与核心Pyspark的整齐时间序列聚集
用核心PySpark移动窗口聚合策略,用Plotly实现可视化

有一个吨时间序列度量,其中许多度量具有相同的预处理步骤和/或用例。为了限制冗余,我将重点关注三个使用不同用例的标准:
- 基于滚动Z-Scores的离群点检测
- 滚动相关矩阵
- 具有指数移动平均线的趋势检测
第一节给出了滚动窗口和采样周期的定义。这些公式为如何开始创建这些移动窗口指标提供了有用的上下文。也可以直接跳到情节和代码;)
与所有的东西都有机智H数据,有多种方式烤你的数据.这里有点关于我的背景和编程风格:我来自使用大量SQL的工作环境,我的聚合策略反映了这一点。结果,我不使用Pyspark表达式或内置库,即如果我可以在没有它们的情况下完成任务。
本文中的代码在本地PySpark环境中进行了测试,并连接到S3数据源。在这里是一篇关于如何在Windows 10上设置这个测试环境的简短教程文章。
所有方程,情节和数字都是由我创造的。所有绘图代码都可以找到这里.我为我的所有情节绘制了。
移动窗口和抽样期
时间序列矩阵通常被限定在一个时间窗口内。可能有不同的粒度或采样周期,可以为度量计算,例如,10分钟、1小时、1天等。在本文的其余部分中,我将使用的描述指标的语法如公式(0)所示。


P:(1xm)矩阵
K:采样周期(10分钟、1小时等)
M:看背面窗口的大小
N:当前时间序列的整数索引
n:跨时间序列的整数索引
t:时间块内的整数索引
例如,如果采样周期(k)是10分钟:
t = 0时,n = 1,1 * K = 10分钟
t = 1, n = 2, 2 * K = 20分钟
t = 2, n = 3, 3 * K = 30分钟


块的时候,T.,表示1个大小为m的时间窗口,对每个时间窗口进行聚合后,时间索引N加1。度量被聚合T., 和N跟踪每个窗口的全局时间索引。
基于滚动Z-Scores的离群点检测
滚动z分数阈值可用于检测时间序列中的大跳跃或间隙。这方面有许多潜在的应用程序,例如,为大的异常值创建警报系统。
z分数,或标准分数,表示离均值标准差的个数。如果您是统计学新手,您可以阅读更多关于这个指标的信息这里.这个度量可以看作是移动平均线附近的一个置信区间。
简单移动平均和简单移动标准差将被用来创建z分数,分别如下式(1)和(2)所示。

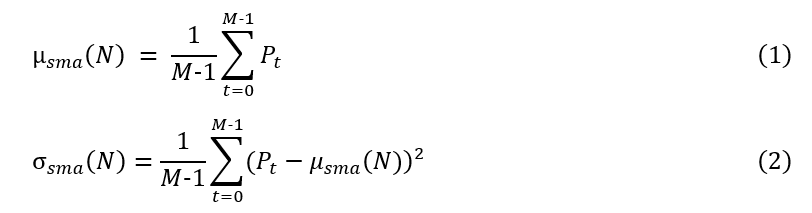
上面的公式示出了如何在滚动窗口T的时间步骤N,T,尺寸M-1时定义这两个度量。最后一次步骤m,从聚合时间窗口中释放出来,因为目标是将当前时间序列值与上一个窗口的平均值和标准偏差进行比较。如果包含静音时间步骤,则标准偏差可能会大大增加,并且在时间序列中,度量将无法检测到大的变化。
在我们执行这些滚动窗口的计算之后,可以计算Z-Score上限和下限,如公式(3)和(4)所示。

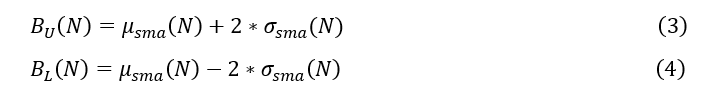
在这些方程中,z分数的上界和下界分别设为均值上下两个标准差。假设正态分布,经验规则指出,我们预计99.7%的数据具有谎言到标准偏差。
下图显示了ATVI每小时股票价格的10HR移动平均值的z分数上限和下限。


