodeRecompilationCutoff = 10000
-Djdk.attach.allowAttachSelf = true
-Djdk.nio.maxCachedBufferSize = 2000000
1.3 node.properties
这个文件包含每个节点的基本配置,包括机器的集群的名称(node.environment),存储数据的目录(node.data)和节点id (node.id)
node.environment = name_of_cluster
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir =/ /数据/文件夹/路径
1.4目录
这个文件夹包含所有连接器被Trino利用。连接器包含所有所需的信息连接到外部存储引擎,比如MySQL服务器,MongoDB,弹性搜索,等等。每个连接器应该与一个单独的配置文件,名字connector_name.properties(如。mysql.properties)。每个连接器的详细信息,请查看文档。
在这篇文章中,我配置一个MySQL连接器。我创建了一个文件,命名mysql.properties,用以下最小配置:
connector.name = mysql
连接url = jdbc: mysql: / / localhost: 3306
连接用户=根
连接密码= my_password
在我的例子中,我利用MariaDB XAMPP提供的服务器。它完美地!
2运行Trino搜索引擎
现在,一切都可以运行。假定MySQL服务器已经运行,Trino服务器可以在两种模式开始,背景,作为一个单独的守护进程,或前景。
在后台运行服务器,输入trino主要目录并运行以下命令:
bin /发射器开始
在前台运行服务器,从trino主要目录运行以下命令:
bin /启动运行
最后启动方法的优点是,如果有一些问题,我可以很容易地识别它们。出于这个原因,我更喜欢在前台启动服务器。
