使用核心PySpark进行整齐的时间序列聚合
使用核心PySpark移动窗口聚合策略,使用Plotly可视化

有一个吨其中许多指标都具有相同的预处理步骤和用例。为了限制冗余,我将专注于三个具有不同用例的整洁指标:
- 滚动z -分数的离群值检测
- 滚动相关矩阵
- 指数移动平均趋势检测
在第一节中,给出了滚动窗口和采样周期的定义。这些公式为如何开始创建这些移动窗口指标提供了有用的上下文。请随意跳过情节和代码:)
就像所有的事情一样h数据,有不止一种方法烘焙数据.下面简要介绍一下我的背景和编程风格:我来自一个使用大量SQL的工作环境,我的聚合策略反映了这一点。因此,我没有使用PySpark表达式或内置库,也就是说,如果我可以在没有它们的情况下完成任务。
本文中的代码在本地PySpark环境中进行了测试,并连接到S3数据源。在这里是一篇关于如何在Windows 10上设置此测试环境的简短教程文章。
所有的方程式、图表都是我创造的。所有的绘图代码都可以找到在这里.我所有的情节都使用Plotly。
移动窗口和采样周期
时间序列指标通常受某个时间窗口的限制。度量可以有不同的粒度或采样周期,例如,10分钟、1小时、1天等。我将在本文剩余部分中使用的描述度量的语法如式(0)所示。


P:(1xM)矩阵
K:采样周期(10min, 1h等)
男:回望窗的大小
N:当前整数跨时间序列索引
N:整型时间序列索引
T:时间块内的整数索引
例如,采样周期K为10分钟:
t=0, n= 1,1 *K=10min
t=1, n= 2,2 *K=20min
t=2, n= 3,3 *K=30min


时间块,t,表示一个大小为m的时间窗口。对每个时间窗口进行聚合后,时间索引N加1。这些指标被聚合在一起t,N跟踪每个窗口的全局时间索引。
滚动z -分数的离群值检测
滚动z-score阈值可用于检测时间序列中的大跳跃或间隙。这有许多潜在的应用程序,例如,为较大的异常值创建警报系统。
z分数,或标准分数,表示与平均值的标准差数。如果您不熟悉统计学,可以阅读更多关于此指标的信息在这里.这个指标可以作为移动平均线周围的置信区间。
需要简单移动平均和简单移动标准差来创建z得分,分别如下面式(1)和式(2)所示。

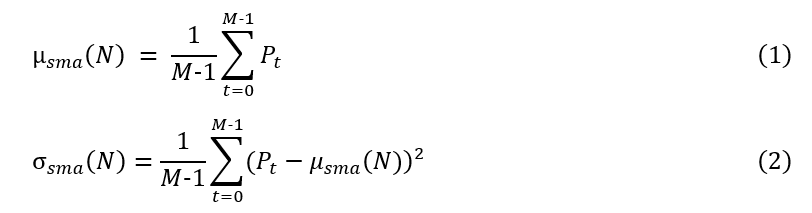
上面的公式显示了这两个指标是如何在时间步长N,滚动窗口t上定义的,大小为M-1。最后一个时间步骤M被排除在聚合时间窗口之外,因为目标是将当前时间序列值与前一个窗口的平均值和标准差进行比较。如果包含当前时间步长,则标准偏差可能会大大增加,并且度量将无法检测时间序列中的大变化。
我们进行这些滚动窗口计算后,可以计算出z分数的上界和下界,分别如式(3)和(4)所示。

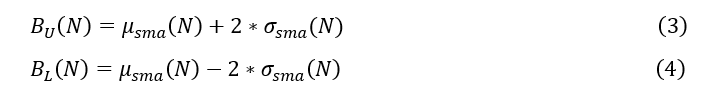
在这些方程中,z分数的上限和下限分别设置为高于平均值和低于平均值的两个标准差。假设是正态分布,经验法则我们期望99.7%的数据都在标准差范围内。
下图显示了ATVI每小时股价10小时移动平均值的z分数上限和下限。