绿色阴影区域表示移动平均附近的置信区间,黄色线表示时间序列,绿色线是时间序列的移动平均。在某一点上,在置信区间外有一个急剧的下降,这表明有一个大的离群值。标准偏差,随后大大增加后倾斜。有一些时间序列跨越置信区间的点,变化不是很显著。对于这个特定的时间序列,可以使用更大的z分数阈值。
注意:数据集经过预处理,包括工作日上午9点到下午4点之间的每小时数据。出于绘图的目的,这些值是根据索引而不是时间绘制的。这消除了图中的一些不连续性。
PySpark代码:
首先,创建一个排名索引以执行自行连接,以便获得按时间订购的历史窗口,每个时间序列,即股票符号。然后,在视图(a)中的每个值的视图(b)中聚合移动平均和移动标准偏差。从这些度量标准,可以计算上限和下限Z分数阈值。
滚动相关矩阵
滚动相关矩阵可以帮助将相关的时间序列分组在一起,帮助发现明显的、不相关的时间序列,或检测相关模式的变化。我给您的挑战是,在不使用内置的PySpark函数的情况下创建它;)
标准化的协方差,或Pearson的相关系数,描述了两个变量之间的相关性。度规在-1和1之间,这是在时间序列对之间比较这个度规时非常有用的属性。我们可以通过滚动的时间窗口计算这种相关性。
滚动相关也可以用指数移动平均函数平滑。平滑滚动相关的另一个术语是“实现的相关”。

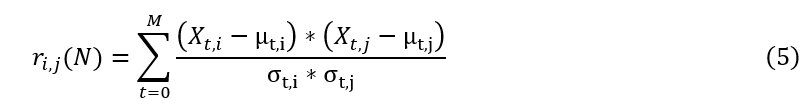
在那里,R.为我们时间序列数据集中第I列与第j列的相关关系,μ为简单移动平均,σ为简单移动标准差。
我将使用我信赖的股票数据集来绘制DoorDash每小时股价与其他股票(即ATVI、DIS、NVDA和WMT)之间的滚动相关性。


与其他时间序列相比,DASH和NVDA之间的相关性在较长的时间周期内似乎是一致的。同时持有这两种股票会增加投资组合的风险。
注:上图中缺失的数据点,发生在当前时间步n的任何一个时间序列的数据缺失时。例如DIS是2021年8月至2021年11月之间的数据缺失。但是,相关性窗口将跳过空值,并且在聚合中使用过去14个小时没有丢失的值。
PySpark代码:
第一步是计算数据透视表,按时间划分,按时间序列id、股票符号分组。这个数据透视表取时间序列的平均值,关闭但由于数据集是预处理的预处理,最小,最大,首先或最后一次将作为聚合。
对于每一对时间序列,在计算滚动相关性之前,将删除两个时间序列中具有空值的行
下一步是创建时间序列的不重复对或组合。带有空值的行将从每个组合中删除。最后,我们需要计算每一对时间序列之间的相关性。幸运的是,PySpark中有一个内置函数来计算两列之间的相关性。然后,滚动关联被左连接回pivot表。
具有指数移动平均线的趋势检测
差异的指数移动平均可以用来检测速度,或趋势,时间序列。该方法可以应用于二次检测,对不同的时间序列进行检测加速或者趋势的变化率。
指数移动平均线(EMA)可以被看作是一个过滤器,它对聚合窗口中最近的值具有更大的重要性。均线有两个主要参数,即α衰减率和窗口大小。时间窗口或更低的alpha越大,EMA的较慢移动。换句话说,移动平均将更多地滞后于实际时间序列。
本节中使用的趋势检测方法通常称为MACD..但是,我将用新的算法解释这种算法,在我的意见更容易理解,术语。
通常,alpha值等于2/(1+M),其中M是窗口大小。alpha的这个值对应于加权平均影响,或“质心”,对应于简单移动平均线(SMA)的回望窗口的中心。换句话说,对于高自相关信号(如股票价格),均线将落后于实际价格大约一半的回望窗口大小。请参阅罗伯特·诺的《预测笔记》为更多的细节。
据我所知,谷歌搜索,不可能在Pyspark中实现递归方法,例如在Pyspark中,而不使用用户定义的函数或UDF。幸运的是,有一个扩展的系列表示,可用于计算核心Pyspark中的EMAS。等式(6)显示了扩展符号中的指数移动平均公式(EMA)。


