数据工程
多功能数据套件的概述
开始使用多功能数据套件,该框架使数据工程师更有效地工作

数据工程师的工作需要各种技能,包括构建数据管道,评估数据库,设计模式和管理它们。简而言之,数据工程师负载,提取,操纵和一般管理数据。通常,这项工作需要很多技能,如果该过程没有自动化,那么数据工程师会冒犯许多错误并浪费很多时间来解决意外事件。
最近,我测试了一个非常有趣的框架,该框架有助于数据工程师职责:多功能数据套件, 被释放VMware作为Github上的开源。
多才多艺的数据套件允许数据工程师半自动执行其任务。实际上,他们只需要专注于框架的数据和一般配置,例如数据库设置和CRON任务计划,而不必担心手动部署,版本控制和类似内容。
换句话说,多功能数据套件简化了数据工程师的寿命,因为它允许以简单快速的方式管理数据,并快速处理意外事件。
数据工程师可以构建完整的数据处理工作负载(数据工作,在多功能数据套件语言中)仅三个步骤:
- 摄取数据
- 处理数据
- 发布数据
在本文中,我概述了多功能数据套件以及一种实际用例,该案例显示了其潜力。有关更多信息,您可以阅读多功能数据套件完整文档。
1个概述
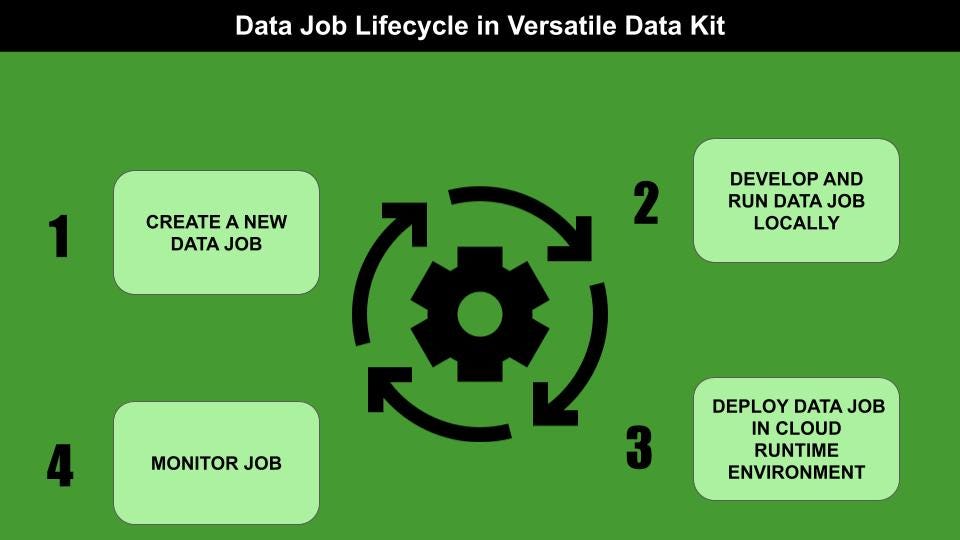
多功能数据套件是一个框架,它使数据工程师能够开发,部署,运行和管理数据作业。数据工作是数据处理工作负载。
多功能数据套件由两个主要组成部分组成:
- 一个数据SDK,它提供了所有用于数据提取,转换和加载以及插件框架的工具,该工具允许根据数据应用程序的特定要求扩展框架。
- 一个控制服务,它允许创建,部署,管理和执行数据作业Kubernetes运行时环境t。
多功能数据套件管理三种类型的数据作业,如下图所示:

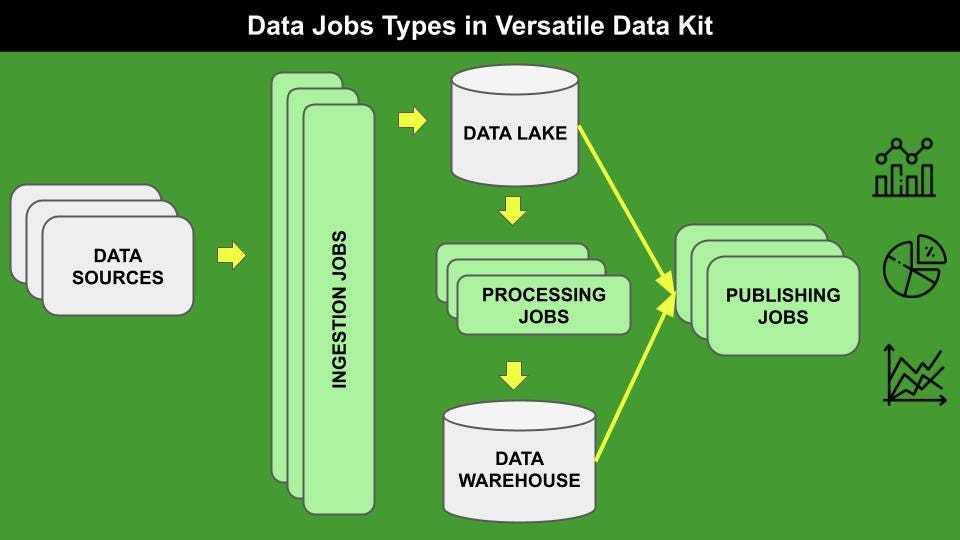
1.1摄入工作
摄入工作涉及将数据从不同来源推向数据湖,这是原始数据的基本容器。数据可以以不同的格式提供,例如CSV,JSON,SQL等。
摄入可以通过不同的步骤来定义,包括但不限于创建数据架构以及将数据加载到表中的过程。所有这些步骤都可以指定写数据工作(通常在Python或SQL中)或通过插入。Versatile Data Kit提供了一些预包装的插件,例如CSV和SQL摄入,但是您可以实现自己的插件。
1.2处理工作
处理工作允许从数据湖中包含的数据集创建策划的数据集。通常,这些工作涉及数据操纵,例如数据清洁和数据聚合。所得数据集存储在数据仓库中,该数据集在概念上与数据湖有所不同,但实际上可能与它一致。由于其高配置性,处理作业也可以与高级分析用例有关。
通常,处理作业是用SQL编写的,但是Python也可以用来实施此类作业。
1.3出版工作
发布作业包括临时查询或视图,可用于不同目的,例如使用标准商业智能工具构建交互式仪表板,向其他应用程序发送通知或警报等。
发布作业取决于特定数据集,因此目前尚未包含在当前版本的Versatile数据套件中。
2使用示例
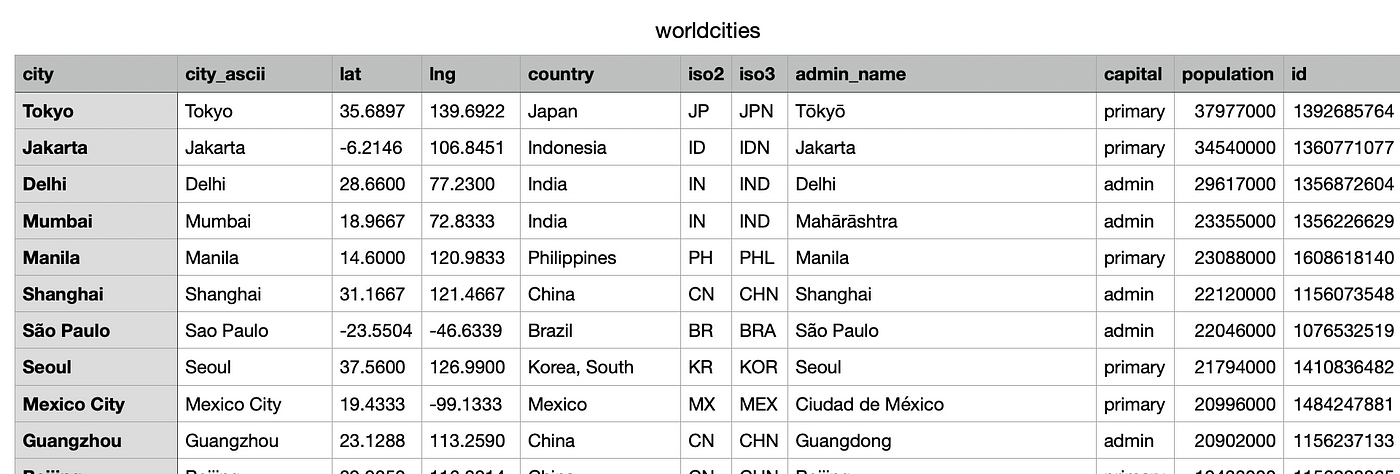
例如,我将开发一个本地数据湖,在其中摄入包含基本版本的CSV文件世界城市数据库,包含大约41k的位置:

我将遵循以下步骤:
