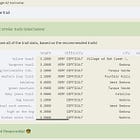
有多少集群?
方法选择正确的数量的集群
介绍
聚类是一种无监督的机器学习方法,它可以识别组织类似的数据点,称为集群,从数据本身。一些聚类算法,如k - means,事先需要知道有多少集群。如果指定集群的数量错了,结果不是很丰富(见图1)。
不幸的是,在许多情况下我们不k<年代pan id="rmm">n噢有多少集群在我们的数据。事实上,弄清楚有多少集群可能的原因我们要首先进行聚类。当然,数据集的领域知识可能有助于确定集群的数量。然而,这种假设您知道目标类(或者至少有多少类),并在无监督学习这是不正确的。我们需要一个方法告诉我们关于集群的数量不依赖目标变量。
一个可能的解决方案在确定正确的数量的集群是一种蛮力的方法。我们尝试用不同数量的集群应用聚类算法。然后,我们找到优化的幻数聚类结果的质量。在本文中,我们首先介绍两种流行的指标来评估集群质量。然后我们介绍三种方法找到最优数量的集群:
- 弯头的方法
- 的优化轮廓系数
- 统计的差距
质量的聚类结果
之前进入不同的方法来确定最优数量的集群,我们将看到如何定量评估聚类结果的质量。想象以下场景。相同的数据集是集群分成三个集群(参见图2)。正如你所看到的,定义集群在左边,而右边的集群识别差。
这是为什么呢?记住,聚类的目标是集团在集群数据点,以便(1)点集群内尽可能相似,(2)分属于不同簇尽可能不同。这意味着,在理想的聚类,within-cluster变化很小而大类间变化很大。因此一个好的聚类质量指标应该能够总结(1)或(2)定量。
这样一个质量指标是惯性。这是计算数据点之间的距离的平方和以及他们属于集群的中心。惯性量化within-cluster变异。
另一个流行的指标是轮廓系数,试图总结within-cluster和大类间变异。在每个数据点,我们计算集群中心的距离数据点所属(称为一个),以及第二个最佳的距离(称为集群中心b)。在这里,第二个最好的集群指最接近集群不是当前数据点的集群。然后,基于这两个距离一个和b,剪影年代数据点计算s = (b) / max (a, b)。
在理想的聚类,距离一个相比是非常小的距离b,导致年代在接近1(参见图3(左)。如果集群有点不佳,那么距离一个和b不得有明显不同(参见图3,中心)。在这种情况下年代接近0。如果集群更糟糕,那么距离一个实际上可能比距离b(参见图3)。在这种情况下,年代变得消极,接近1。
一次年代计算所有数据点,平均的年代决定一个轮廓系数。轮廓系数可以分别计算出每个集群,或者为所有的数据点。轮廓系数接近1表明,聚类算法能够对数据进行分区布置得井然有序的集群。
弯头的方法
惯性的递减函数簇的数量k。然而,下降速度高于或低于最优数量的不同集群K。为k<K,惯性迅速减少,而减少是缓慢的k>K。因此,通过策划一系列的惯性k,一个可以确定的曲线弯曲,或手肘,k .图4显示了一个惯性的情节从我们的例子如图1所示。我们可以清楚地看到一个弯曲,或手肘,k= 6。
这种方法,然而,有些主观,因为不同的人可能会识别肘在不同的位置。在我们的例子在图4中,有些人可能会认为k= 4肘部。此外,肘可能不是总是明显的,稍后我们将看到。
肘部的用例方法中可以看到一个自然语言的问题来确定最优数量的主题在一个社交网络使用<一个class="ek ls" href="https://www.knime.com/software-overview?utm_source=medium&utm_medium=social&utm_term=&utm_content=&utm_campaign=Community" rel="noopener ugc nofollow" target="_blank">KNIME分析平台(见博客<一个class="ek ls" href="https://www.knime.com/blog/topic-extraction-optimizing-the-number-of-topics-with-the-elbow-method?utm_source=medium&utm_medium=social&utm_term=&utm_content=&utm_campaign=Community" rel="noopener ugc nofollow" target="_blank">主题提取:优化主题弯头的方法的数量)。由于没有KNIME节点计算惯性<一个class="ek ls" href="https://kni.me/n/QNB4FsAPnEAgOMVh?utm_source=medium&utm_medium=social&utm_term=&utm_content=&utm_campaign=Community" rel="noopener ugc nofollow" target="_blank">Java代码片段节点被用来计算惯性在这个例子。这是一个代码片段用于计算惯性。
/ /初始化平方和
out_sum_squares = 0.0;
/ *
上半年列属于起源的特点。
列属于下半年的终点站。
组的列必须在相同的顺序。
* /
int col_count = getColumnCount ();
int no_dimensions = col_count / 2;/ /遍历特性列
for (int i = 0;我< no_dimensions;我+ +){
/ *
如果我从原点的功能和检查
我从终点站(即的特性。,我+ no_dimensions)
不是失踪,有类似的列名
* /
如果(! isMissing(我)& &(我tDouble)的类型
& & & & ! isMissing (i + no_dimensions)
的类型(i + no_dimensions tDouble) & &
getColumnName (i + no_dimensions) .contains (getColumnName (i))) {
/ /计算平方距离和增加金额
out_sum_squares + =数学。战俘(getCell(我tDouble)
getCell (i + no_dimensions tDouble), 2);
}
}
轮廓的方法
轮廓系数可能提供更客观的方法来确定最优数量的集群。要做到这一点,只需计算轮廓系数的范围k,确定最优的峰K。KNIME组件<一个class="ek ls" href="https://kni.me/c/XCtuVNVeuqHSQkqk?utm_source=medium&utm_medium=social&utm_term=&utm_content=&utm_campaign=Community" rel="noopener ugc nofollow" target="_blank">优化的k - means(轮廓系数)就是这么做的。它执行一系列的k - means聚类k发现,最优K产生最大的轮廓系数,将数据点分配给集群基于优化K。图5显示了一个示例的一个轮廓系数情节从我们的示例数据呈现在图1。可以看到,轮廓系数峰值k= 6,因此它决定最优K。
差距数据
谈论差距统计,让我们考虑随机数据集的聚类没有任何集群组织。说一个随机数据集集群k集群,并根据结果计算惯性集群(参见图6)。尽管缺乏底层集群组织集群随机数据生产稳步减少inertiae惯性(复数)k增加。这是因为集群中心越多,数据点之间的距离就越小集群中心,生产inertiae衰减。相反,正如我们已经看到在图4中,惯性变化是否下降的速率k低于或高于最优数量的集群K在一个数据集与集群组织。当观察到的惯性和随机数据绘制在一起,变得明显的差异(见图7)。inertiae统计计算通过比较的差距(希望)集群数据集和相应的随机数据集合覆盖相同的范围在数据空间(Tibshirani et al ., (2001))。
实际计算的差距统计,生成大量的随机抽样,然后聚集的范围k,由此产生的惯性是记录。这使得许多inertiae随机的情况下。原始数据集也聚集在一个范围的k,导致一系列inertiae。统计数据的差距,k集群计算的


