实践教程
实践强化学习课程:第2部分


欢迎来到我的强化学习课程❤️
这是我关于强化学习的实践课程的第2部分,它将带你从0到HERO♂️。
如果你错过了第1部分,请阅读它以获得强化学习术语和基础知识。
今天我们要解决第一个学习问题……
我们要培训一名出租车司机!
嗯,一个简化版的出租车环境,但在一天结束的时候是出租车。
我们将使用Q-learning,这是最早和使用最多的RL算法之一。
当然,还有Python。
所有的c这节课的颂歌来了这个Github回购.Git复制它来跟随今天的问题。


第2部分
内容
- 出租车驾驶问题
- 环境、行动、状态、奖励
- 随机代理基线
- q学习的代理
- 超参数调优️
- 回顾✨
- 家庭作业
- 接下来是什么?❤️
1.出租车驾驶问题
我们将教一个代理使用强化学习来驾驶出租车。
在现实世界中驾驶出租车是一项非常复杂的任务。正因为如此,我们将在一个简化的环境中工作,其中包括一个优秀出租车司机应该做的3件基本事情,即:
- 接载乘客并将他们送到预定目的地。
- 安全驾驶,意味着没有车祸。
- 在尽可能短的时间内驾驶它们。
我们将使用OpenAI Gym的一个环境,称为Taxi-v3环境。

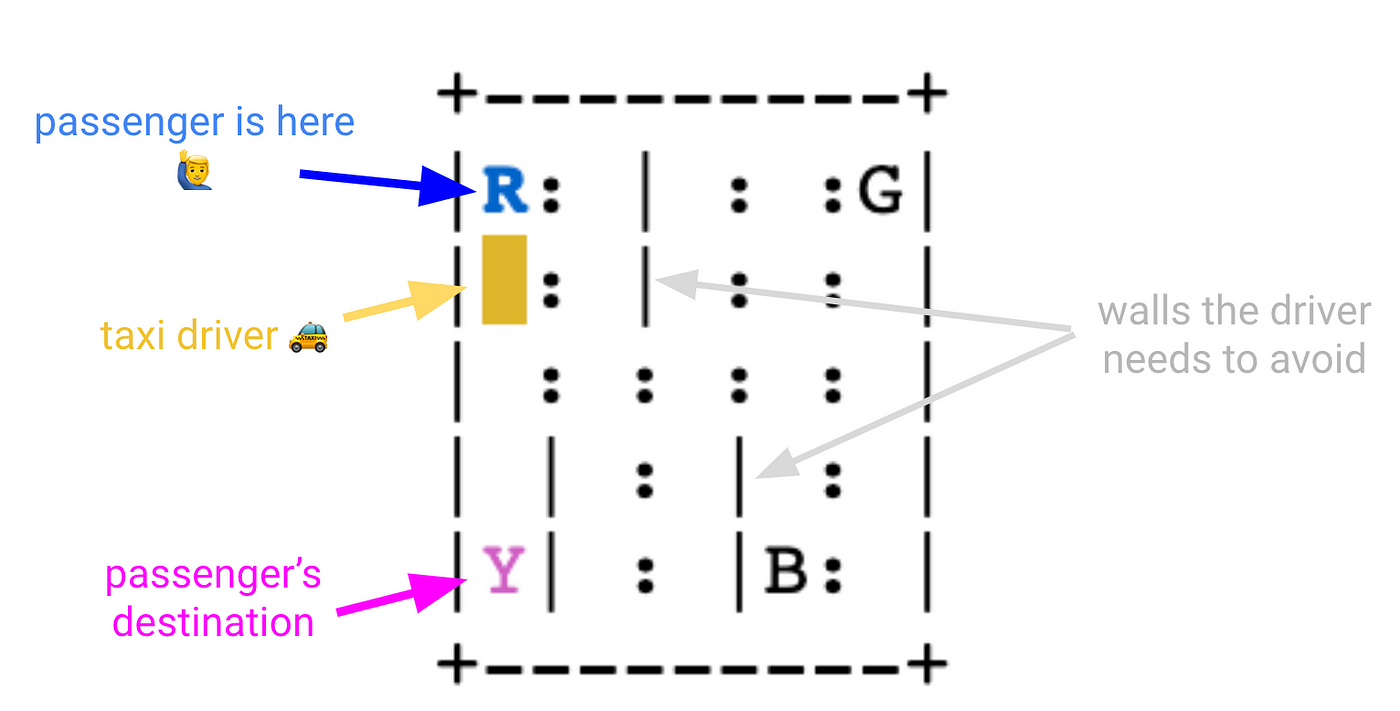
网格世界中有四个指定的位置,分别由R(ed)、G(reen)、Y(黄色)和B(lue)表示。
当情节开始时,出租车从一个随机的广场出发,乘客在一个随机的位置(R, G, Y或B)。
出租车开到乘客所在的地点,搭载乘客,开到乘客的目的地(四个指定地点中的另一个),然后让乘客下车。在这样做的同时,我们的出租车司机需要小心驾驶,以避免撞到任何墙壁,标记为|.一旦乘客下车,这一集就结束了。
这就是我们今天要构建的q-learning代理如何驱动的:
在此之前,让我们充分理解这个环境的行为、状态和奖励是什么。
2.环境、行动、状态、奖励
让我们首先加载环境:


什么是行动代理可以在每个步骤中进行选择?
0降低1抬高2开车吧3.开车离开了4搭载乘客5让乘客下车


和州?
- 25个可能的出租车位置,因为世界是一个5x5的网格。
- 乘客可能的5个位置,分别是R, G, Y, B,加上乘客在出租车里的情况。
- 4目的地地点
那么25 x 5 x 4 = 500个州


是什么奖励?
- -1默认每步奖励。
为什么是-1而不是简单的0?因为我们希望通过惩罚每一个额外步骤来鼓励代理花费最短的时间。这就是你对出租车司机的期望,不是吗? - + 20将乘客送到正确的目的地给予奖励。
- -10在错误地点执行拾取或放下任务的奖励。
你可以阅读奖励和环境转换(state, action)→next_state从env.P。


顺便说一下,您可以在每个状态下渲染环境以再次检查这一点env。P向量是有意义的:
从状态= 123
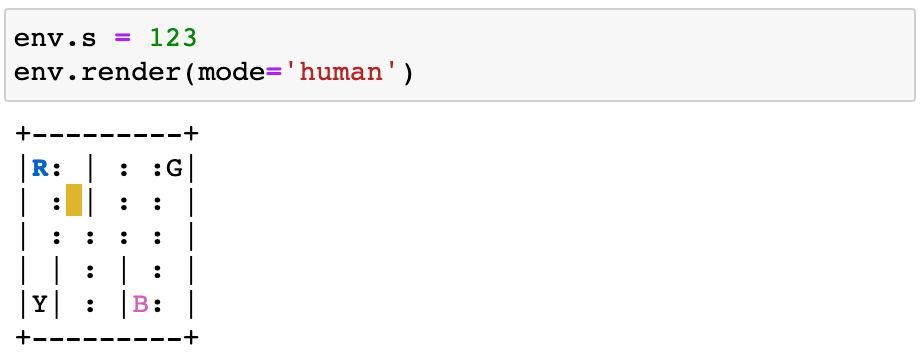
特工向南移动action = 0为了到达状态= 223
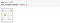
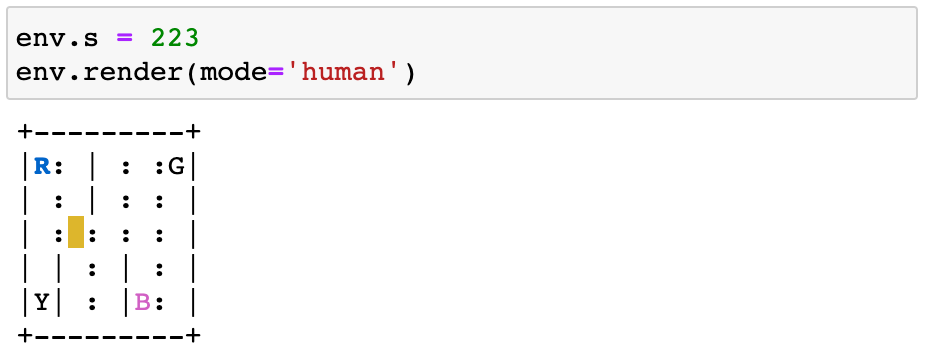
奖励是-1,因为这一集既没有结束,也没有司机错误地拾取或丢弃。
3.随机代理基线
笔记本/ 01 _random_agent_baseline.ipynb
在开始实现任何复杂的算法之前,您应该始终构建一个基线模型。
这个建议不仅适用于强化学习问题,也适用于一般的机器学习问题。
直接跳进复杂/花哨的算法是非常诱人的,但除非你真的有经验,否则你会失败得很惨。
Let’s use a random agent as a baseline model.


