实践教程
实践强化学习课程:第1部分
从零到英雄,一步一步。


欢迎来到我的强化学习课程!❤️
让我们从基本面这个美丽的路径走到最前沿的强化学习(RL),按部就班,Python示例代码和教程,在一起!
第一部分介绍了最低限度的概念和理论需要开始这段旅程。然后,在以后的各个章节,我们将解决不同的问题,越来越困难。
最终,最复杂的RL问题涉及的混合强化学习算法,优化和深入学习。
你不需要知道l收入(DL)跟随本课程。我会给你足够的背景让你熟悉DL哲学和了解现代强化学习成为一个至关重要的因素。
第1部分
在第一节课中,我们将介绍基本的强化学习和例子,0数学,Python。
内容
- 强化学习问题是什么?
- 政策和价值函数。
- 如何生成训练数据?
- Python样板代码。
- 回顾✨
- 家庭作业
- 接下来是什么?❤️
让我们开始!
1。强化学习问题是什么?
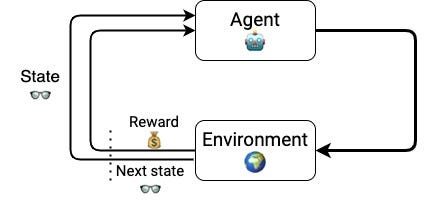
强化学习(RL)是一个机器学习的领域(ML)关心学习问题
一个聪明的代理需要学习,通过试验和错误,如何行动内部和环境为了最大化累积奖励。
强化学习是一种接近人类和动物如何学习机器学习。
什么是代理?和一个环境?完全代理可以采取这些行动是什么?和奖励?你为什么说累积奖励?
如果你问自己这些问题,你是在正确的轨道上。
术语的定义我给介绍一些你可能不熟悉。事实上,他们是故意模棱两可。这种普遍性使RL适用于各种看似不同的学习问题。这是数学建模背后的哲学,呆在RL的根源。
让我们看一看一些学习问题,通过强化学习的镜头,看看它们。
示例1:学走路♀️♀️
作为孩子的父亲,最近开始走路,我不能停止问自己,他是怎么学习呢?


机器学习作为一个工程师,我幻想理解和复制,难以置信的学习曲线与软件和硬件。
让我们试着使用RL成分模型这种学习问题:
- 的代理是我儿子,凯。他想站起来走路。他的肌肉足够强大在这个时间点有机会。顺序为他的学习问题是:如何调整他的身体位置,包括几个角度对他的腿,腰部,背部,手臂来平衡他的身体,而不是下降。
- 的环境他周围的物质世界,包括物理定律。最重要的是重力。没有重力学走路的问题将大大改变,甚至成为无关紧要:为什么你想要走进一个世界,在那里你可以飞吗?在这种学习另一个重要的法律问题是牛顿第三定律,告诉,如果你用简单的字都在地板上,地板会打你用同样的力量。哎哟!
- 的行动这些身体中的所有更新的角度,确定他的身体位置和速度作为他开始追逐的东西。相信他可以做其他的事情在同一时间,喜欢模仿牛的声音,但这可能不是帮助他完成他的目标。我们忽略这些行动框架。添加不必要的行为不会改变模式的步骤,但它使得更难解决的问题。
- 的奖励他收到来自大脑的刺激,让他快乐或使他感到疼痛。有消极的奖励时,他经历摔倒在地板上,这是身体疼痛也许挫折紧随其后。另一方面,有一些对他的幸福的贡献积极的事情,就像幸福的快的地方,或外部刺激,来自于我和我的妻子Jagoda当我们说“好工作!”或“万岁!“他尝试和边际改善。
一个重要和明显的评论是,凯不需要学习牛顿的物理学站起来走路。他将通过观察学习状态的环境,采取一个行动,从这个环境和收集奖励。他不需要学习环境的模型来实现他的目标。
一点回报
凯的奖励是一个信号,他一直在做的事情对他的学习是好还是坏。他需要新的行为和体验痛苦或幸福,他开始调整他的行为收集更多积极的反馈和更少的消极反馈。换句话说,他学习
一些操作对婴儿看起来很吸引人,就像试图跑到兴奋的得到提升。然而,他很快就学会了,在一些(或大多数)的情况下他最终落在他的脸上,经历一段时间的痛苦和泪水。这就是为什么智能代理最大化累积奖励,而不是边际回报。他们贸易短期与长期的回报。行动将使立即奖励,但把我的身体在一个位置下降,并非最优。
伟大的幸福之后,更大的痛苦不是长期幸福的秘诀。这是婴儿往往比我们成年人的学习更容易。
的频率和强度奖励帮助代理学习的关键。非常罕见的(稀疏)反馈方式更难学习。想想看,如果你不知道你做什么是好是坏,你怎么学习?这是其中一个主要原因为什么有些RL问题比其他人更难。
奖励塑造是一个艰难的对于许多现实世界的RL问题建模决定。
示例2:学习演奏垄断像专业人士那样
小时候,我花了很多时间玩垄断与朋友和亲戚。好吧,谁没有?这是一个令人兴奋的游戏相结合的运气(你滚骰子)和策略。
垄断是一个房地产的棋盘游戏有两个八个玩家。你滚两个骰子移动,购买和交易属性和发展住宅和酒店。你从你的对手收集租金,我们的目标是让他们破产。

