有多少簇?
选择正确的聚类数量的方法
介绍
群集是一种无监督的机器学习方法,可以从数据本身识别类似数据点的组,称为群集。对于某些聚类算法,例如k-means,人们需要知道预先有多少群集。如果指定错误的群集数量,结果不是很好的信息(参见图1)。
不幸的是,在许多情况下,我们没有k<年代pan id="rmm">n我们数据中有多少个群集。实际上,弄清楚有多少群集可能是我们希望首先执行群集的原因。当然,数据集的域知识可以有助于确定群集的数量。但是,这假设您知道目标类(或至少有多少个类),这在无监督的学习中是不是真的。我们需要一种方法,可以向我们通知我们的群集数而不依赖于目标变量。
在确定正确数量的簇中的一种可能解决方案是蛮力方法。我们尝试使用不同数量的群集应用群集算法。然后,我们发现优化聚类结果质量的幻数。在本文中,我们首先介绍了两个流行的指标来评估群集质量。然后,我们涵盖了三种方法来找到最佳群集:
- 弯头的方法
- 剪影系数的优化
- 统计的差距
聚类结果的质量
在使用不同的方法来确定最优的聚类数量之前,我们将看到如何定量地评估聚类结果的质量。想象以下场景。相同的数据集被聚成三个聚类(参见图2)。可以看到,左边的聚类定义得很好,而右边的聚类识别得很差。
这是为什么?请记住,聚类的目标是将群集中的数据点分组,以便群集中的(1)点和属于不同群集的点(2)点尽可能差异。这意味着,在理想的聚类中,群集内变化小,而群集变化很大。因此,良好的聚类质量指标应该能够定量地概括(1)和/或(2)。
其中一个质量度量是惯性。这是作为数据点和它们所属的集群中心之间距离的平方和计算的。惯性量化了簇内的变化。
另一个流行的度量是剪影系数,它试图总结簇内和簇间的变化。在每个数据点上,我们计算到该数据点所属的集群中心的距离(称为一个),以及到第二最佳集群中心的距离(称为b).这里,第二个最佳集群指的是最近的集群,而不是当前数据点的集群。然后基于这两个距离一个和b,剪影年代该数据点的s=(b-a)/max(a,b)。
理想下聚,距离下聚一个与距离相比非常小吗b,导致年代接近1(见图3,左边)。如果聚类是次优的,那么距离一个和b可能不会有显著的差异(见图3中)。在这种情况下年代接近于0。如果聚集更糟糕,那么距离一个可能比距离还大b(见图3右)。在这种情况下,年代变成负的,接近-1。
一次年代在所有数据点计算,平均值年代确定轮廓系数。可以为每个簇分别计算轮廓系数,也可以为所有数据点计算轮廓系数。当剪影系数接近1时,表明该聚类算法能够将数据划分为分离良好的聚类。
弯头的方法
惯性是群集数量的递减函数k.但在最佳聚类数以上或以下,其下降速率是不同的K.为k<K,惯性迅速减少,而减少缓慢k>K.因此,通过绘制在某一范围内的惯性k,可以确定曲线弯曲或肘部,在K的位置。图4显示了图1中的示例的惯性图。我们可以清楚地看到弯曲或肘部k= 6。
然而,这种方法有点主观,因为不同的人可能会在不同的位置识别肘部。在图4中的例子中,有些人可能会提出异议k=4是肘部。此外,肘部可能并不总是明显的,我们将在后面看到。
肘部方法的用例可以在一个自然语言问题中看到,用来确定社交网络中使用的最佳主题数量<一个class="ek ls" href="https://www.knime.com/software-overview?utm_source=medium&utm_medium=social&utm_term=&utm_content=&utm_campaign=Community" rel="noopener ugc nofollow" target="_blank">KNIME分析平台(见博客<一个class="ek ls" href="https://www.knime.com/blog/topic-extraction-optimizing-the-number-of-topics-with-the-elbow-method?utm_source=medium&utm_medium=social&utm_term=&utm_content=&utm_campaign=Community" rel="noopener ugc nofollow" target="_blank">主题提取:使用肘法优化主题数量).由于没有KNIME节点来计算惯量,因此<一个class="ek ls" href="https://kni.me/n/QNB4FsAPnEAgOMVh?utm_source=medium&utm_medium=social&utm_term=&utm_content=&utm_campaign=Community" rel="noopener ugc nofollow" target="_blank">Java代码片段节点用于计算此示例中的惯性。以下是用于计算惯性的代码片段。
//初始化平方和
Out_sum_squares = 0.0;
/ *
列的前半部分属于原点的特征。
列的后半部分属于终端的特性。
每组列的顺序必须相同。
*/
int col_count = getColumnCount();
int no_dimensions = col_count / 2;//循环特性列
for (int i = 0;我< no_dimensions;我+ +){
/ *
检查特征i是否来自原点和
来自终端的特性I(即I +no_dimensions)
不缺少,并具有相似的列名称
*/
如果(!Ismissing(i)&& Istype(我,Tdouble)
& & & & ! isMissing (i + no_dimensions)
Istype(i + no_dimensions,tdouble)&&
getColumnName (i + no_dimensions) .contains (getColumnName (i))) {
//计算距离的平方并将其相加
out_sum_squares + =数学。战俘(getCell(我tDouble)
getCell (i + no_dimensions tDouble), 2);
}
}
轮廓的方法
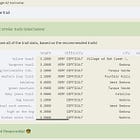
轮廓系数可以为确定最优聚类数量提供更客观的手段。这是通过简单地计算轮廓系数的范围k,并将峰值识别为最佳K.KNIME组件<一个class="ek ls" href="https://kni.me/c/XCtuVNVeuqHSQkqk?utm_source=medium&utm_medium=social&utm_term=&utm_content=&utm_campaign=Community" rel="noopener ugc nofollow" target="_blank">优化k均值(剪影系数)就是这么做的。它在一个范围内执行K-Means聚类k,找到最优的K这将产生最大的剪影系数,并根据优化后的数据点分配给聚类K.图5示出了图1中呈现的示例数据的轮廓系数图的示例。可以看出,轮廓系数峰值k=6,确定为最佳K值。
差距数据
要谈论差距统计数据,让我们考虑群集随机数据集,没有任何群集组织。说随机数据集被群集到k尽管缺乏底层的集群组织,但被聚类的随机数据产生的惯性(惯性复数)稳步减少为k增加。这是因为集群中心越多,数据点到集群中心之间的距离就越小,产生了衰减的惯性。相反,正如我们在图4中已经看到的,惯性下降的速率会改变是否k是否低于或高于最佳集群数量K在一个具有集群组织的数据集中。当观察到的惯性和随机数据绘制在一起,变得明显的差异(见图7)。inertiae统计计算通过比较的差距(希望)集群数据集和相应的随机数据集合覆盖相同的范围在数据空间(Tibshirani et al .,(2001))。
在实际计算间隙统计数据中,生成了许多随机样本,然后聚集在一系列内k,则记录得到的惯量。这允许一些随机情况下的惯性。原始数据集也在一个范围内聚集k,导致一系列的惯性。差距统计,在k集群,计算为


