映射,过滤器,减少 - 功能数据管道设计的高阶函数
深度潜水在高阶函数以及它们如何用于设计功能数据流水线的数据转换
Recap
在我以前的帖子functional programming features for “control flow”,我提供了函数组合的概述,并讨论了使用高阶函数和递归作为“功能迭代”的形式。
In this post, we will explore more on higher-order functions and how they can be used in designing functional data pipelines.
在此之前,让我们从典型的数据流水线开始看起来像。
数据处理和数据流水线设计模式
数据处理的经典方法是编写一个使用该程序的程序数据管道设计模式。


在一个典型的目的apipeline, we read data from a source, transform the data in some desired way, and collect the output as new data. This is what is commonly known as the “extract, transform, load” (ETL) process.
- 提炼:在数据提取阶段,从源系统中提取数据并验证以进行正确性。
- 转变:在数据转换阶段,将一系列功能应用于提取的数据,以便为加载到目标数据存储来准备它。
- 加载:在数据加载阶段,数据将加载到目标数据存储中 - 它可能是一个平面文件(如CSV或镶木地板)或数据仓库。
数据变换的高阶函数
A simplified sketch of a typical ETL process from database source to flat file in S3 bucket is shown below:


虽然数据提取和数据加载阶段取决于程序外部的源和目标数据存储的状态,但数据变换阶段取决于输入数据,并且函数应用于程序本身内的数据。因此,数据变换可以自然表示为用一系列功能组成的功能操作 - 也称为功能组合.
对于支持函数作为一流对象的编程语言,功能组合可以以高阶函数的形式表示。虽然我们可以编写自己的高阶函数,但有一些有用的内置函数常用于数据转换中:
地图筛选减少
这篇文章的重点是探讨这些内置的高阶函数,并讨论如何在设计功能数据管道中使用。
地图
这地图函数接受函数作为输入,将函数应用于值集中的每个元素,并返回新的功能输出值集合。

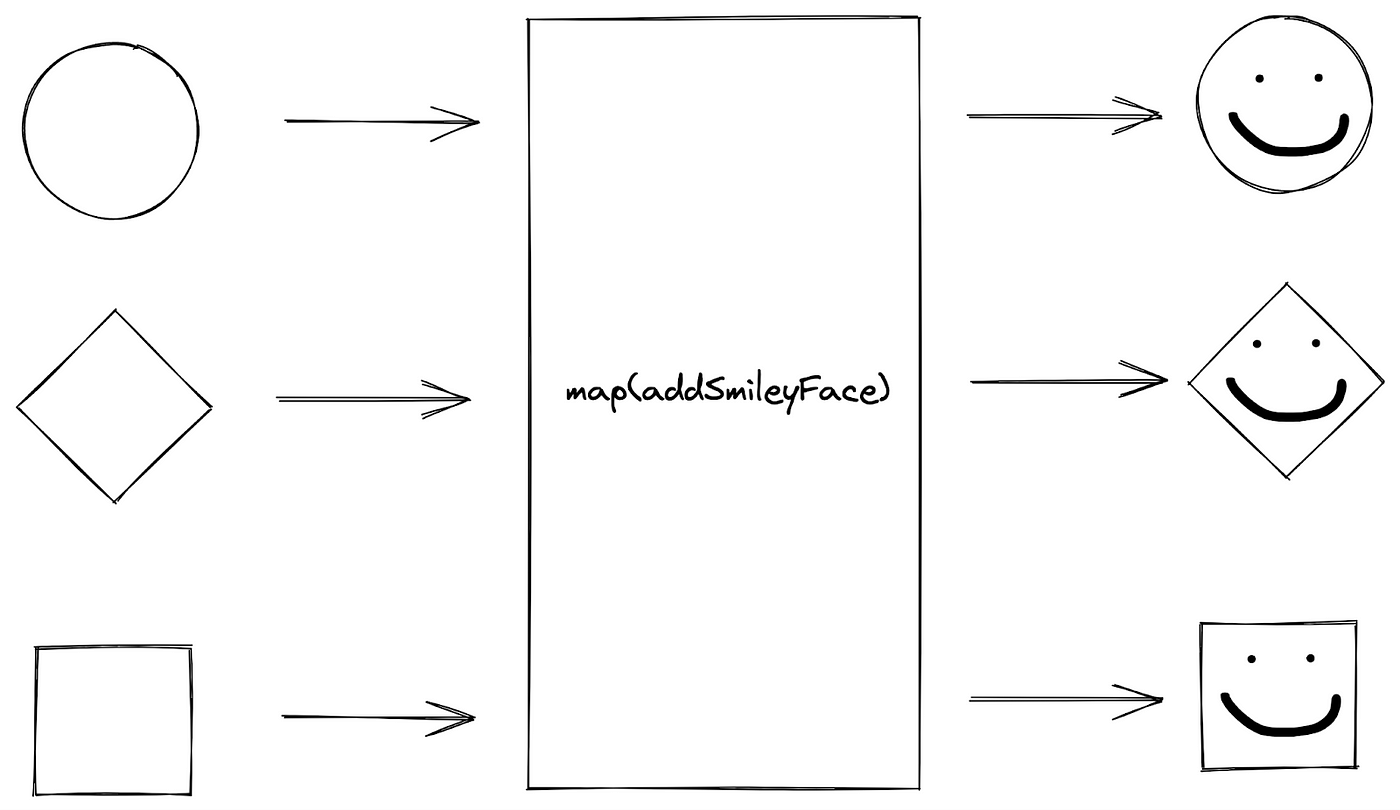
地图function (Image by author)例如,当我们用一个映射的形状集合时addsmile.操作,我们通过将操作应用于形状,“映射”集合中的每个形状。用映射形状的输出addsmile.op.eration are consolidated into a new collection of shapes with a smile added to the input shape.
A detailed discussion on the地图implementation in Python and Scala can be found inmy previous post.
筛选
这筛选函数接受返回布尔值的函数(也称为apredicate)作为输入,将函数应用于值集中的每个元素,并返回返回的元素真的来自function as a new collection.
谓词应该接受与集合中的元素相同类型的参数,使用元素评估结果并返回真的to保持元素在新的或集合错误的过滤它。