绿色阴影区域表示移动平均线周围的置信区间,黄色线表示时间序列,绿色线是时间序列的移动平均线。在某一点上,在置信区间之外有一个急剧的下降,这表明有一个很大的异常值。标准差,随后大幅增加后,下降,大约N=130。在某些点上,时间序列跨越了置信区间,而在这些点上变化不是很显著。对于这个特定的时间序列,可以使用更大的z分数阈值。
注意:数据集经过预处理,包括工作日上午9点至下午4点之间的小时数据。为了绘制图形,这些值是根据索引而不是时间绘制的。这消除了情节中的一些不连续性。
PySpark代码:
首先,创建一个排序索引来执行自连接,以便为每个时间序列(即股票代码)获得一个按时间排序的历史窗口。然后,对视图(a)中的每个值在视图(b)中聚合移动平均值和移动标准差。根据这些指标,可以计算z得分阈值的上限和下限。
滚动相关矩阵
滚动相关矩阵有助于将相关时间序列分组在一起,帮助发现不同的、不相关的时间序列,或检测相关模式的变化。我对你的挑战是创建这个不使用内置的PySpark函数;)
归一化协方差,或者皮尔逊相关系数,描述了两个变量之间的相关性。度量的范围在-1和1之间,这是在时间序列对之间比较该度量时非常有用的属性。我们可以在滚动的时间窗口内计算这种相关性。
滚动相关性也可以用指数移动平均函数平滑。平滑滚动相关的另一个术语是“已实现相关”。

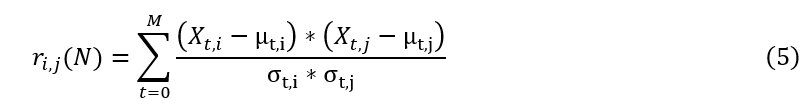
在那里,r是我们时间序列数据集中第I列和第j列之间的相关性,μ是简单移动平均,σ是简单移动标准差。
我将使用我的可信股票数据集绘制DoorDash每小时股价与其他股票(即ATVI、DIS、NVDA和WMT)相关的滚动相关性。


与其他时间序列相比,DASH和NVDA之间的相关性在更长时间内似乎是一致的。拥有这两种股票可以提高投资组合的风险状况。
注:上图中缺失的数据点发生在任何一个时间序列缺少当前时间步长n的数据时。例如,DIS在2021年8月至2021年11月之间缺少数据。但是,相关窗口将跳过空值,并在聚合中使用没有丢失值的最近14小时。
PySpark代码:
第一步是计算数据透视表,按时间划分,按时间序列id、股票代码分组。这个数据透视表取时间序列的平均值,关闭,但由于数据集是按小时预处理的,因此最小值、最大值、第一个或最后一个值也可以作为聚合。
对于每对时间序列,在计算滚动相关性之前,在任何时间序列中具有空值的行都将被删除
下一步是创建时间序列的非重复对或组合。从每个组合中删除具有空值的行。最后,我们需要计算每对时间序列之间的相关性。幸运的是,PySpark中有一个内置函数来计算两个列之间的相关性。然后将滚动相关性左连接回数据透视表。
指数移动平均趋势检测
差指数移动平均可以用来检测速度,即时间序列的趋势。这种方法可以应用于第二次,对不同的时间序列,以检测加速度,或趋势的变化率。
一个指数移动平均线,EMA,可以被认为是一个过滤器,把更重要的最近的值在聚集窗口。EMA有两个主要参数,即α衰减率和窗口大小。时间窗口越大或alpha越低,均线移动就越慢。换句话说,移动平均线将落后于实际时间序列更多。
本节使用的趋势检测方法通常称为趋势检测方法MACD.但是,我将用新的,在我看来更容易理解的术语来解释这个算法。
通常,alpha通常被选择为2/(1+M),其中M是窗口大小。alpha的这个值对应于平均加权影响,或“质心”对应于简单移动平均(SMA)回望窗口的中心。换句话说,对于高度自相关的信号(如股票价格),均线将落后于实际价格大约一半的回溯窗口大小。请参阅罗伯特·诺的预测笔记欲知详情。
据我所知,谷歌搜索,不可能在PySpark中实现递归方法,如EMAs,而不使用用户定义的函数或UDF。幸运的是,在核心PySpark中有一个扩展的级数表示可以用来计算ema。式(6)为展开符号下的指数移动平均公式(EMA)。