我们可以看到这个代理对于给定的初始值是如何执行的状态= 198

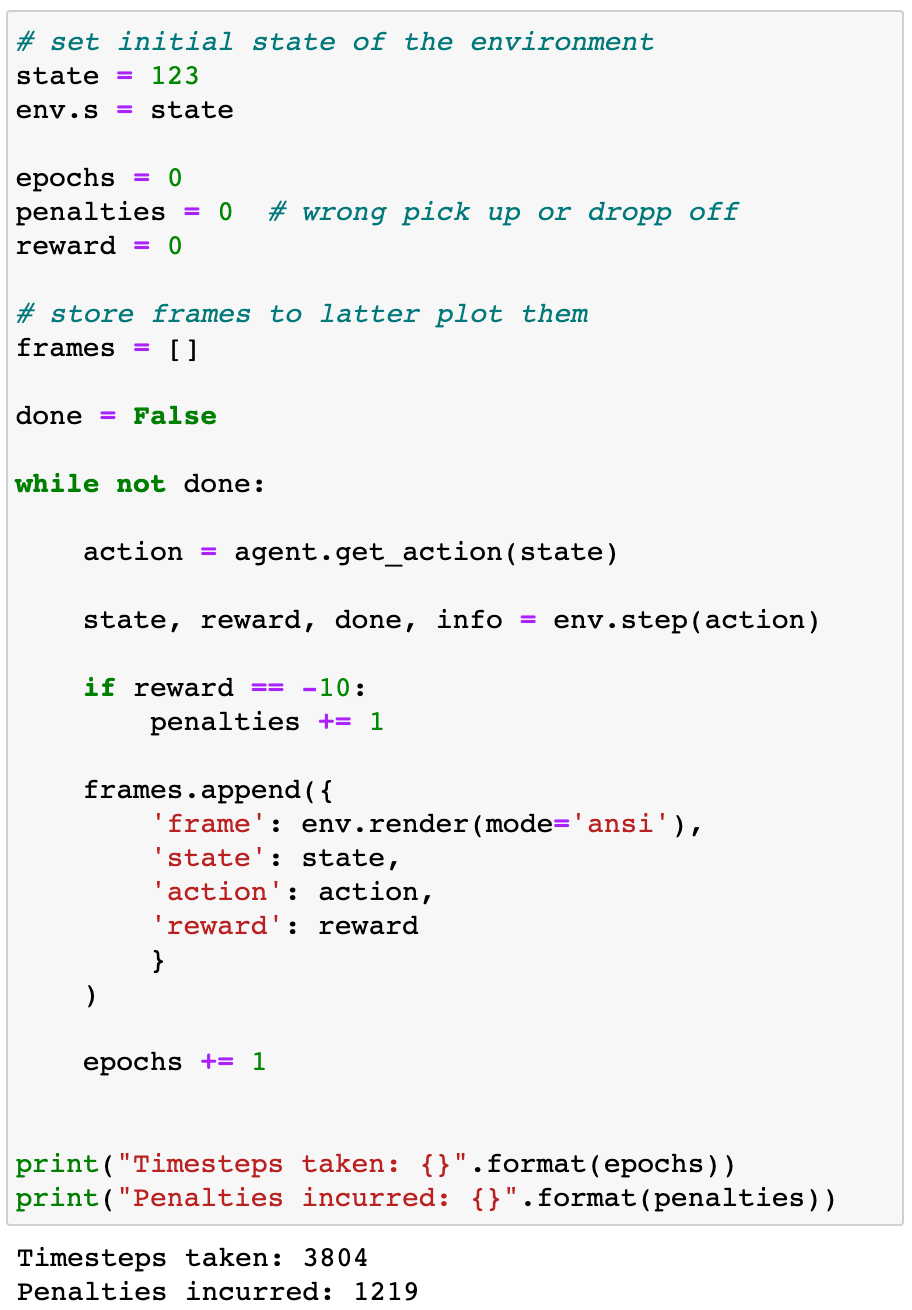
3804步是很多的!
请自己观看这个视频:
为了获得更有代表性的性能度量,我们可以重复相同的评估循环n = 100每次都以随机状态开始。

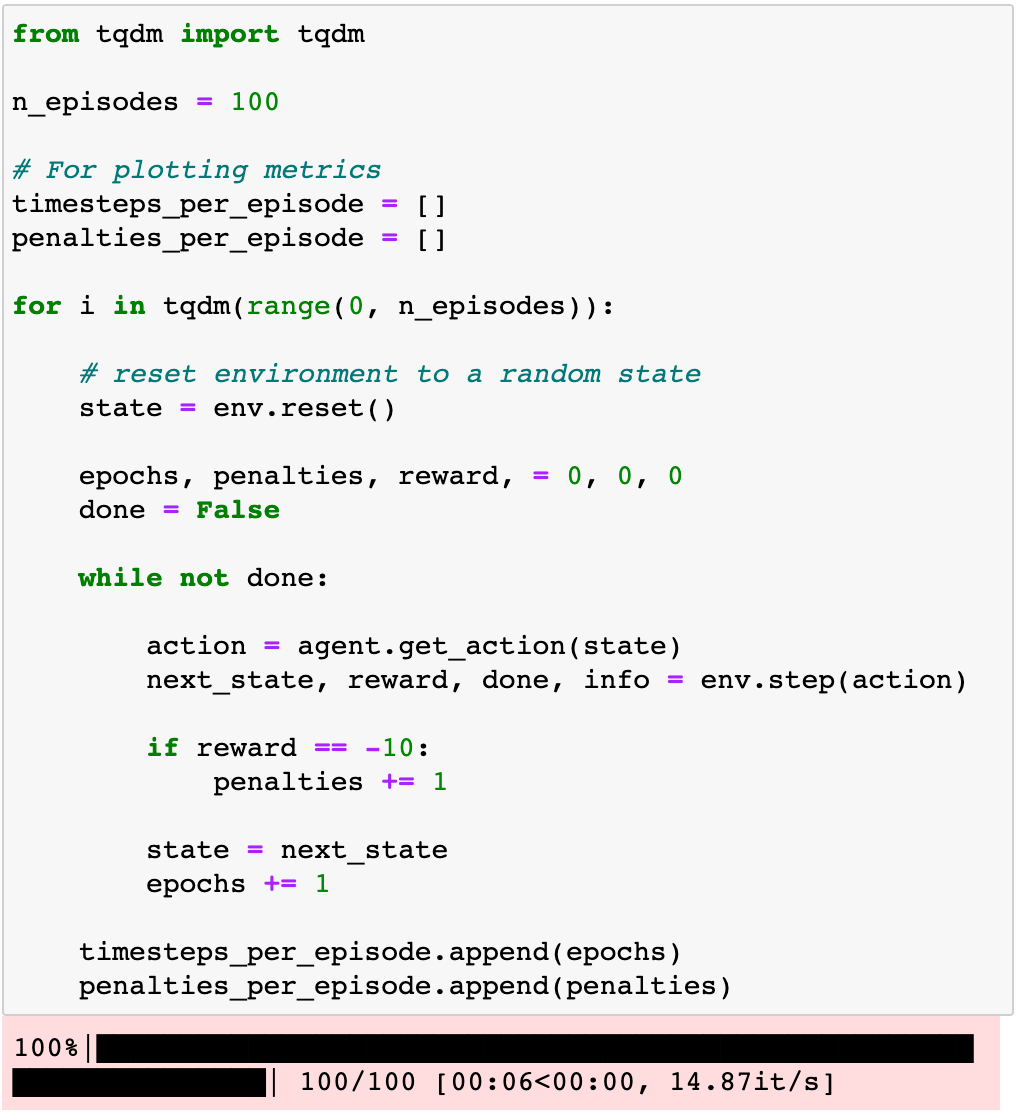
如果你绘图timesteps_per_episode而且penalties_per_episode您可以观察到,当代理完成更多的集时,它们都没有减少。换句话说,代理没有学习任何东西。