- 多功能数据套件安装
- 数据工作创建
- 摄入工作
- 处理工作
2.1多功能数据套件安装
通用数据套件可以轻松安装pip如下:
PIP安装-U PIP SETUPTOOLS轮
PIP安装QUACHSTART-VDK
由于我本地部署所有数据作业,因此我不需要安装控制服务。但是,如果要在Kubernetes运行时环境上部署数据作业,则可以关注本指南。
2.2数据创建
安装后,我可以使用VDK命令与多功能数据套件进行交互。我可以通过以下命令创建一个新的数据作业:
VDK创建-N世界城市-VDK -T我的团队
在哪里-n指定数据作业名称和-t团队名称。有关每个的更多详细信息VDK命令,我可以运行以下命令:
VDK [命令名称] - 螺旋
例如:
VDK创建 - 螺旋
由于创造命令,VDK创建一个新目录,其中包含一些示例文件,每个文件对应于数据作业的一步。

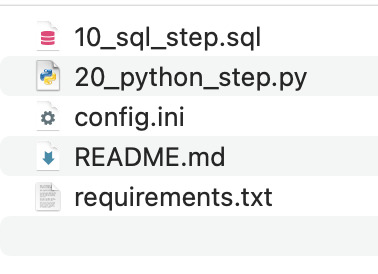
步骤由字母顺序执行,因此,出于可读性原因,可以从1开始编号。有关数据作业目录的结构的更多详细信息,您可以查看官方文件。
2.3环境设置
在开始使用多功能数据套件之前,需要进行初步配置。这是通过配置两个文件来实现的:
需求.txt- 该文件包含项目中利用的库的列表;config.ini- 该文件允许配置一些基本信息,例如团队名称和CRON运行任务。
现在,我可以配置一些环境变量,包括数据库类型(我的情况下的SQLite)和名称(vdk-cities.db就我而言)。我可以直接从终端配置这些变量:
导出vdk_db_default_type = sqlite
导出vdk_ingest_method_default = sqlite
export vdk_ingest_target_default = vdk-cities.db
导出vdk_sqlite_file = vdk-cities.db
这vdk-cities.db文件将是我的数据湖。
2.4摄入工作
我准备在数据湖中摄取数据。首先,我下载了数据集在本地,我将其放入一个名目资源,位于数据作业父母目录中。
这个想法是将数据集摄取到表中城市。这可以通过两种方式实现:
- 写数据工作
- 使用
VDK-CSV插入。
2.4.1编写数据工作
我定义了一个初步数据作业步骤,该步骤丢弃了表格城市,如果存在,请确保始终拥有桌子的新版本:
如果存在城市,则掉落表;
我将此步骤保存在数据作业目录中10_drop_cities_table.sql。这10名称的开头将确保首先执行此步骤。
现在,我定义了第二个数据作业步骤,该步骤定义了表模式,将在其中导入数据集。数据作业步骤对应于以下简单的SQL代码:
创建桌城(城市nvarchar,
city_ascii nvarchar,
lat Real,
LNG真实,
国家nvarchar,
ISO2 nvarchar,
ISO3 nvarchar,
admin_name nvarchar,
资本nvarchar,
人口整数,
ID整数
);
我将这个步骤保存为20_create_cities_table.sql。
