使用Julia及其生态系统的机器学习
分析玻璃数据集 - 第1部分
朱莉娅(Julia)快速使用,可以像解释性的语言一样使用,具有高度的合成性,但不是面向对象的。它具有快速增长的生态系统,可帮助您典型的ML工作流程的各个方面。


教程概述
这是一个教程的第一部分,该教程显示了朱莉娅的特定语言特征和生态系统中各种高质量包装的方式如何合并为典型的ML工作流程。
- 第一部分”分析玻璃数据集”专注于如何使用诸如诸如的软件包进行预处理,分析和可视化数据
科学型,,,,数据范围,,,,Statsbase和统计数据。 - 第二部分“使用决策树”专注于ML工作流的核心:如何选择模型以及如何将其用于培训,预测和评估。这部分主要依赖包装
MLJ(=毫克ydF4y2Baarchinel赚钱j乌里亚)。 - 第三部分”如果事情还没有“准备好使用””解释使用几行代码创建自己的解决方案是多么容易,如果可用的软件包没有提供所需的所有功能。
介绍
每个ML工作流程都始于对训练模型的数据的分析和预处理。这些第一步包括了解其来自应用程序域内的数据,检查数据质量以及其统计属性的识别(使用可视化和统计措施)。
在这个托特里亚l我们将使用“玻璃”数据集。这是用于教育目的的数据集。它带有weka工具包,可以从不同的网站下载(例如这里)。该数据集的功能包含有关玻璃不同变体的信息(例如用于生产的材料和光学特征),而目标变量是所得的玻璃变体(请参见下面的摘录)。
数据以文件格式出现arff(属性依赖文件格式);WEKA工具包使用的格式。因此,我们需要一个具有功能的朱莉娅包来读取此格式:arfffiles.jl。因为我们想将数据转换为进一步使用数据框架包dataframes.jl也需要。Scientifictypes.jl增强具有ML特定功能的标准Julia类型,最后但并非最重要的是我们需要downloads.jl功能软件包可以从网站下载数据。
因此,使用这些软件包的代码,从上述网站下载数据,将其从磁盘读取并将其转换为数据框架(并使用科学型)看起来如下:
数据集的第一个概述
为了获得数据集的第一个概述,我们从中获取一些基本信息:
SZ =尺寸(玻璃)给我们尺寸:(214,10),即它有214行和10列。- 和
