实践强化学习课程:第3部分

欢迎来到我的强化学习课程❤️
这是我亲身的第3部分的强化学习课程,将你从零到英雄♂️。
我们仍在旅程的开始,解决相对容易的问题。
在第2部分我们实现了离散q学习培训的代理Taxi-v3环境。
今天,我们要进一步解决MountainCarenvironment using SARSA algorithm.
让我们帮助这个可怜的车赢得对抗重力!
这节课的所有代码这Github回购。Git克隆它跟随今天的问题。


第3部分
内容
- 山车的问题
- 环境、行为、状态的回报
- 随机代理基线
- 撒尔沙代理
- 停下来,呼吸⏸
- 回顾✨
- 家庭作业
- 接下来是什么?❤️
1。山车的问题
该谅解备忘录n锡箔汽车存在的问题是一个重力的环境(一个惊喜),目标是帮助一个可怜的车赢得对抗它。
汽车需要逃离硅谷卡住了。汽车的发动机没有强大到足以在单通道爬上山,所以让它的唯一方法是开车来回,建立足够的动力。
让我们看看在行动:
你刚刚看到对应的视频SarsaAgent今天我们将建立。
很有趣,不是吗?
你可能想知道。这看起来很酷,但你为什么选择这个问题呢?
为什么这个问题?
哲学这门课程是逐步增加了复杂性。循序渐进的。
今天的环境代表一个小但相关增加的复杂性相比Taxi-v3从第2部分环境。
但是,到底是什么困难吗?
我们看到在第2部分强化学习的困难问题的大小直接相关
- 操作空间:多少从每一步行动代理可以选择吗?
- 状态空间:有多少种不同的环境中配置代理能找到自己吗?
为小环境与数量有限的(小)的行为和状态,我们有强有力的保证像q学习算法将工作做好。这些被称为表格或离散环境。
Q-functions本质上是矩阵与尽可能多的行和列的操作。在这些小世界,我们的代理可以很容易地探索国家和建立有效的政策。状态空间和(尤其是)行动空间变得更大,RL问题变得更加难以解决。
今天的环境不表格。然而,我们将使用一个离散化“诡计”转变成一个表格,然后解决它。
我们先熟悉环境!
2。环境、行为、状态的回报
让我们加载环境:


和情节一帧:



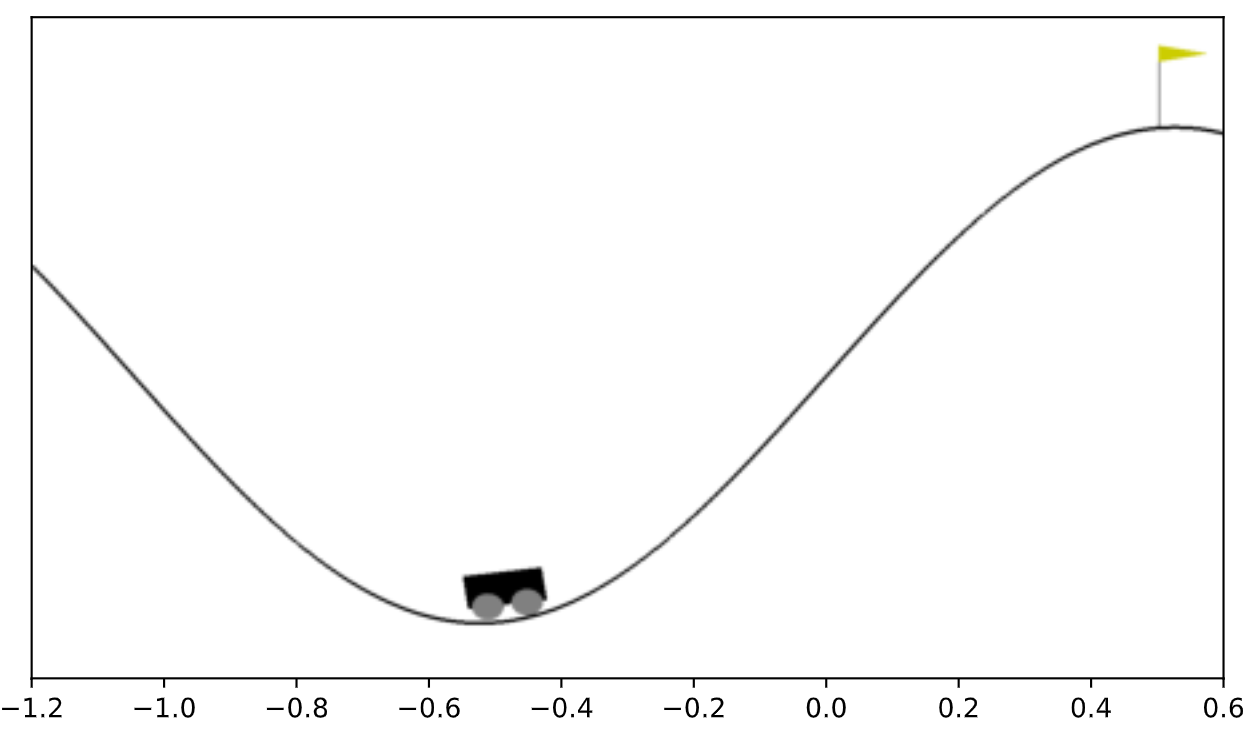
两个数确定状态汽车:
- 它的位置,范围从-1.2来0.6
- 它的速度,范围从-0.07来0.07。