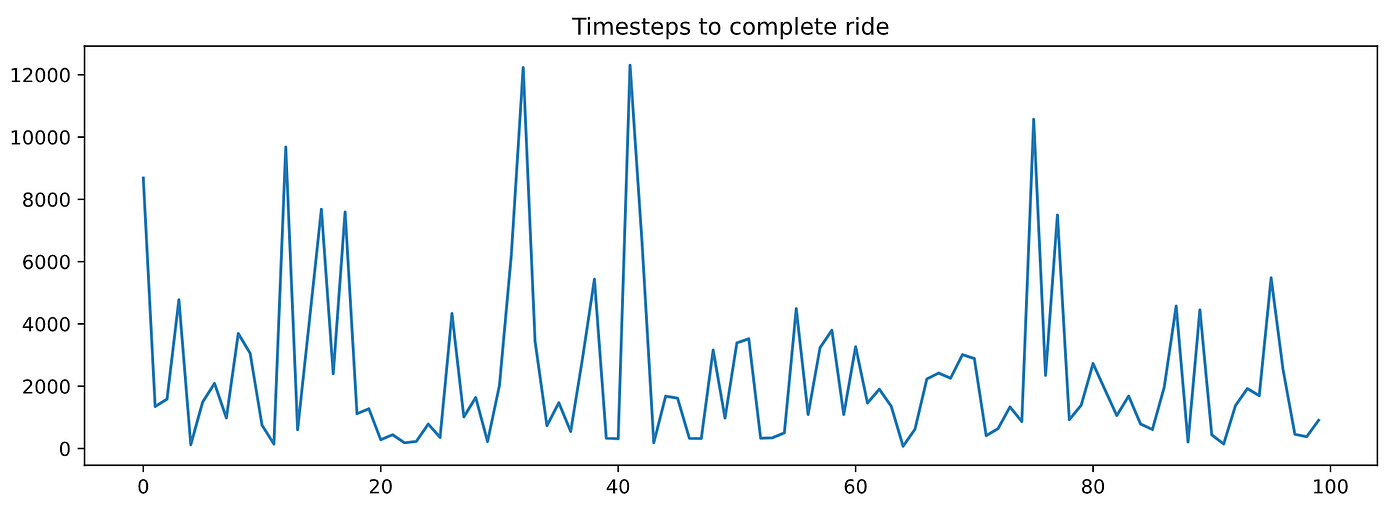

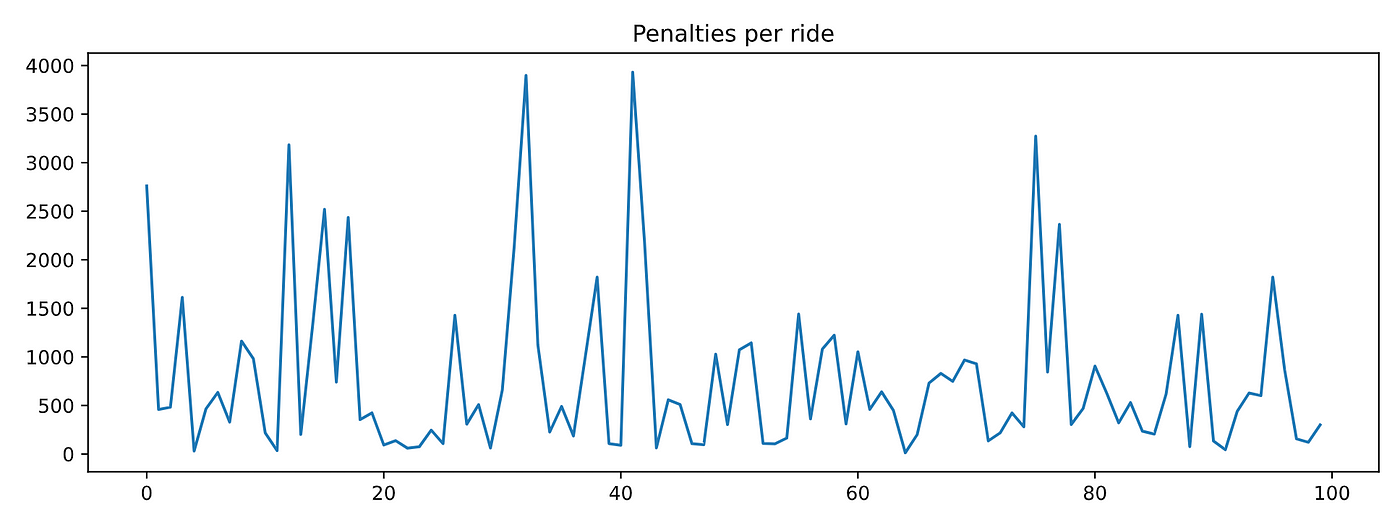
如果你想要总结性能统计,你可以取平均值:


实现学习的代理是强化学习的目标,也是本课程的目标。
让我们使用Q-learning实现我们的第一个“智能”代理,Q-learning是现存最早和使用最多的RL算法之一。
4.q学习的代理
q学习的(通过克里斯步进而且彼得·达扬)是寻找最优q值函数的算法。
正如我们在第1部分,为q值函数问(,)与策略关联π在状态下,代理期望得到的总报酬是多少年代代理采取行动一个并遵循政策π之后。
最优q值函数Q * (,)q值函数是否与最优策略相关π*。
如果你知道Q * (,)你可以推断π*:也就是说,你选择下一个动作,使当前状态s的Q*(s, a)最大化。
Q-learning是一种迭代算法,用于计算更好的逼近最优q值函数Q * (,),从任意的初始猜测开始问⁰(年代)

在表格环境中Taxi-v3对于有限数量的状态和动作,q函数本质上是一个矩阵。它的行和状态一样多,列和操作一样多,即500 x 6。
好吧,但是如何从Q⁰出发计算下一个近似Q¹(s, a)呢?
这是q学习的关键公式:


当q-agent在环境中导航并观察下一个状态时年代和奖励r,用这个公式更新q值矩阵。
学习率是多少在这个公式中?
的学习速率(通常在机器学习中)是一个很小的数字,它控制q-函数的更新有多大。你需要调优它,因为太大的值会导致不稳定的训练,太小的值可能不足以逃脱局部最小值。
这个折现因子?
的折现系数是一个介于0和1之间的(超)参数,它决定了我们的代理相对于近期未来的奖励有多关心遥远未来的奖励。
- 当=0时,代理只关心即时奖励最大化。就像在生活中发生的那样,最大化即时奖励并不是获得最佳长期结果的最佳方法。这也发生在RL代理中。
- 当=1时,智能体根据未来所有奖励的总和来评估它的每一个行动。在这种情况下,代理同样看重即时奖励和未来奖励。
贴现因子通常是一个中间值,例如0.6。
总之,如果你
- 训练足够长时间
- 有不错的学习率和折扣率
- 智能体探索了足够的状态空间
- 然后用q学习公式更新q值矩阵
你的初始近似最终会收敛到最优的q矩阵。瞧!
让我们为Q-agent实现一个Python类。
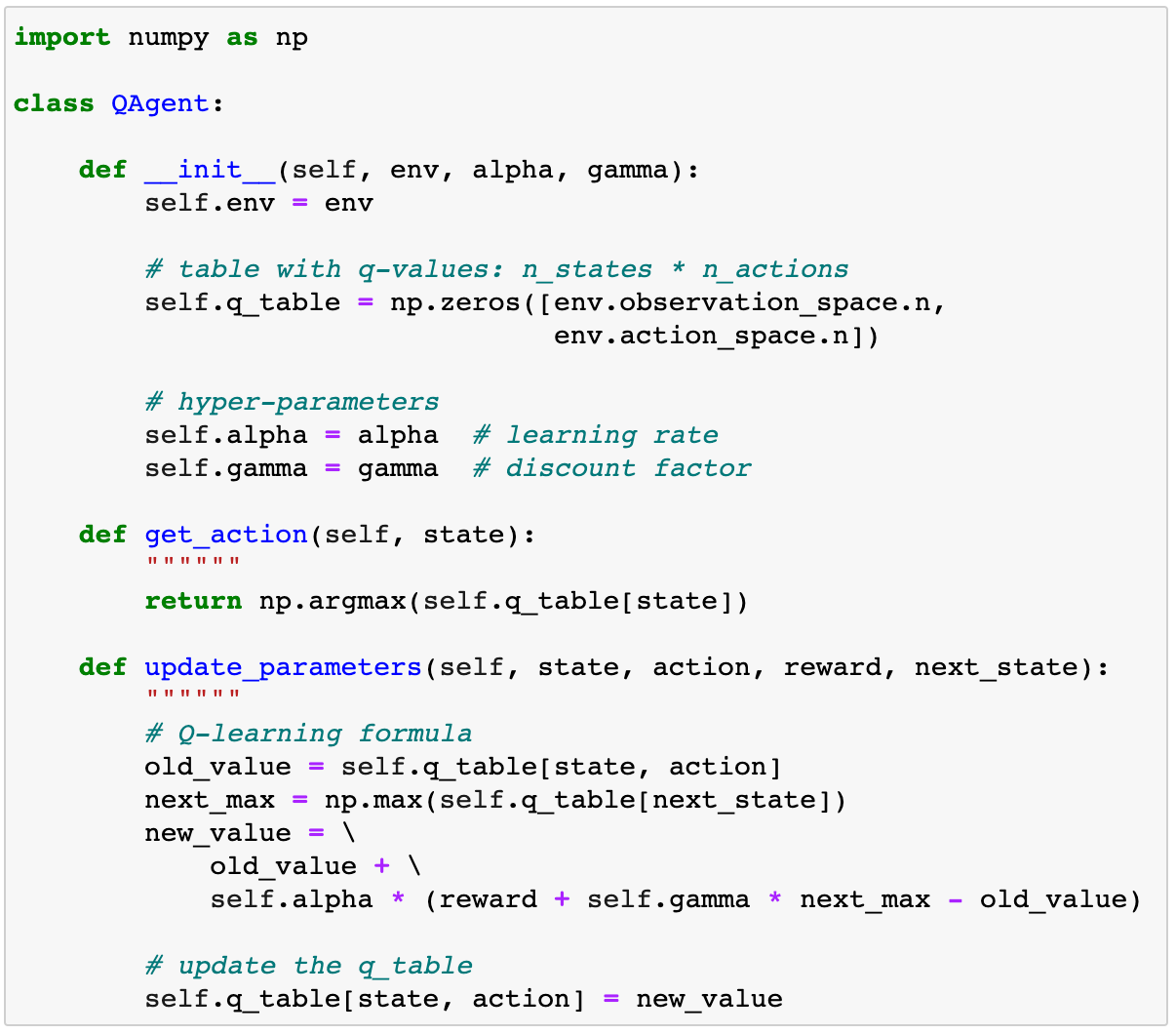