col_names =名称(玻璃)我们得到了列的名称数据框架:
10元素向量{string}:
“ RI”,“ NA”,“ MG”,“ AL”,“ SI”,“ K”,“ CA”,“ BA”,“ FE”,“类型”
- 和
模式(玻璃)(从科学型)为我们提供所有列的数据类型。类型是朱莉娅的数据类型,而Scitypes是由科学型。在这里,我们可以看到所有功能都是连续的目标变量是名义值(具有七个不同的条目)。
模式(玻璃) - >
┌┌┌┌届─┌┌届─前往┌┬前往┌┬前往┌┌前往┌┌前往┌┌前往┌前往┌前往┌前往┌前往┌前往┌前往┌前往┌前─-──杏仁 - ─-─杏仁 - 前往─-─杏酸 - ──杏酸 - ─杏仁 - ─-─-─-─- - ─- - ─- - ─-─—─-─..-─—─-┐
│名称│scitypes│类型│
├├├├届─├├届─前往├┼前往├┼前往├├前往├├前往├├前往├前往├前往├前往├前往├前往├前往├前往├前─-──杏仁 - ─-─杏仁 - 前往─-─杏酸 - ──杏酸 - ─杏仁 - ─-─-─-─- - ─- - ─- - ─-─—─-─..-─—─-┤
│ri│连续│float64│
│na│连续│float64│
│毫克连续│float64│
│al│连续│float64│
│si│连续│float64│
│k│连续│float64│
Ca│连续│float64│
│ba│连续│float64│
Fe│连续│float64│
│类型│多类{7}│cantoricalValue {string,uint32}│
└└└└届─└└届─前往└┴前往└┴前往└└前往└└前往└└前往└前往└前往└前往└前往└前往└前往└前往└前─-──杏仁 - ─-─杏仁 - 前往─-─杏酸 - ──杏酸 - ─杏仁 - ─-─-─-─- - ─- - ─- - ─-─—─-─..-─—─-┘
目标变量
现在,让我们仔细研究目标变量的特征。glass_types = unique(glass.type)从类型柱子:
6元素向量{string}:
“建立风浮动”
“车辆风浮动”
“餐具”
“制造风向浮动”
“大灯”
“容器”