在那里工作的惯性是(我)我th随机样本(i = 1,2,…, B)k集群,周是惯性从原始数据k集群。我们也计算其标准差


然后我们找到最优K是最小的k满足的条件
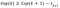

统计涉及到模拟计算的差距。我们称之为函数R差距统计计算了一些脚本在KNIME工作流。特别是,clusGap()函数来计算统计在不同的差距k,maxSE()返回的最优K满足上述条件。图8显示了我们的示例数据集的差距统计图在图1中,基于B= 100在每个迭代k。红色的线条代表的最优K满足上面的条件。
应该注意的是,最优K由统计方法的差距可能不一致。例如,当我们统计方法应用于玩具的差距数据多次,结果最优K可能是不同的(参见图9)。

例如:MNIST手写的数字数据
现在让我们检查上述三种方法与集群组织一组真实的数据。MNIST数据集包括手写的数字从0到9的灰度图像。在这个例子中,我们使用8×8 n = 1797图像像素。图10显示了数据集的一些例子。上述三种方法用来确定最优数量的集群。因为有10个不同的数字在这个数据集,它是合理的假设有10个集群,每个对应一个数字。然而,可能有多种方式人写的一些数字。因此,在现实中集群的数量不一定10。一个2 d数据的散点图(预计tSNE 2 d空间,见图11)表明,一些集群可能从别人布置得井然有序,虽然有些可能接触或重叠的集群。这个例子中可以找到的工作流KNIME中心<一个class="ek ls" href="https://kni.me/w/ACjm92qCUGbXsCX6" rel="noopener ugc nofollow" target="_blank">https://kni.me/w/ACjm92qCUGbXsCX6。
肘法的结果是不确定的,没有明显的手肘情节(图12(左)。有一些微妙的弯曲的情节(如9、12、20、24等等),和这些可能选为集群的数量。


轮廓系数的峰值k= 12(图12)。根据统计方法的差距,k = 12也确定最优数量的集群(图13)。我们可以直观地比较k - means集群k = 9(根据肘部最优方法)和k = 12(最佳根据轮廓和差距统计方法)(参见图14)。
结论
我们展示了三种不同方法的选择最优数量的集群,即肘法、轮廓系数和统计的差距。而一个手肘情节,而主观的解释,轮廓系数和差距统计方法可以精确确定集群的数量。然而,统计涉及到仿真和它的差距可能并不总是产生相同的解决方案。
像许多机器学习方法,这里描述的方法并不适用于所有情况。因为这些方法量化集群中心和数据点之间的距离,他们适合寻找凸集群,如集群k - means聚类中找到。
参考
- 罗伯特•Tibshirani Guenther沃尔特,特雷福Hastie。估计集群的数量在一个数据集通过统计的差距。皇家统计学会杂志》的系列B, 63: 411 - 423 (2001)。