如果你进入这个游戏,你想找到聪明的方法来玩,你可以使用一些强化学习。
4 RL的成分是什么?
- 的代理是你,想的人赢得垄断。
- 你的行动是你看到的这个截图:
- 的环境游戏的当前状态,包括属性的列表,位置,和现金数量每个球员都有。还有你的对手的策略,这是你无法预测你的控制之外和谎言。
- 和奖励是0,除了在你最后的举动,+ 1的地方如果你赢得比赛,如果你破产和1。这个奖励制定有意义但难以解决的问题。正如我们上面所说的,更稀疏奖励意味着困难的解决方案。由于这个原因,其他的方式模型的奖励,使他们吵着稀疏的更少。
当你面对垄断的另一个人,你不知道他或她将如何玩。你所要做的就是自己玩。当你学习更好,你的对手也是如此(因为你),迫使你升级你的游戏继续获胜。你看到积极的反馈回路。
这种方法叫做self-play。它给了我们一个路径引导情报不使用外部专家的建议的球员。
Self-play之间的主要区别AlphaGo和AlphaGo零,两个模型由DeepMind玩围棋比任何人类。
示例3:学习开车
短短几十年(可能更少),机器将推动我们的汽车,卡车和巴士。


但是,如何?
学会开车是不容易的。驱动程序的目标是明确的:从A点到B点,为她和任何乘客舒适。
外部方面有很多的司机驾驶的挑战,包括:
- 其他司机的行为
- 交通标志
- 行人的行为
- 路面条件
- 天气条件。
- …甚至燃料优化(谁愿意花费额外的吗?)
与强化学习我们如何解决这个问题?
- 的代理是司机想要从A到B,舒适。
- 的状态环境的司机所观察到的很多东西,包括位置、速度和加速度的车,所有其他汽车,乘客,道路状况和交通标志。将这么大的一个向量的输入转换为一个适当的行动是具有挑战性的你可以想象。
- 的行动基本上是三:方向盘的方向,油门强度和断裂强度。
- 的奖励每个操作后的加权和开车时你需要平衡不同方面。下降到B点的距离带来了积极的奖励,同时增加一个负面。确保没有冲突,靠得太近(甚至碰撞)与另一辆车,甚至是一个行人应该有一个很大的负回报。同时,为了鼓励顺利开车,速度或方向急剧变化导致消极的奖励。
在这三个例子中,我希望以下表示RL元素以及它们如何一起玩是有道理的:
既然我们了解如何制定一个RL的问题,我们需要解决它。
如何?
继续阅读!
2。政策和价值函数
政策
代理选择行动她认为是最好的基于环境的当前状态。
这是代理的策略,通常被称为代理的政策。
一个政策是一个学习国家行为的映射。
解决强化学习基坑支护手段找到最好的政策。
政策是确定的每个状态映射到一个动作,


或随机当他们每个状态映射到一个概率分布在所有可能的行动。


随机这个词你经常读和听在机器学习和它的意思吗不确定的,随机。在不确定性高的环境中,如垄断滚动骰子,随机比确定性的政策。
有几种方法来计算这个最优政策。这些被称为政策优化方法。
价值函数
有时,根据具体问题,而不是直接试图找到最优政策,一个可以找到值函数与最优政策有关。
但是,值函数是什么吗?
在这之前,
在这种情况下价值是什么意思?
的价值是一个与之关联的编号,每个州年代环境的估计是多么好代理的状态年代。
这是累积奖励代理收集开始时的状态年代根据政策和选择行动π。
值函数是一个学习状态值的映射。
政策通常表示的价值功能