因此,我们假设数据集中有6种不同的玻璃类型。但这只是事实的一部分。使用级别(玻璃。类型)从科学型揭示实际上有7种不同类型的玻璃:
7元素向量{string}:
“建立风浮动”
“制造风向浮动”
“车辆风浮动”
“车辆风非浮动”
“容器”
“餐具”
“大灯”
其中只有6个出现在玻璃数据集中(计数> 0)。类型“车辆风非浮动”没有发生。关于其存在的知识存储在Arff文件中,并由由科学型。这是一个示例,我们可以看到使用此类型系统的附加值,而不仅仅是依靠语言的本地类型系统(在此示例中会欺骗我们)。
在下一步中,打电话给计数图(从Statsbase)告诉我们,这些类型中的每一种都发生在目标变量内。因此,我们对它们的分布有所了解:建筑物中使用的窗户的玻璃变体是最常见的类型,其次是用于大灯的玻璃类型:
type_count = countmap(glass.type) - >dict {categoricalArrays.CategoricalValue {string,uint32},int64},带6个条目:
“车辆风浮动” => 17
“餐具” => 9
“制造风向非浮动” => 76
“制造风浮动” => 70
“大灯” => 29
“容器” => 13
图表当然比数字列表更有用。因此,让我们使用来自情节包裹:
bar(type_count,group = glass_types,legend = false,
Xlabel =“玻璃类型”,Xrotation = 20,
ylabel =“ count”)


在这里我们也注意到,来自Scientifctypes已经使用了,因此显示“车辆风非浮动”零计数。
详细的功能
现在到功能变量:第一个功能RI是所谓的折射率,一种光学特征,告诉我们快速通过材料传播的快速。其他功能给出不同元素的百分比,例如钠(=拉丁语)NAtrium),镁(毫克) 或者alUminium,已用于生产玻璃。
值合理吗?
让我们首先检查这些功能的值是否合理。打电话描述从数据范围除其他信息外,还给我们一些关于数据集中值范围的印象:


- RI略有1.5左右。从上面提到的Wikipedia页面中,我们了解到这是典型的RI不同种类的玻璃的值位于1.49…1.69的范围内。所以RI“玻璃”数据集中的值似乎很合理。