通过在快速移动(时间窗口)和慢速移动(时间窗口)EMA之间的差异之间的差异趋势可以估计。直观地,这可以被认为是坡度,或离散衍生物,在更近以前和以前的价格之间。这些EMA之间的差异可以称为速度的趋势。

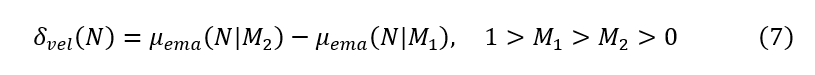
趋势正在发生变化的速率也可以用1)速度和2)的EMA速度(或信号)。


两者之间的区别信号和速度可以被认为是加速的趋势.速度和信号之间的收敛表示趋势方向的反转。分歧是越来越强烈的趋势。

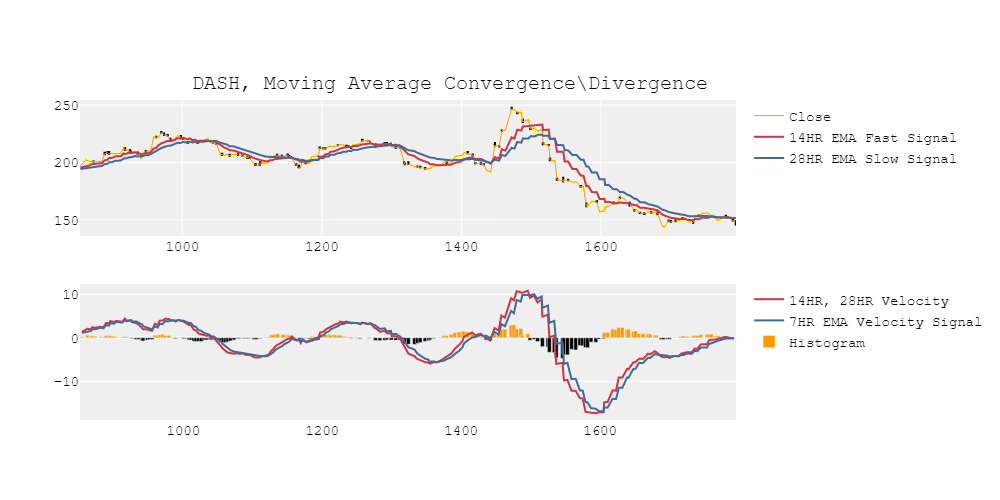
上面的图表显示了时间序列(黄色),缓慢的EMA(蓝色)和快速的EMA(红色)。底部的图表显示加速(直方图),趋势速度(红色),和信号(蓝色)。在短时间间隔的趋势中,情节显示了一些趋势。可信地,可能有一些安全阈值的加速这可以用来探测强劲的上升和下降。
注意:因为我选择K=3作为采样周期,所以这个图看起来有点不稳定。
PySpark代码:
A separate function was created to calculate an EMA for a particular window of size M. Within this function, a ranked index is created to perform a self-join, in order to get a historical window, ordered by time, for each partition, i.e., stock symbols. The difference between the historical window’s index and the current index is used to create the alpha weights for the expanded series representation of the EMA formula, shown in Equation 8. Finally, the EMA is aggregated across view (b) for each value in view (a).
我们可以使用EMA函数来计算快速移动的EMA,缓慢移动的EMA,快速和缓慢EMA之间的差值(速度),以及速度的EMA(信号)。
结论
简单地说,本文展示了如何在PySpark和SQL中聚合时间序列。我知道时间序列窗口和方程的正式定义使这篇文章更难阅读。不过,我喜欢做得彻底。)我也可能把这篇文章分成三篇。尽管如此,仍然希望PySpark和Plotly代码对一些新的数据科学家和工程师有用。
以下是一些你可以尝试的数据挑战:
- 在异常检测算法中,使用指数移动平均值而不是简单的移动平均值。
- 编写自己的相关函数,而不是使用内置的PySpark相关函数。探索实现类似的度量标准,例如:协整.
- 使用指数移动平均线创建平滑移动窗口相关矩阵。
- 表征跨M1、M2和M3多个参数的趋势检测方法的有效性。
这是所有的人。