筛选function (Image by author)例如,当我们应用时Hasfiniteedges.condition to a collection of shapes, we “filter” each shape in the collection according to whether it satisfies theHasfiniteedges.condition. The shapes that returns真的来自Hasfiniteedges.功能被合并到新的形状集合中,其形状不满足从集合中过滤出的状态。
当我们查看Python内置功能的文档时筛选,据说是筛选function takes in a predicate function and an iterable as input parameters, and constructs an iterator from those elements of the iterable for which the predicate function returns true [1].
在scala中,包中的每个集合类Scala.Collections.和its subsets contain the筛选由scaladoc上的以下功能签名定义的方法[2]:
def filter(p:(a)=> boolean):用于集合类的erreable [a] //
def filter(p: (A) => Boolean): Iterator[A] // for iterators that access elements of a collection
What the function signatures mean is that筛选采用谓词输入参数pwhich transforms a generic input of typeAto a Boolean value, and returns a new iterator consisting of all elements of the iterable collection (of typeA)满足谓词p.
使用a使用现有数字集合创建新的偶数集合功能方法,筛选函数可用于通过向每个元素应用偶数谓词并将满足偶数谓词条件的元素应用于新集合来过滤掉奇数。
- 在Python:
def isEven(x):
返回x%2 == 0def main(args):
collection = [1,2,3,4,5]
evenNums = list(filter(isEven, collection))
打印(赤裸)
- 在scala:
object FilterEven {def isEven(x: Int): Int = {
x%2 == 0
}def main(args:array [string]){
Val Collection = list [1,2,3,4,5]
val alennums = collection.filter(Iseven)
println(erynums)
}}
在两种实现中,筛选function accepts an input predicate that is applied to each element in a collection of values and returns a new collection containing the elements that satisfy the predicate.
减少
这减少function accepts a结合功能(通常是二进制操作)作为输入,将函数应用于值集合中的连续元素,并返回单个累积结果。