价值函数也可以对(动作、状态)映射到值。在这种情况下,他们被称为核反应能量功能。

最优值函数(或核反应能量函数)满足一个数学方程,称为贝尔曼方程。


这个方程是有用,因为它可以转化为一个迭代过程来找到最优值函数。
但,为什么价值函数有用吗?
因为你可以推断出一个最优政策的最优核反应能量函数。
如何?
最优政策是在每一个状态年代代理选择行动一个最大化核反应能量函数。
所以,你可以从最优政策最优q-functions跳,反之亦然。
有几个RL专注于找到最优的核反应能量函数的算法。这些被称为q学习方法。
的动物学的强化学习算法
有很多不同的RL算法。一些试图直接找到最优政策,其他核反应能量函数,和其他人都在同一时间。
的动物学的RL算法多样,让人有点惶恐。
没有放之四海而皆准的当谈到RL算法。你需要尝试一些每次你解决一个RL问题,看看有什么适合你的情况。
当你沿着这门课你会实现这些算法的几个和看透什么在每个情况下效果最好。
3所示。如何生成训练数据?
强化学习代理数据非常饥渴。


解决RL问题需要大量的数据。
克服这个障碍是通过使用的一种方法模拟环境。编写模拟环境的发动机比解决RL问题通常需要更多的工作。同时,改变不同引擎的实现可以渲染算法之间的比较没有意义。
这就是为什么男人在OpenAI发布了健身房工具包早在2016年。OpenAIs的健身房提供了一个标准化的API的集合环境对于不同的问题,包括
- 经典的雅达利游戏,
- 机械手臂
- 或在月球上着陆(好吧,一个简化的一个)
也有专有的环境,喜欢MuJoCo(最近买的DeepMind)。MuJoCo是一个环境,你可以在3 d解决连续控制的任务,就像学走路。
OpenAI健身房还定义了一个标准的API来构建环境,允许第三方(比如你)创建和提供你的环境。
如果你感兴趣的是自动驾驶汽车,那么你应该看看卡拉,最流行的开放城市驾驶模拟器。
4所示。Python样板代码
你可能会想:
我们覆盖到目前为止很有趣,但这一切在Python中我怎么写呢?
我完全同意你的观点
让我们看看这一切看起来像在Python中。
你找到一些不清楚在这段代码中吗?
第23行呢?这是什么ε?
不要恐慌。我之前没有提到这个但是我不会离开你,没有一个解释。
ε是一个关键参数,以确保我们的代理探索环境,得出明确的结论之前应该采取什么是最好的行动在每个国家。
它是0和1之间的值,它代表了概率代理选择一个随机的行动,而不是什么她认为是最好的。
探索新的战略之间的权衡与坚持已知的被称为exploration-exploitation问题。这是一个关键因素在RL问题和RL问题有别于监督机器学习的东西。
技术上来说,我们希望代理找到全局最优,而不是一个地方。
是一种很好的做法开始你训练一个较大的值(例如50%),每集后逐渐减少。这样代理了很多一开始,和更少的是她完善的策略。
5。回顾✨
的关键外卖这一部分是1:
- 每个RL问题都有一个代理(或代理),环境、行动、状态和奖励。
- 代理顺序需要行动与目标的总回报最大化。她需要找到最优政策。
- 价值函数是有用,因为他们给了我们另一种路径找到最优政策。
- 在实践中,你需要尝试不同的RL算法对于你的问题,看看效果最好。
- RL代理需要大量的训练数据来学习。OpenAI健身是一个很好的工具重用和创建您的环境。
- 勘探与开发是必要的,当训练RL代理,以确保代理不陷入局部最优。
6。家庭作业
一门课程没有一点家庭作业不会的课程。
我想让你选择你感兴趣的一个真实问题,可以使用强化学习模型和解决。
选择一个你关心的问题。这些是你想要的花你宝贵的时间。
定义什么是代理(s),行动,和奖励。
随时给我发电子邮件plabartabajo@gmail.com你的问题,我将给你反馈。
7所示。接下来是什么?
在第2部分我们第一次解决强化学习使用q学习的问题。
看到你在那里!