其中wk(i)是来自的惯性我-第一个随机样本(i=1,2,…,B)k聚类,而Wk是来自原始数据的惯量k集群。我们还计算其标准差为


然后我们找到了最佳状态K是最小的k这满足条件
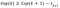

间隙统计的计算涉及模拟。我们在r中调用函数来计算Knime工作流程中的一些r脚本的差距统计。特别地,调用clusgap()函数以计算不同的间隙统计k, maxSE()返回最优值K满足上述条件。图8显示了图1中设置的示例数据的间隙统计图,基于B=每个迭代100次k.红线表示最优K满足上述情况。
应该指出的是最佳的K所确定的差距统计方法可能不一致。例如,当gap统计方法多次应用于我们的玩具数据时,结果是最优的K可能是不同的(见图9)。

示例:mnist手写数字数据
现在,让我们在具有集群组织的真实数据集上检查上述三种方法。MNIST数据集由从0到9的手写数字灰度图像组成。在这个例子中,我们使用的是8x8像素的n=1797图像。图10显示了数据集的一些示例。使用上面描述的三种方法来确定最优的聚类数量。因为在这个数据集中有10个不同的数字,所以可以假设有10个集群,每个集群对应一个数字。然而,有些数字可能有多种写法。因此,实际上集群的数量不一定是10个。数据的2D散点图(通过tSNE投影到2D空间,见图11)显示,有些簇可能与其他簇很好地分开,而有些簇可能是接触或重叠的。此示例的工作流可以在KNIME Hub上找到<一个class="ek ls" href="https://kni.me/w/ACjm92qCUGbXsCX6" rel="noopener ugc nofollow" target="_blank">https://kni.me/w/acjm92qcugbxscx6..
肘部方法的结果不确定,因为图中没有明显的弯头(图12,左)。绘图中有一些微妙的弯曲(例如,参考为9,12,20,24的名称,可以选择其中的任何一个作为簇的数量。


剪影系数有一个峰值k= 12(图12,右)。根据间隙统计方法,K = 12也被确定为簇的最佳数量(图13)。我们可以在视觉上比较K-Means群集与k = 9(根据肘部方法最佳)和k = 12(根据轮廓和间隙统计方法最佳)(参见图14)。
结论
我们展示了三种选择最佳聚类数的方法,即弯头法、剪影系数和间隙统计量。虽然肘弯图的解释比较主观,但轮廓系数和间隙统计方法都能准确地确定簇数。然而,差距统计涉及模拟,它可能不总是产生相同的解决方案。
像许多机器学习方法一样,这里描述的方法并不适用于所有场景。由于这些方法量化了聚类中心和数据点之间的距离,因此它们适用于寻找凸聚类,例如在K-Means聚类中发现的聚类。
参考
- Robert Tibshirani, Guenther Walther, Trevor Hastie。通过差距统计估计数据集中的聚类数量。英国皇家统计学会学报,B辑,63:411-423(2001)。