国家是由2个连续的数字。这是一个显著的区别的Taxi-v3环境第2部分。稍后我们将看到如何处理这个问题。
是什么行动吗?
有三个可能的行动:
0加速到左边1什么都不做2加速向右


和奖励吗?
- 1是授予的奖励如果车的位置小于0.5。
- 事件结束后汽车的地位高于0.5,或已经达到最大数量的步骤:
n_steps > = env._max_episode_steps
一个默认的负奖励鼓励汽车尽快逃离硅谷。
总的来说,我建议你检查开放的人工智能健身环境的实现直接在Github了解州,行动,和奖励。
代码是有据可查的,可以帮助你快速了解一切你需要开始工作RL代理。MountainCar的实现是在这里为例。
好。我们熟悉环境。
让我们构建一个基线代理这个问题!
3所示。随机代理基线
笔记本/ 01 _random_agent_baseline.ipynb
强化学习问题可以很容易变得复杂起来。结构良好的代码是你最好的盟友控制的复杂性。
今天我们要来提升我们的Python的技能和使用BaseAgent类所有的代理。从这个BaseAgent类,我们将推出RandomAgent和SarsaAgent类。


BaseAgent是一个抽象类我们定义的src / base_agent.py
它有4种方法。
两个方法都是抽象的,这意味着我们被迫当我们中实现它们RandomAgent和SarsaAgent从BaseAgent:
get_action(自我状态)→返回执行的行动,根据状态。update_parameters(自我状态、行动、奖励,next_state)→调整剂使用经验参数。这里我们将实现撒尔沙公式。
其他两个方法让我们保存/加载训练代理/从磁盘。
save_to_disk(自我,路径)load_from_disk (cls路径)
当我们开始实现更复杂的模型和训练时间的增加,这将会是一个好主意来拯救检查点在训练。
这里是我们的完整代码BaseAgent类:


从这个BaseAgent类,我们可以定义RandomAgent如下:


我们评估这个RandomAgent在n_episodes = 100看看它票价:




和我们的成功率RandomAgent是…


0%…
我们可以看到多远代理在每一集里都会有下面的柱状图:



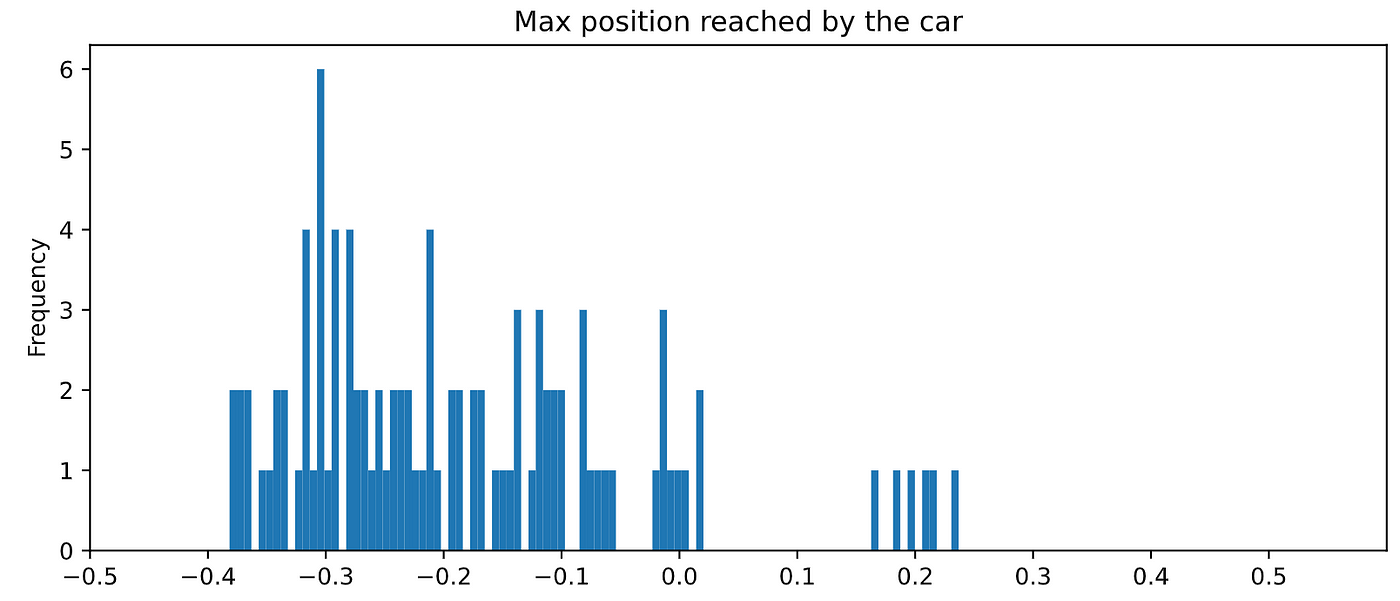
在这些One hundred.我们的运行RandomAgent没有穿过0.5马克。没有一个时间。
在本地机器上运行这段代码时你会得到不同的结果,但完成事件的比例高于0.5将是非常远离任何情况下的100%。
你可以看我们的痛苦RandomAgent在行动中使用好show_video函数src / viz.py


一个随机代理解决这个环境是不够的。
让我们尝试一些更聪明…
4所示。撒尔沙代理
撒尔沙(由酒店和Niranjan)是一种通过学习算法训练强化学习代理最优核反应能量函数。
它出版于1994年,后两年q学习的(由克里斯·步进和彼得·达扬)。
撒尔沙代表年代泰特一个引发反应Reward年代泰特一个引发反应。
撒尔沙和q学习利用贝尔曼方程迭代找到更好的近似最优核反应能量函数Q * (,)