减少function (Image by author)例如,当我们应用时Composeall.操作到一系列形状,我们通过折叠A“将”将集合中的形状减少为单个结果partial result和the shape in the iteration into a single result using theComposeall.操作和使用所属结果作为下一次迭代的部分结果。在迭代结束时,输出通过减少形状Composeall.操作作为单个结果(形状复合)返回。
当我们查看Python的文档时减少function in thefunctoolslibrary, it is stated that the减少function takes in a function with two arguments and an iterable (with an optional initial value that can be placed before the items of the iterable in the calculation) as input parameters, and applies the function cumulatively to the items of an iterablefrom left to right[3].
在scala中,包中的每个集合类Scala.Collections.和its subsets contain the减少由scaladoc上的以下功能签名定义的方法[2]:
DEF减少(b>:a)(op:(b,b)=> b):b
函数签名意味着什么减少采取二进制运算符op.of result typeB(类型的超级类型A)将收集中的两个元素转换为类型的值B,并返回在所有元素(类型)之间应用运算符的结果A)在收藏中。二进制运算符是必要的op.返回相同的数据类型Aor the supertype of the typeB存储在集合中,以便减少方法可以对操作的结果和集合中的下一个元素进行后续操作进行操作。
A closer look at the ScalaDoc for the减少方法表示以下操作条件:
- 这binary operator must be联想.
- 这order in which operations are performed on elements may be非确定性.
这联想property for the binary operator is a necessary condition to ensure that the order in which operations are performed during the reductiondoes not change the result对于不同的运行 - 只要正在操作的元素的序列都没有改变。
虽然关联属性是从减少函数(参考透明度的必要条件)返回确定性结果时,但由于操作的顺序可以产生不同的结果,而不是足够的条件non-commutative binary operators如减法和分裂。
如果我们将李ke to指定操作的顺序to be performed on the elements of the collection?
在Scala,我们有reduceleft.和reduceright.Collection类中的方法,其在左右和左右左右订单中累积地应用二进制运算符。这reduceleft.和reduceright.方法由Scaladoc上的以下功能签名定义[2]:
def reduceLeft[B >: A](op: (B, A) => B): B
def reduceRight[B >: A](op: (A, B) => B): B
函数签名之间的关键差异reduceleft.和reduceright.方法与函数签名相比减少are:
- 这binary operator
op.of result typeB(类型的超级类型A)采取部分结果(类型B) 和集合中的下一个元素(类型A)并将它们减少为类型的值B. - 这order of the partial result and the element in the collection in the binary operation indicates the沿集合的操作员应用的方向.
使用a获取数量的累积集合功能方法,减少function can be used to reduce a collection of numbers into a single value by applying the addition operator between consecutive numbers of the collection and performing the operation.
- 在Python:
def main(args):
从Functools进口减少
集合= [1,3,5,2,4]
totalSum = reduce(lambda x,y: x + y, collection)
print(totalSum)
- 在scala:
对象Sumnumbers {def main(args:array [string]){
val集合=列表[1,3,5,2,4]
val totalsum = collection.reduce((x,y)=> x + y)
println(totalSum)
}}
在两种实现中,减少函数接受二进制运算符,该算盘在值集中的连续元素之间应用,并返回一个结果。
左右减少(reduceleft.method in Scala) of the collection of numbers with the binary addition operator is evaluated in the following manner:
[1,3,5,2,4].reduceLeft((x, y) => x + y) // initialize var acc = null
(((1 + 3)+ 5)+ 2)+ 4 //取得第一值,ACC = 1
((4 + 5) + 2) + 4 // acc = 1 + 3 = 5
(9 + 2) + 4 // acc = 4 + 5 = 9
11 + 4 // ACC = 9 + 2 = 11
15 // ACC = 11 + 4 = 15收集结束时返回
同样,左右减少(reduceright.Scala中的方法)以下列方式评估:
[1,3,5,2,4] .Reduceright((x,y)=> x + y)// initialize var Acc = null
1 +(3 +(5 +(2 + 4)))//从右边取第一值,ACC = 4
1 +(3 +(5 + 6))// ACC = 4 + 2 = 6
1 + (3 + 11))// acc = 6 + 5 = 11
1 + 14 // acc = 11 + 3 = 14
15 // acc = 14 + 1 = 15 returned upon end of collection
As the addition operator is联想和换向,操作员应用程序的顺序不会影响结果,从而影响减少method can be safely used in the Scala implementation.
Notice therecursive pattern如何在减少期间评估加法操作?这减少功能是一个特例fold在功能编程中,其指的是一个高阶函数的家庭,其递归地将递归数据结构中的元件组合成单个结果。
内置的收集方法sum,产品,min, 和最大限度是基于的减少功能[4]与其相应的二进制运算符:
- 和:
+ - 产品:
* - min:
math.ordering.min. - 最大限度:
math.ordering.max.
尽管减少使用这些内置收集方法将值缩小到单个值中的函数可用于将值集成到单个值中。减少could improve readability without reinventing the wheel for their intended use cases in data pipeline design.
把它们整合在一起
To summarize, built-in higher order functions are useful in constructing a sequence of data transformations within a data pipeline:
地图将函数应用于集合中的所有元素筛选for selecting elements in a collection based on a boolean condition减少用连续元素之间的关联运算符将元素集合中的一个结果减少为单个结果
尽管地图和筛选返回一个可以使用后续高阶函数处理的新集合,减少返回单个累积值。因此,这是减少在设计具有功能组合物的功能数据管道时,通常将方法及其衍生物作为最终变换步骤实施。
下一步是什么
In this post, we learn about:
- Data Pipeline design pattern
- 数据转换的高阶函数:地图,过滤器,减少
During our exploration on the map-filter-reduce trio of higher-order functions, we briefly mentioned two interesting concepts that are relevant to functional programming:
减少as a special case offold- collection classes as data containers with built-in methods
在该系列内的接下来的几篇文章中,我将在设计功能数据管道时扩展这些概念及其应用程序。
想要更多地幕后的文章我的学习之旅作为数据专业人士?查看我的网站https://ongchinhwee.me!
Originally published athttps://ongchinhwee.meon February 5, 2022.