通过取快速移动(较短时间窗口)和缓慢移动(较长时间窗口)的EMA之间的差值,可以得到趋势可以估计。直观地说,这可以被认为是最近价格和以前价格之间的斜率或离散导数。这些ema之间的区别可以称为速度趋势。

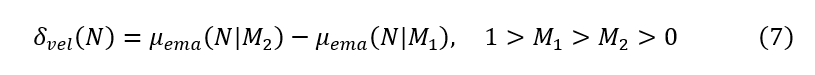
趋势变化的速率也可以用1)速度而且2)的EMA速度(或信号)。


两者之间的区别信号和速度可以认为是加速度趋势的变化.速度和信号之间的收敛表示趋势方向的逆转。这种分歧代表了一种越来越强的趋势。

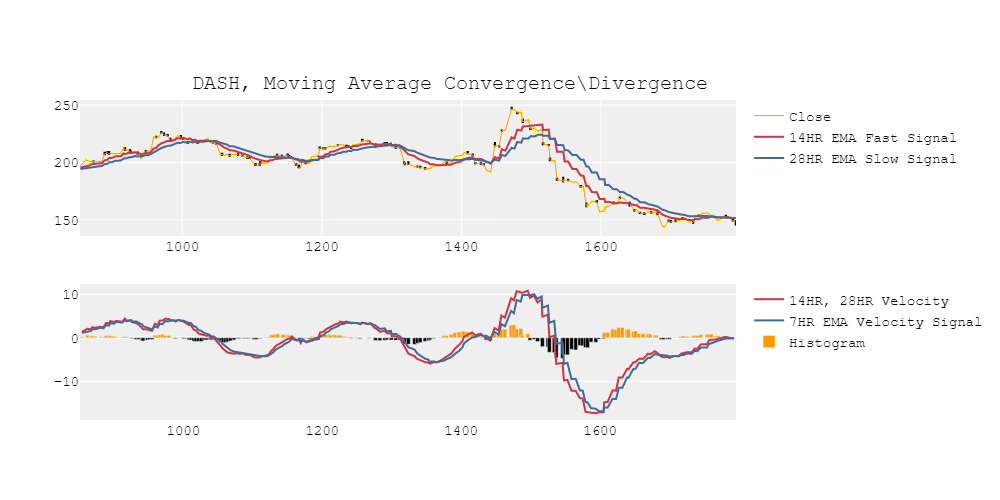
上图显示了时间序列(黄色)、慢EMA(蓝色)和快EMA(红色)。下面的图显示了加速度(直方图),趋势速度(红色)和信号(蓝色)。该图在短时间间隔内显示了一些趋势的一致性。当然,可能会有一些安全阈值加速度它可以用来检测强劲的上升和下降。
注意:由于我选择K=3作为采样周期,所以图看起来有点起伏不定。
PySpark代码:
创建了一个单独的函数来计算大小为m的特定窗口的EMA。在这个函数中,创建了一个排序索引来执行自连接,以便为每个分区(即股票代码)获得一个按时间排序的历史窗口。历史窗口指数和当前指数之间的差异被用于为EMA公式的扩展级数表示创建alpha权重,如公式8所示。最后,EMA为视图(a)中的每个值跨视图(b)聚合。
我们可以用EMA函数来计算快动EMA、慢动EMA、快、慢动EMA之差(速度)、速度EMA(信号)。
结论
简而言之,本文展示了如何在PySpark和SQL中聚合时间序列。我知道时间序列窗口和方程的正式定义使这篇文章更难阅读。然而,我喜欢彻底:)我可能也可以把这篇文章分为三篇。尽管如此,PySpark和Plotly代码仍然有希望对一些新的数据科学家和工程师有用。
以下是一些你可以尝试的数据挑战:
- 在离群值检测算法中,使用指数移动平均代替简单的移动平均。
- 编写自己的相关函数,而不是使用内置的PySpark相关函数。探索实现类似的指标,例如,协整.
- 使用指数移动平均创建一个平滑的移动窗口相关矩阵。
- 描述跨M1、M2和M3的多个参数的趋势检测方法的有效性。
这就是所有的朋友们。