的API与RandomAgent上面,但是有一个额外的方法update_parameters ().这个方法取转移向量(状态,动作,奖励,next_state)并更新q值矩阵近似self.q_table使用上面的q学习公式。
现在,我们需要把这个代理插入到一个训练循环中,并调用它update_parameters ()方法。
另外,请记住,我们需要保证代理充分地探索状态空间。还记得我们讨论过的勘探-开发参数吗第1部分?这就是当ε参数进入游戏。
让我们训练探员N_episodes = 10,000和使用= 10%


和情节timesteps_per_episode而且penalties_per_episode



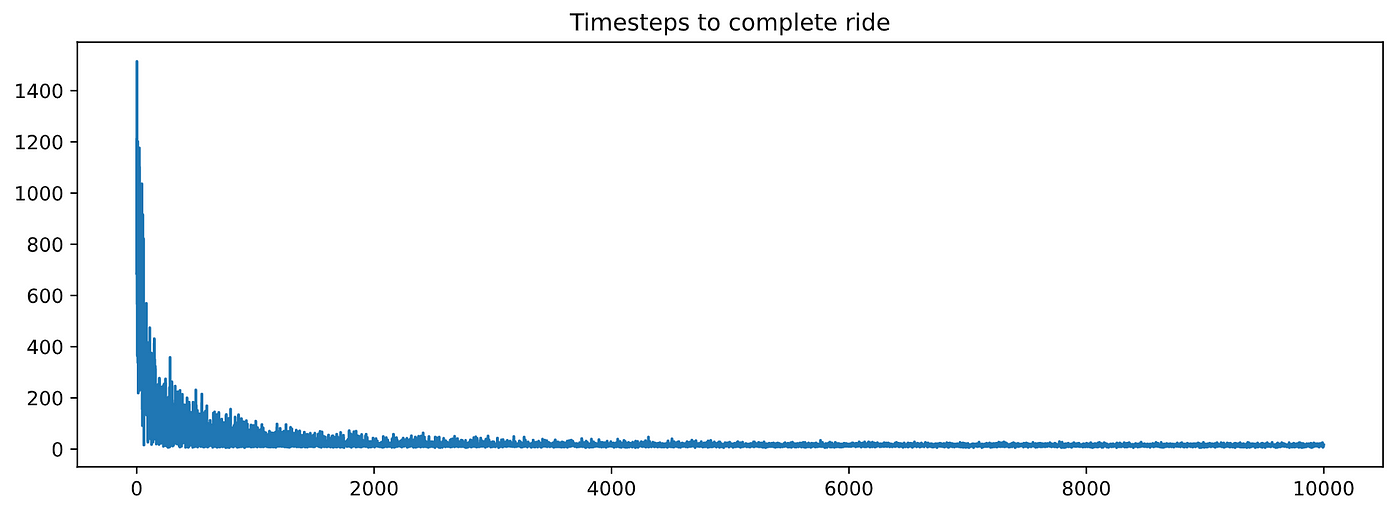


好了!这些图表看起来比RandomAgent.这两个指标都随着训练而下降,这意味着我们的代理正在学习。
我们实际上可以看到代理是如何从相同的位置开始驱动的状态= 123就像我们用的RandomAgent.