最后,我可以将数据集上传到城市桌子。我可以写下以下Python脚本,将数据集加载为Pandas DataFrame,将其转换为dict,然后将DICT的每个项目发送到数据湖中job_input.send_object_for_ingestion()功能,由多功能数据套件提供:
导入记录
来自vdk.api.job_input导入ijobinput
导入大熊猫作为pdlog = logging.getLogger(__名称__)def run(job_input:ijobinput):
log.info(f“启动作业步骤{__name__}”)
df = pd.read_csv('source/worldcities.csv')df_dict = df.to_dict(orient ='记录')
对于范围内的行(0,len(df_dict)):
job_input.send_object_for_ingestion(
有效载荷= df_dict [row],destination_table =“ cities”)
请注意跑()为了使Python脚本被识别为数据作业Python步骤,需要功能。
现在,我准备运行数据作业步骤。我转到数据作业父级目录,然后运行以下命令:
VDK运行世界城市-VDK
数据库vdk-cities.db是在当前目录中创建的,并用城市桌子。我可以通过VDK查询命令或通过传统sqlite命令:
vdk sqlite -Query -Q'从城市中选择 *
2.4.2使用VDK-CSV插入
将数据集加载到数据湖中的替代方法是使用插件。就我而言,我将使用VDK-CSV插入。我可以轻松地安装它pip:
PIP安装QuickStart-VDK VDK-CSV
然后,我可以通过以下命令摄入数据集:
VDK Ingest -CSV -F来源/WorldCities.CSV -T城市
2.5处理工作
作为处理工作,我创建了城市仅包含位于美国的城市的表。为了做到这一点,我定义了两个处理工作:
- 如果存在,请删除视图
- 创建视图并将其保存在默认数据湖中。
首先,我编写了进一步的数据作业步骤,命名为40_drop_usa_cities_view.sql:
如果存在USA_CITITS;
然后我创建了另一个数据作业步骤,该步骤创建了视图:
创建View USA_CIES
作为
选择 *
来自城市
国家='美国'的地方;
我再次运行所有数据工作:
VDK运行世界城市-VDK
并将视图添加到数据湖中。
概括
在本文中,我描述了多功能数据套件的概述,这是一个非常强大的框架,允许将数据管理为有效的方式。
此外,我已经说明了该框架的起始用例,以及数据作业摄入和处理。有关更多详细信息,您可以阅读多功能数据套件用户指南。
可以从我的GitHub存储库下载本教程的完整代码。
出于疑问或对多功能数据套件的疑问,您可以直接加入他们的公共休闲工作区或者他们的邮件列表或者在Twitter上关注他们。
如果您已经阅读了这本书,对我来说,今天已经很多了。谢谢!您可以在其中阅读更多有关我的信息本文。
您想支持我的研究吗?
您可以每月订阅几美元,并解锁无限文章 -点击这里。
相关文章
免责声明:这不是赞助文章。我与多功能数据套件或其作者没有任何隶属关系。文章展示了该工具包的无偏概述,旨在使更广泛的人可以使用数据科学工具。