现在,服务器可以查询。
我可以从浏览器访问服务器信息,以下地址:
http://127.0.0.1:8080
浏览器显示登录页面如下:
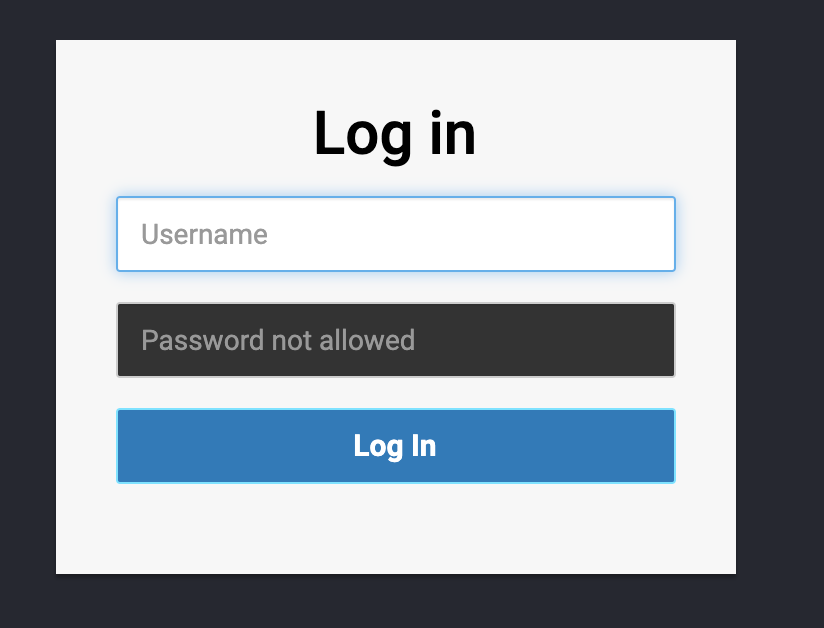
我可以输入用户名和密码中定义mysql.properties文件。
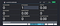
然后,我应该能够看到下面的控制台,它显示了集群概述、信息查询和工人:
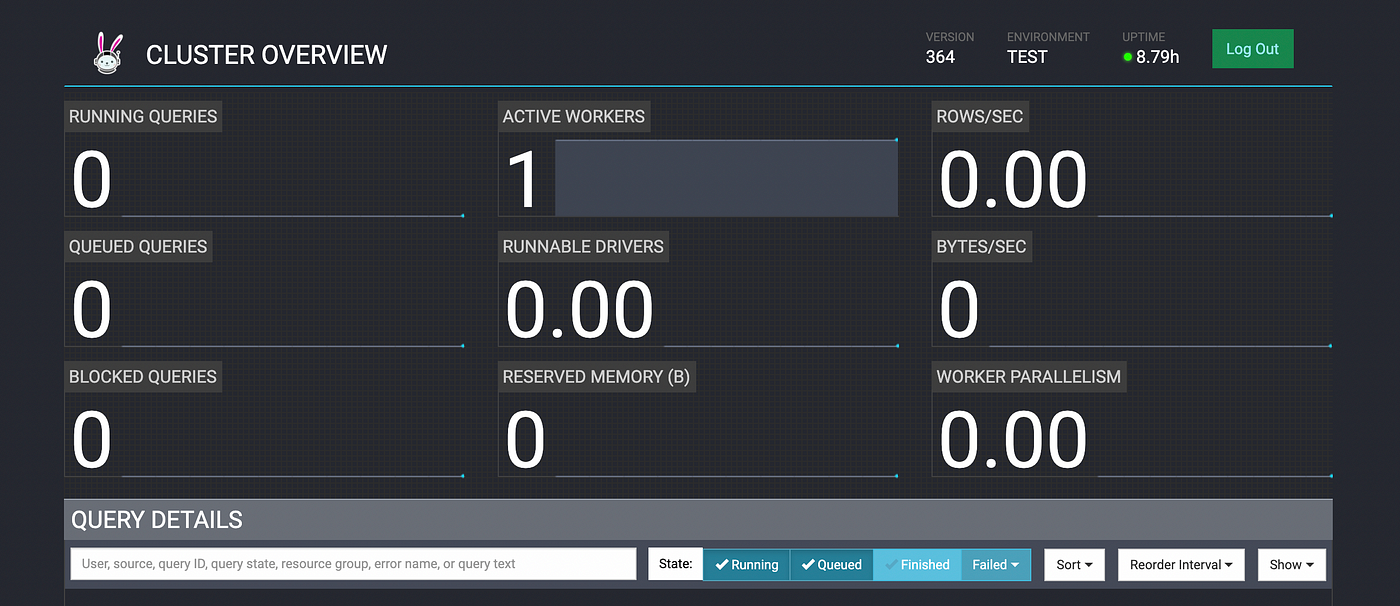
3一个Python客户机
可以写入不同Trino客户查询Trino DB,所描述的官方文档。在本教程中,我将介绍如何实现一个简单的Python客户机Trino。
我利用trino包,它可以安装如下:
pip3安装trino
这个包可以找到的官方文档这个链接。
客户机的代码非常简单:
首先,我定义的连接参数,通过trino.dbapi.connect ()功能,我也指定要使用的目录(mysql在我的例子中)。然后,我连接和执行一个简单的查询,显示所有表中包含我的SQL server。
作为字符串传递到cur.execute ()功能,我可以写任何SQL查询。
运行脚本后,我可以回到Trino控制台在浏览器中。如果我点击完成按钮底部的菜单,我得到一些信息在前面的查询:
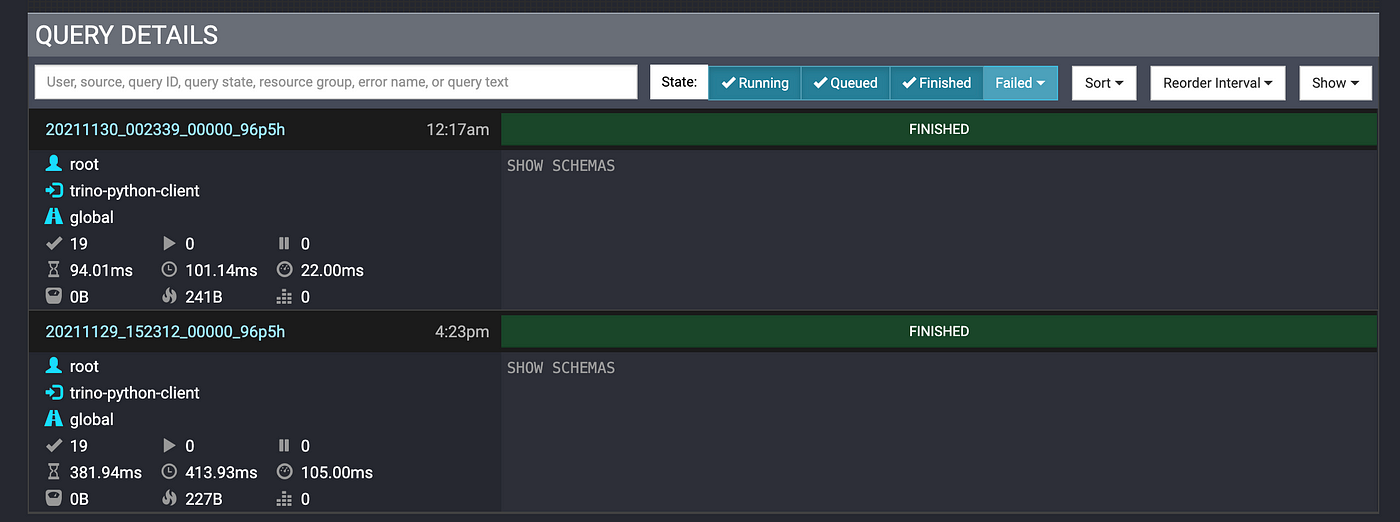
总结
在这篇文章中,我描述了如何配置和运行的基本配置Trino搜索引擎,以及一个简单的Python脚本连接到它。
Trino的主要优势是,它可以运行分布式查询,因此能够用于查询很快大数据。
如果你有这么远来读,今天对我来说,已经很多了。谢谢!你可以阅读更多关于我这篇文章。
引用
相关文章
奖金
你知道Trino还允许运行机器学习功能,包括支持向量机(SVM)分类器和解释变量来解决监督问题?
如果你对这个话题感兴趣,你可以阅读它在这里。