如果您想比较硬数字,您可以评估q-agent在100个随机事件上的性能,并计算时间戳和所引起的惩罚的平均数量。
再讲一点贪婪政策
当你评估代理时,使用一个积极的做法仍然是很好的ε价值,而不是= 0。
W怎么这样呢?我们的探员训练有素吗?为什么我们在选择下一步行动时需要保留这种随机性?
原因是为了防止过拟合。即使是如此小的状态,行动空间也在Taxi-v3(即500 x 6),很可能在训练期间,我们的代理没有访问足够多的某些州。
因此,它在这些状态下的性能可能不是100%最优的,导致代理“陷入”一个几乎无限的次优行为循环中。
如果epsilon是一个很小的正数(例如5%),我们可以帮助代理逃脱这些次优行为的无限循环。
通过在计算时使用小的,我们采用了所谓的epsilon-greedy策略.
让我们来评估一下我们训练有素的探员N_episodes = 100使用= 0.05。观察这个循环看起来和上面的火车循环几乎一模一样,但是没有调用update_parameters ()




这些数字看起来比RandomAgent。
我们可以说我们的代理已经学会了驾驶出租车!
q学习为我们提供了一种计算最佳q值的方法。但是,超参数呢α,γ而且ε?
我给你选的,很随意。但在实践中,您需要针对RL问题对它们进行调优。
让我们来探索它们对学习的影响,以更好地直观地了解正在发生的事情。
5.超参数调优️
笔记本/ 03 _q_agent_hyperparameters_analysis.ipynb
让我们用不同的值来训练q-agentα(学习率)和γ(折现系数)。至于ε我们保持在10%。
为了保持代码简洁,我在里面封装了q-agent定义src / q_agent.py训练循环在培训()函数src / loops.py




让我们画出步伐每集表示超参数的每个组合。




这个图表看起来很艺术,但是有点太嘈杂了。
你可以观察到的是Alpha = 0.01学习变慢了。α(学习率)控制我们在每次迭代中更新q值的多少。数值过小意味着学习速度较慢。
让我们抛弃Alpha = 0.01对每个超参数组合进行10次训练。我们求平均值步伐对于每一集的数量,从1到1000,使用这10个运行。
我创建了这个函数train_many_runs ()在src / loops.py为了让笔记本代码更干净:



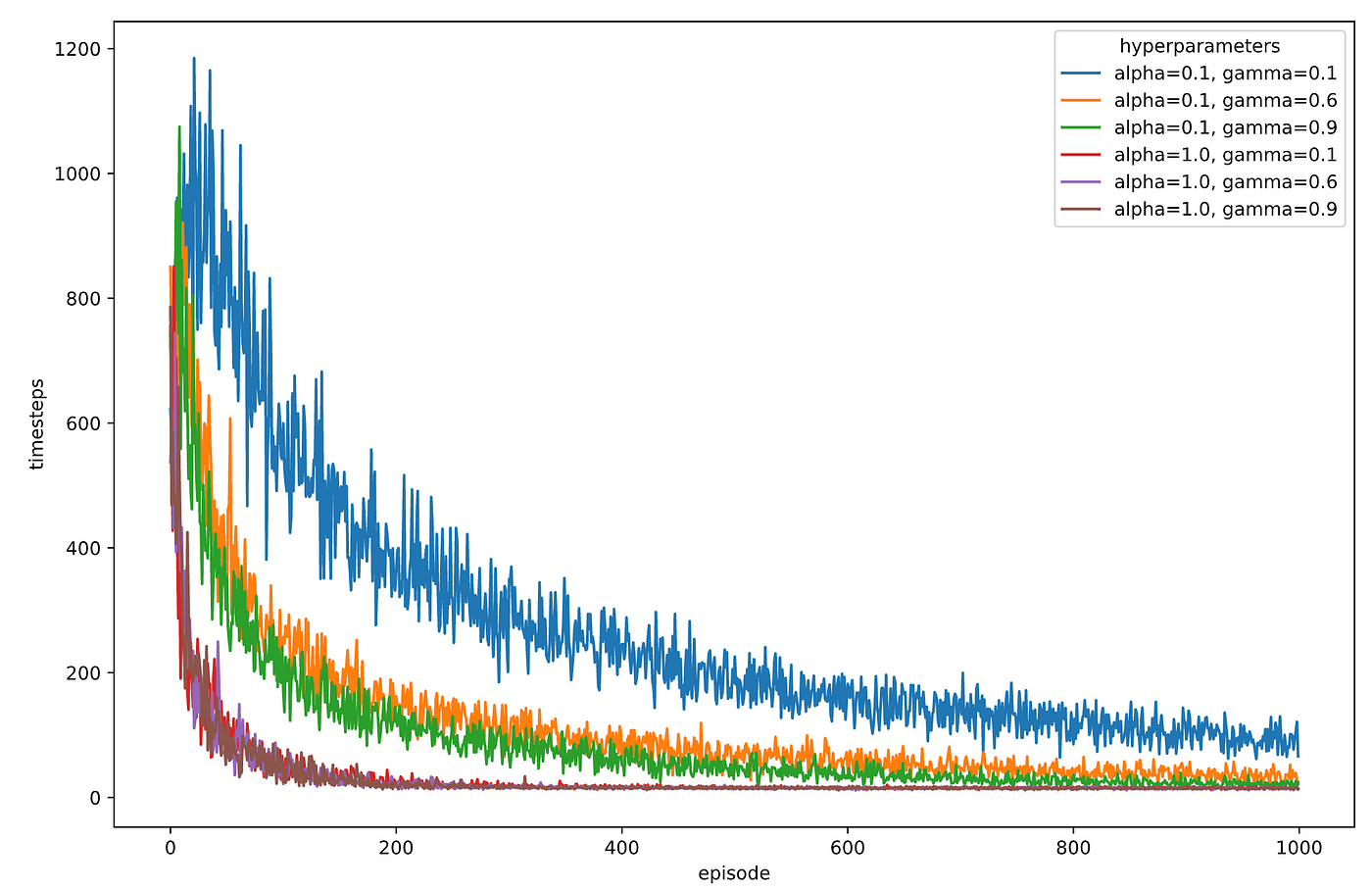
它看起来像Alpha = 1.0价值是最有效的,而γ似乎影响不大。
恭喜你!您已经调整了本课程的第一次学习速度
调优超参数可能非常耗时且乏味。有一些优秀的库可以自动执行我们刚刚遵循的手动流程,比如Optuna但这是我们在后面的课程中会用到的。就目前而言,享受我们刚刚发现的加速训练吧。
等等,这是怎么回事= 10%我告诉过你要相信我的事
当前10%的价值是最好的吗?
我们自己去检查一下吧。
我们选择最好的α而且γ我们发现,即。
Alpha = 1.0= 0.9我们本可以采取0.1或0.6)
训练不同的人= [0.01, 0.1, 0.9]

然后画出结果步伐而且处罚曲线:




如你所见,两者都有= 0.01而且= 0.1它们似乎同样有效,因为它们在探索和开发之间取得了正确的平衡。
另一方面,= 0.9的值太大,导致训练过程中“太多”的随机性,并阻止我们的q-矩阵收敛到最优值。观察性能如何在左右停滞250年步伐每一集。
一般来说,最佳的策略选择εhyper-parameter是进步epsilon-decay.也就是说,在训练开始时,当智能体对其q值估计非常不确定时,最好访问尽可能多的状态,为此,一个较大的ε很好(例如50%)
随着训练的进行,智能体改进了它的q值估计,探索那么多不再是最优的。相反,通过减少ε代理可以学习完善和微调q值,使它们更快地收敛到最优值。太大的ε会引起收敛问题吗= 0.9.
我们会在课程中调整,所以现在我不会坚持太多。再一次,享受我们今天所做的。这是非常了不起的。


6.回顾✨
恭喜你(可能)解决了你的第一个强化学习问题。
以下是我想让你在睡觉时牢记的关键知识:
- 强化学习问题的难度与可能的动作和状态的数量直接相关。
Taxi-v3是一个表格环境(即有限数量的状态和动作),所以它是一个简单的。 - Q-learning是一种学习算法,适用于表格环境。
- 无论你使用什么RL算法,你都需要调整超参数,以确保你的智能体学会最佳策略。
- 调优超参数是一个耗时的过程,但对于确保我们的代理学习是必要的。随着课程的推进,我们会在这方面做得更好。
7.家庭作业
这就是我想要你做的:
- Git克隆回购到您的本地机器。
- 设置这节课的环境
01 _taxi。 - 开放
01 _taxi / otebooks / 04 _homework.ipynb试着完成两个挑战。
我称它们为挑战(不是练习),因为它们并不容易。我希望你尝试一下,亲自动手,(也许)会成功。
在第一个挑战中,我希望你能更新培训()函数src / loops.py接受一个依赖于情节的。
在第二个挑战中,我希望您升级Python技能并实现并行处理以加速超参数实验。
像往常一样,如果你陷入困境,你需要反馈,请给我写信plabartabajo@gmail.com。
我非常乐意帮助你。
8.接下来是什么?❤️
在下一部分中,我们将解决一个新的RL问题。
一个更难的问题。
使用一种新的RL算法。
使用大量的Python。
而且还会有新的挑战。
和乐趣!
再见!
你想成为一名(甚至)更好的数据科学家,并访问有关机器学习和数据科学的顶级课程吗?
跟我来在媒介。
有一个伟大的一天❤️
加索尔