但他们略有不同。
如果你还记得第2部分,更新公式q学习的

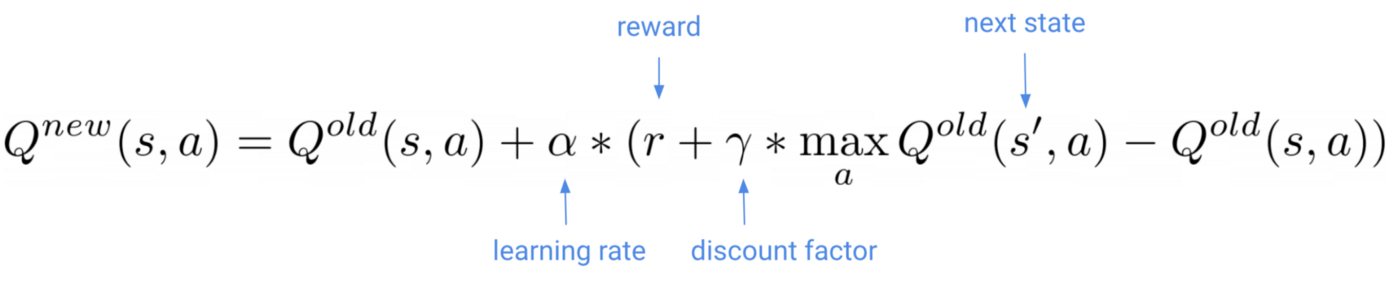
这个公式是计算一个新的估计的核反应能量接近

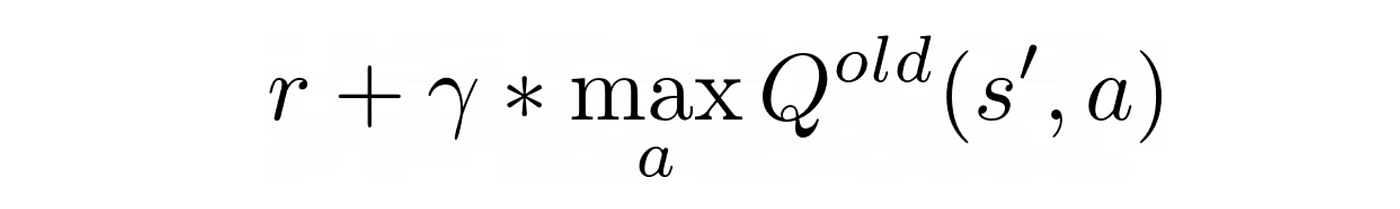
这个量是一个目标我们要改正我们的老估计。这是一个估计最优的核反应能量我们应该瞄准,当我们培训代理和核反应能量变化矩阵更新。
强化学习问题经常看起来像监督毫升问题,但是移动目标
撒尔沙也有类似的更新公式,但有不同的目标

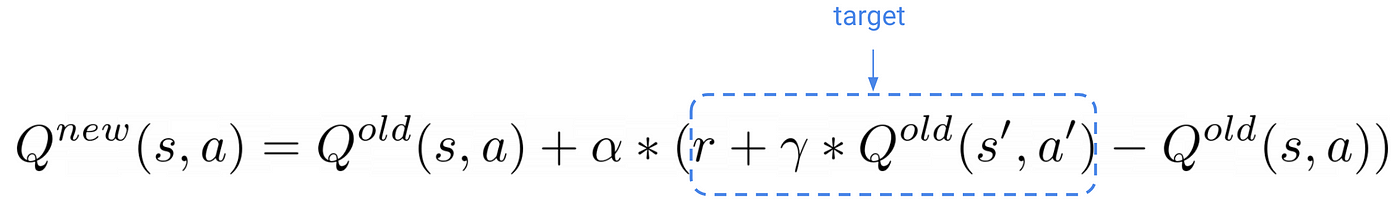
撒尔沙的目标
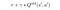
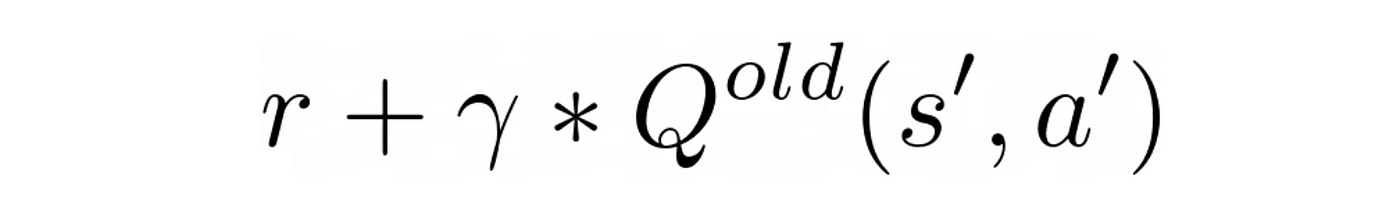
也取决于行动一个“代理将在未来的状态年代”。这是最后的一个在非典一个“年代的名字。
如果你探索足够的状态空间和更新你的q-matrices撒尔沙你会得到一个最优的政策。太棒了!
你可能会想…
q学习和撒尔沙看起来几乎相同的给我。的区别是什么?
有一个关键的区别:
- 撒尔沙的更新取决于接下来的行动一个”,因此对当前政策。当你训练和核反应能量(和相关政策)得到更新新政策可能会产生不同的下一个动作一个“同样的状态年代。你不能用过去的经验(s, r, s ', ')来提高你的估计。相反,你使用每个体验一次更新q值,然后扔掉。正因为如此,撒尔沙被称为一个在政策方法。
- 在q学习,更新公式并不取决于接下来的行动一个”,但只有在(s, r, s”)。您可以重用过去的经验(s, r, s '),收集到一个旧版本的政策,改善当前政策的q值。q学习是一个off-policy方法。
Off-policy方法需要较少的经验学习比在政策方法,因为你可以重用多次过去的经验来改善你的估计。他们更样品有效。
然而,off-policy方法问题收敛于最优核反应能量函数Q *(,)状态时,操作空间成长。他们可能会非常棘手不稳定。
我们会遇到这些权衡以后的课,当我们进入深RL领土。
回到我们的问题…
在MountainCar环境,国家不是离散,但一双连续值(位置s1、速度s2)。
连续本质上意味着无限可能的值在这种情况下。如果有无限的可能的状态,是不可能拜访他们所有人保证撒尔沙会收敛。
为了解决这个问题我们可以使用技巧。
让我们使离散状态向量为有限的一组值。从本质上讲,我们并没有改变环境,但是国家的代表代理使用选择自己的行动。
我们的SarsaAgent可获得国家(s1, s2)从连续到离散,通过舍入位置(-1.2…0.6)到最近的0.1马克,速度[-0.07,0.07]到最近的0.01马克。
这个函数就是这么做的,连续转化为离散状态:

一旦代理使用一个离散状态,我们可以使用从上面撒尔沙更新公式,我们继续我们将接近最优迭代核反应能量。
这是整个实现的SarsaAgent


Note that the q-value function is a matrix with 3 dimensions: 2 for the state (position, velocity) and 1 for the action.
让我们选择合理hyper-parameters和培训SarsaAgent为n_episodes = 10000




让我们的阴谋奖励和max_positions(蓝线)50-episode移动平均线(橙色线)

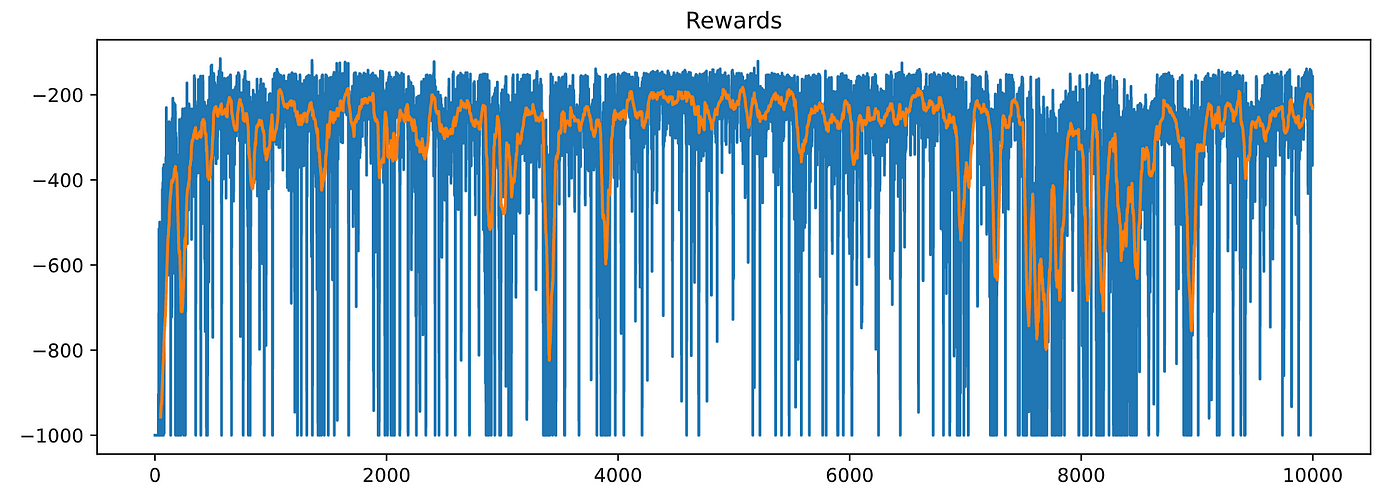


超级!它看起来像我们的SarsaAgent是学习。
在这里你可以看到在行动:
如果你观察max_position上面图,你会发现汽车偶尔不能爬山。
多久会这样?让我们评估代理1000年随机集:


和计算的成功率:


95.2%很好。不过,并非完美。把一根针,我们将在晚些时候回来。
注意:当您运行此代码在你结束你会得到不同的结果,但我打赌你不会得到100%的性能。
伟大的工作!我们实现了一个SarsaAgent学习
这是一个很好的时刻采取暂停…
5。停下来,呼吸⏸
笔记本/ 03 _momentum_agent_baseline.ipynb
如果我告诉你什么MountainCar环境有一个更简单的解决方案…
工作100%的时间吗?
最好的策略很简单。
遵循动量:
- 加速,当车向右移动
速度> 0 - 加速离开,当汽车向左移动
速度< = 0
视觉这一政策是这样的:


这是你如何写这篇文章MomentumAgent在Python中:


你可以仔细检查它完成每一个插曲。100%的成功率。




如果你把训练SarsaAgent的政策,另一方面,你会看到这样的:


有50%的重叠的完美MomentumAgent政策


这意味着我们的SarsaAgent是正确的只有50%的时间。
这是有趣的…
为什么SarsaAgent错了所以经常但仍达到良好的性能吗?
这是因为MountainCar仍然是一个小环境,所以采取错误的决定50%的时间不是那么重要。对于较大的问题,经常犯错并不足以构建智能代理。
你会买一辆无人驾驶汽车,95%的时间是正确的?
另外,你还记得离散化方法我们使用应用撒尔沙?这是一个技巧,帮助我们很多,还引入了一个错误/倾向我们的解决方案。
我们为什么不增加分辨率离散化的状态和速度,更好的解决方案吗?
这样做的问题是指数增长的状态数,也称为诅咒的维度。当你增加每个状态的解析组件,州的总数就会成倍增长。撒尔沙代理的状态增长过快收敛于最优政策在合理的时间内。
好的,但是还有其他RL算法可以完全解决这个问题吗?
是的,有。我们将介绍他们在即将到来的讲座。一般来说,没有放之四海而皆准的RL算法时,所以你需要尝试一些你的问题,看看效果最好。
在MountainCar环境,完美的政策看起来那么简单直接,我们可以尝试学习它,而不需要计算复杂的核反应能量矩阵。一个政策优化可能最有效方法。
但是今天我们不会这样做。如果你想解决这个环境完全使用RL,跟随。
享受你的成果。


6。回顾✨
哇!我们今天走了很多东西。
这些是5外卖:
- 撒尔沙是一个政策算法可以在表格环境中使用。
- 小型连续环境可视为表格,利用离散化的状态,然后用表格解决撒尔沙或表格q学习的。
- 更大的环境不能离散和解决由于维度的诅咒。
- 对于更复杂的环境
MountainCar我们需要更先进的RL的解决方案。 - 有时RL并不是最好的解决方案。记住当你试图解决你所关心的问题。不嫁给你的工具(在这种情况下RL),而不是专注于找到一个好的解决方案。不要错过的森林树木。
7所示。家庭作业
这就是我想要你做的事:
- Git克隆回购到您的本地机器上。
- 设置这节课的环境
02 _mountain_car - 开放
02 _mountain_car /笔记本电脑/ 04 _homework.ipynb并尝试完成2挑战。
在第一个挑战,我要求你调整撒尔沙hyper-parametersα(学习速率)和γ(折现系数)来加快培训。你可以得到灵感第2部分。
在第二个挑战,试图增加的分辨率离散化和学习表格撒尔沙的核反应能量函数。正如我们今天所做的。
让我知道如果你建立一个代理,性能达到99%。
8。接下来是什么?❤️
下节课,我们要进入一个领域,强化学习和监督机器学习相交。
它是很酷的,我保证。
在那之前,
享受多一天在这个叫做地球的星球
爱❤️
和不断学习
如果你喜欢,请与朋友和同事分享。
你可以找到我plabartabajo@gmail.com。我想连接。
再见!