- 其他功能是百分比。IE。它们必须在0…100的范围内,这对于我们的数据而言是正确的。
- 到目前为止,硅是玻璃中最重要的组成部分(此处> 70%),其次是natrium和Calcium。
我们可以对百分比进行另一个质量检查。每个玻璃成分应总计100%。我们使用转换功能来自数据范围并添加每行的所有值的所有值NA…铁。结果存储在一个名为的新列中sumpct:
glass_wsum =变换(玻璃,
之间(:na,:fe)=> byrow(+)=>:sumpct)
看这个新列,并使用最大和最低限度功能Statsbase表明大多数行的总和并不完全100%,但它们在该值附近少了。这可以通过测量和舍入错误来解释。所以对我们来说还可以。
最大值(glass_wsum.sumpct),最小值(glass_wsum.sumpct)--->(100.09999999999998,99.02)
统计和可视化
由于所有功能属性都是类型连续的,可以计算一些统计数据,并可以绘制其分布图以获得更多洞察力。
Kurtosis&Skewness
- 偏度是分布分布的对称性(或不对称)的度量。负值表明它的左尾部更长(相当平坦),并且质量集中在右侧。我们谈到一个左翼或左尾分配。另一方面,正值表明右翼分配。
- 峰度是对分布的“尾巴”的量度。它表明尾巴向左或向右伸出多远。正态分布的峰度为3。因此,通常将其他分布的峰度与该值进行比较,并被所谓的过多的峰度计算。它说,考虑到的分布的峰度超过了正态分布的峰度。这也是我们从
峰度来自Statsbase包裹。
以下表达式为“玻璃”数据集的所有功能创建了这些措施的列表:
[(ATR,偏度(玻璃[:,atr]),峰度(玻璃[:,atr]))
对于col_names中的ATR [1:END-1]]
这样的表达在朱莉娅中称为“理解”。这是一个数组,其初始值是由迭代计算的。对于col_names中的ATR [1:END-1]在列名(从第一个到第二个但最后一个)上迭代玻璃。对于每个列名(Atr)它创建一个带有三个元素的元组:列名称Atr本身以及偏斜(偏度(玻璃[:,atr]))和峰度(峰度(玻璃[:,atr])该列的),从而创建以下输出:
9元素向量{tuple {string,float64,float64}}:
(“ RI”,1.6140150456617635,4.7893542254570605)
(“ NA”,0.4509917200116131,2.953476583500219)
(“ MG”,-1.144448495986702,-0.428701579888333)
(“ AL”,0.9009178781425262,1.9848317746238253)
(“ SI”,-0.7253172664513224,2.8711045971453464)
(“ K”,6.505635834012889,53.39232655620465)
(“ CA”,2.0326773755262484,6.498967959876067)
(“ BA”,3.392430889440864,12.222071204852575)
(“ FE”,1.7420067617989456,2.5723175586721645)
从这些数字中,我们已经可以看到分布k和ba非常不对称和长尾。但是在大多数情况下,如果我们可视化分布,我们将获得更多的见解。
特征RI
让我们从功能开始RI。小提琴图,可以使用小提琴来自统计数据包装,很好地显示了其分布的样子。小提琴(glass.ri,legend = false)产生以下图:

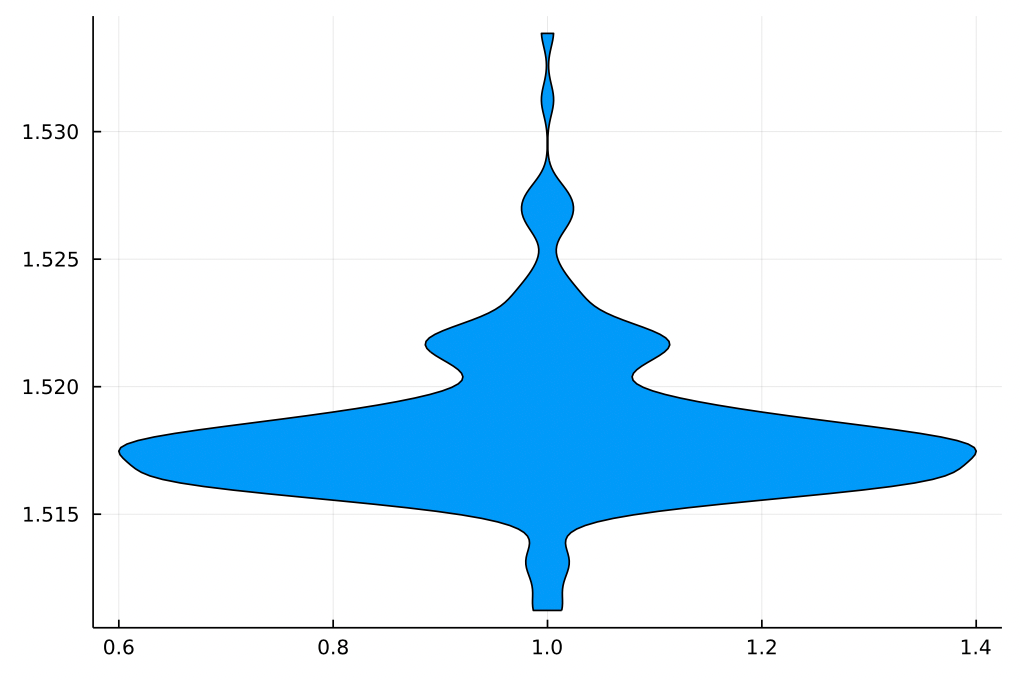
一个直方图,其条形图根据目标值进行着色,此外还显示了特征值与所得玻璃类型之间的关系。为此,我们可以使用直方图功能(也来自统计数据;请参阅图下面的朱莉娅代码):

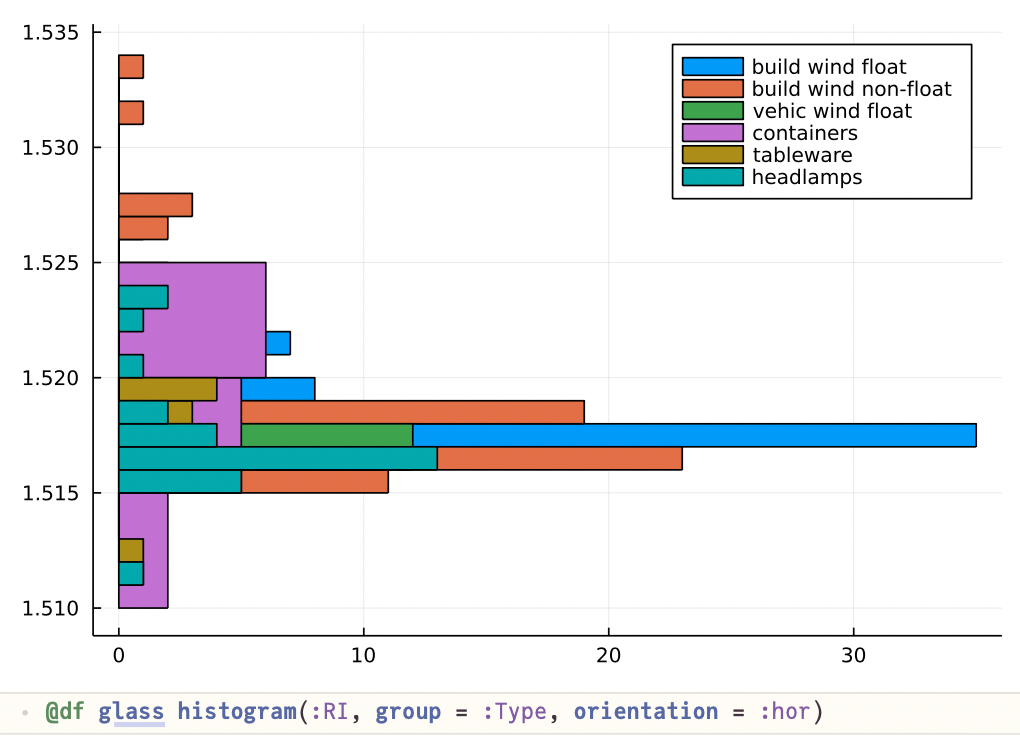
特征NA…铁
我们可以为其余功能做同样的事情NA…铁。小提琴图的一个很好的替代方法是描绘分布的一个箱形图。有时,小提琴情节会提供更多的洞察力,有时是一个箱形图。因此,我们最好两者兼而有之。如果我们并排绘制每个特征的所有三个图类型,我们可以轻松比较它们,从而导致以下图:图:


朱莉娅(Julia)生产该地块网格的代码如下:
前三行具有相似的结构:每条线都会创建一个图表(首先是小提琴,然后是框图,最后是直方图)。同样,我们为此目的使用“理解”:我们从2到9迭代,因为我们希望为该列的第2至9列图表玻璃数据框。对于这些列中的每一个,我们创建了相应的图(以上述为特征的方式相同RI)带有适当的参数(每个图都会获取,例如功能名称为其XLABEL)。
这阴谋函数(绘制整个网格;第7行)采用一系列子图作为参数,并根据网格排列布局参数(这里是8 x 3网格)。因此,我们必须创建一个适当的数组,该数组包含正确顺序的子图(即,对于每种材料,小提琴图,一个箱形图和直方图)应用以下步骤(第5行中的代码):
HCAT连接三个阵列小提琴,,,,盒子和Hampos因此创建一个8 x 3-matrix的图(每种图表的一列)- 由于朱莉娅矩阵以列前阶处理,我们将尺寸切换
置换的创建一个3 x 8-matrix(因此NA在第一列中,毫克在第二列等中) - 最后,我们必须将矩阵“将”矩阵“弄平”(根据需要
阴谋) 使用vec。
相关性
在处理数值属性时,总是重要的是要知道,是否以及它们的密切相关性,因为某些模型与密切相关的属性无法很好地工作。
除此之外,两个属性之间存在很强的相关性,这表明其中一个可能是多余的,因为它不会带来太多其他信息。这些知识可用于减少功能数量,从而对训练和评估模型进行更可行的计算。
相关矩阵
功能Cor(从Statsplots)以矩阵的形式为我们提供所需的信息,并具有每个特征配对的相关性(所谓的相关矩阵):


与往常一样,可视化使数字更容易理解。在这种情况下,热图是适当的图类型(我们使用它创建热图从统计数据)。由于相关矩阵是对称的,因此足以可视化下部的下部(可以使用下三角来自线性性包裹;请参阅图下面的朱莉娅代码)。颜色尺度:tol_sunset用于热图,来自色化学包裹。

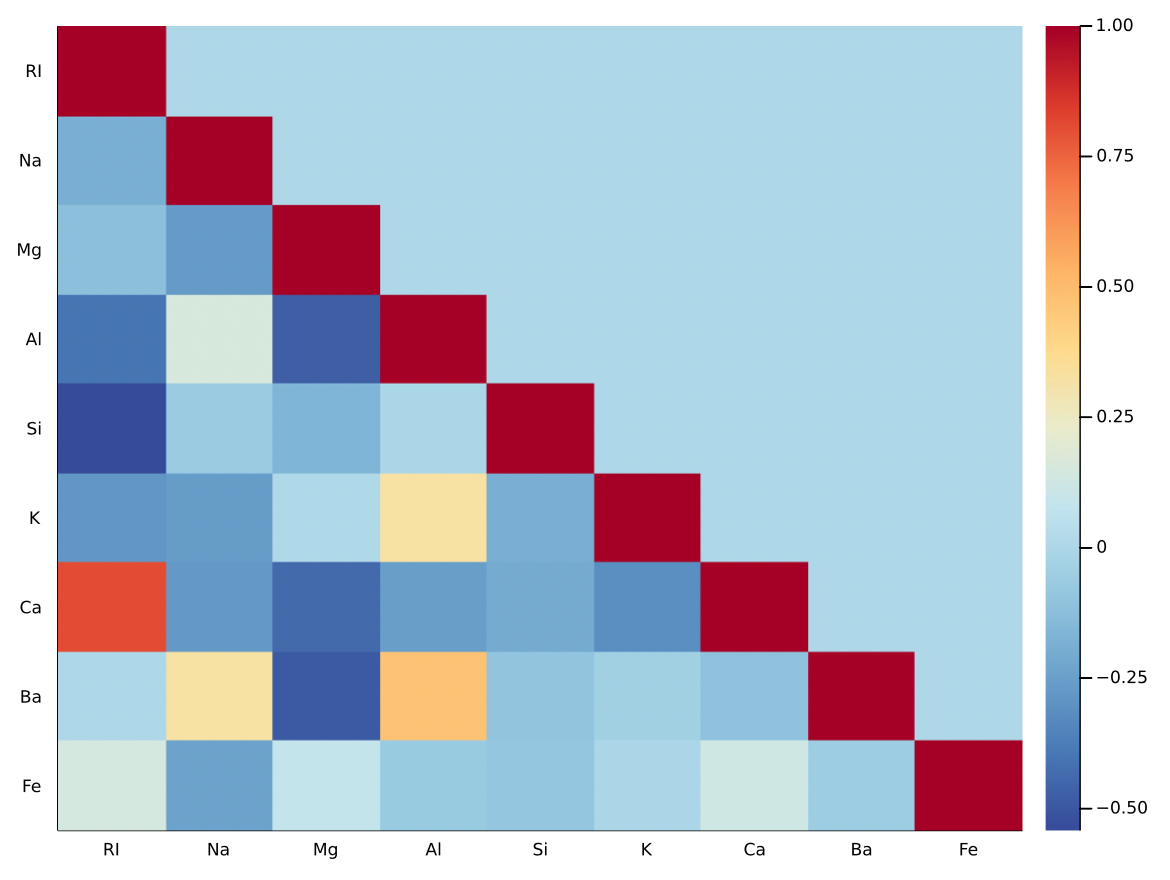
热图(下三角形(cor_mat),yflip = true,
seriescolor =:tol_sunset,
Xticks =(1:9,col_names [1:9]),
yticks =(1:9,col_names [1:9])))
从热图(和相关矩阵)可以看出,不同玻璃属性之间的最强正相关是:
- CA/RI→0.810403
- BA/AL→0.479404
- BA/NA→0.326603
- K/Al→0.325958
…当我们看数字时,只有前两个真的很“强”。
可以观察到明显的负相关:
- si/ri = -0.542052
- ba/mg = -0.492262
- al/mg = -0.481798
- CA/MG = -0.443750
相关图和角图
以下图提供了对不同属性配对之间的相关性的更详细的见解:
- 这相关图在下半部显示一个散点图(每个都有相应的SD线)和图表上半部分的热图。散点图在蓝色和中性的蓝色和中性相关性中显示出正相关。
- 这角图(以紧凑的形式以紧凑的形式)显示与相关图在图的下半部分。另外,它在顶部和右边缘显示每个属性的直方图。



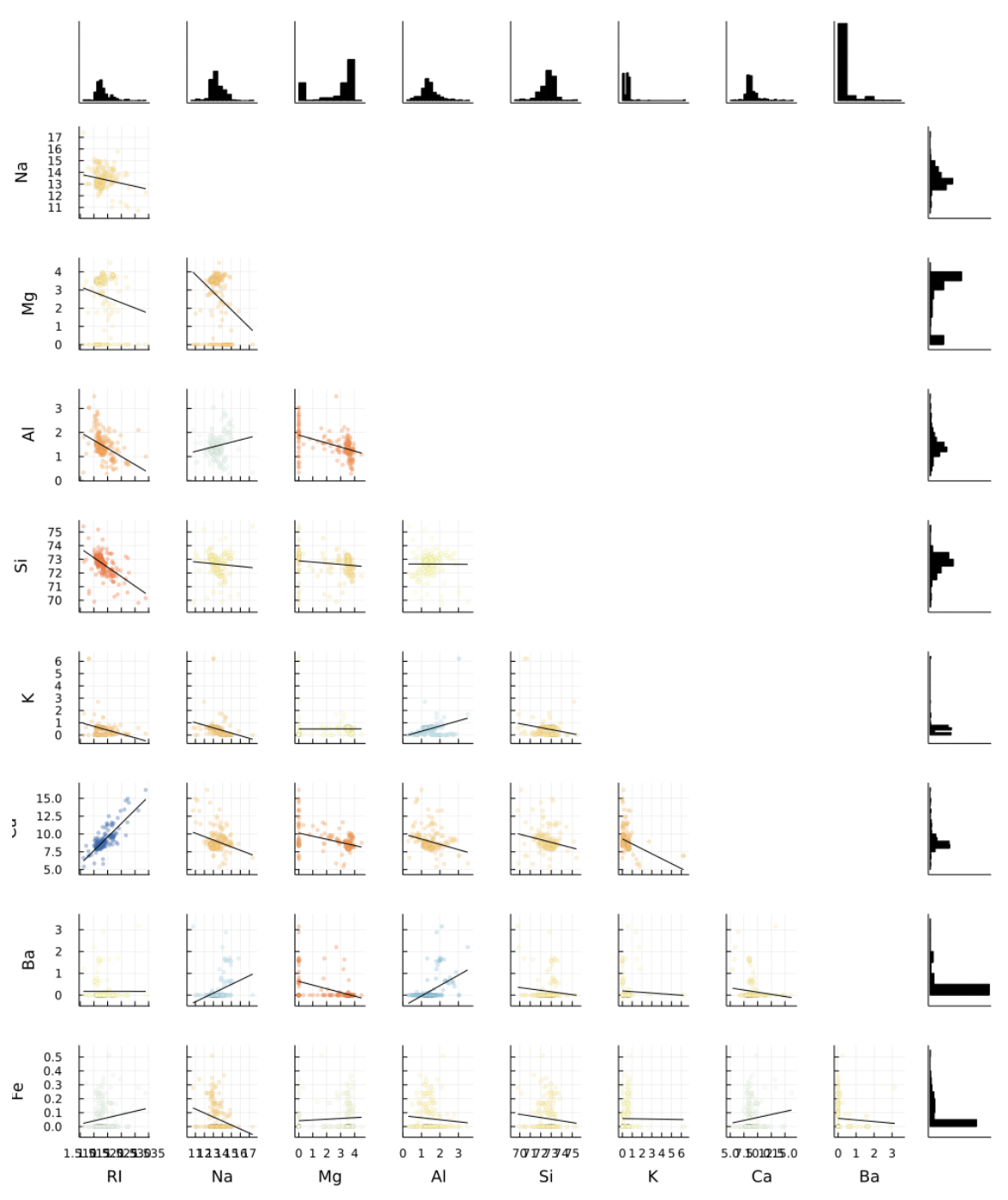
这些图中的每个图都仅使用一行朱莉娅代码,使用了统计数据如下:
@DF玻璃Corrlot(Cols(1:9))
@DF玻璃角图(Cols(1:9),compact = true)
结论
上面的示例显示了如何仅使用几行代码来执行典型的ML工作流程的重要步骤。教程的第二部分继续这一旅程,重点是培训,预测和评估等步骤。
还清楚地清楚了如何轻松地组合来自不同朱莉娅包装的功能,即使它们是独立开发的,它们也如何合作。教程的第三部分将解释这种合成性的内部工作。所以请继续关注!
当然,只有这些示例才能刮擦表面。有关更多信息,请参见下面给出的资源。
更多信息
- 在朱莉娅(Julia)用于数据分析及以后,朱莉娅(Julia)的创作者斯特凡·卡平斯基(Stefan Karpinski)解释了朱莉娅(Julia)和设计背后的理由的主要优势。在为什么朱莉娅?-对朱莉娅(Julia)编程的功能和好处的高级描述蒂姆·圣洁(Tim Holy),您将获得对同一主题的更深入的处理。
- Bogumil Kaminski教授提供了全面的数据范围的教程在2021年的朱利安(Juliacon)上。他是该包装的主要作者。
- 可以找到绘图的文档和教程。这里。有几个诸如statsplots.jl之类的附加软件包。













