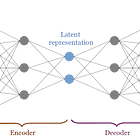
对深关系学习
机器学习的关系是什么?
一个深入学习基础表示特征向量

从人工智能毫升
本能地所有智慧生命形式模型他们的周边环境来积极浏览他们的行为。在人工智能(AI)的研究中,我们试图理解这个有趣的生活能力和自动化系统机器学习(毫升)的核心。
- 一般来说,推导数学模型复杂系统的核心任何科学学科。研究人员一直试图想出方程管理他们感兴趣的系统的行为,从物理学和生物学到经济学。
机器学习然后实例化科学的方法寻找一个数学的假设(模型)最适合观测数据。然而,由于计算机的发展,它允许进一步自动化这个过程分为搜索大型预制假设空间很大数据驱动的时尚。这是特别有用的建模的复杂系统的结构基本假设空间太过复杂,甚至是未知的,但大量的数据是可用的。
- 公平地说,类似的方法称为“模式识别”也一直是传统的一部分控制理论参数的微分方程,描述潜在的动态系统,估计从投入产出数据的测量,通常也复杂,系统范围。准确的模型,最优控制动作可以派生引导系统进化的目标措施,大部分的精神现在所谓的人工智能(更少的数学和更多的炒作)。
特征向量的起源
而数学建模的方法问题各种复杂系统演化的主要独立,方面,仍然几乎普遍的一个方面数据表示。事实上,虽然假设和模型的数学形式,传统上差别巨大的解析表达式和微分方程用于控制理论,一直到现在使用决策树和神经网络在ML,输入输出观测历来有限的形式数值向量。
这只看起来自然。由于计算机的出现,我们已经变得非常习惯于把任何感兴趣的属性变成一个数字,从物理测量,如力或电压,到颜色,情绪,或番茄酱在芥末的偏好。
给定一个数字的输入(X)和输出(Y)可以测量的变量在感兴趣的一个系统,从发电厂到一个人,每一个这样的测量然后减少到一个特定的向量的数字,通常被称为特征向量。
但是还有另外一个理由为什么特征向量非常有吸引力。处理每个数据样本(测量)作为一个独立的点在一个n维空间允许直接采用的标准机械线性代数,久经考验的数百年之前从其他领域工程。

由于这种表示样本独立假定为完全相同(先验知识)。从一些关节Pxy分布,机器学习的研究也可以直接建立在已知的概率统计结果浓度范围(例如,霍夫丁)提出的标准毫升理论“可能大约正确”(PAC)学习。因此,许多经典的机器学习,至少在研究,属于多变量统计。
作为因此,任何经典毫升方法目前预计输入数据的形式表,每一列对应一个功能X或目标变量Y,每一行对应一个例子测量。然后最通用的任务是估计的联合概率分布Pxy观测数据生成,或者更常见的在监督ML,估计条件Py | x。这些再一次任务,通常在统计学习很长一段时间了。
需要关系表示
我们现在有用于预处理数据到这样一个表(或张量)的数字,预期的输入格式几乎任何毫升库,它甚至可能很难想象,这不是无所不包的数据表示。然而,环顾四周,看看实际的真实的数据。这不是存储在数字矢量/张量,但在互联网页面的相互联系的结构,社交网络,知识图表,生物、化学、工程数据库等。这些都是天生的关系天生的数据存储在他们的结构形式的图形、超图,和关系数据库。

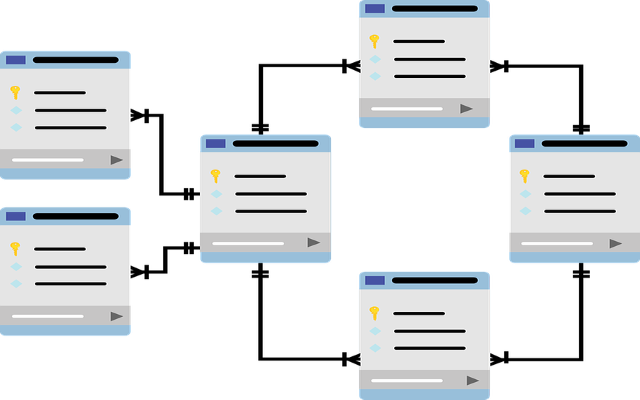
但是,等等,我们不能将这些结构转变成特征向量,和一切都恢复正常了吗?
人们确实原因上述(方便),直到最近,这是迄今为止的主要办法毫升与这些数据结构,通常被称为propositionalization。例如,一个可以计算各种统计数据结构,如计算节点,边缘,或从图子图(并利用各种内核方法操作对这些)。
从实用的角度来看,并没有什么错制作从关系结构特性,但它是很好的意识到有一个共同的潜在认知偏见这种方法:
“如果你有一把锤子,看什么都像是钉子。”
年代啊,我们可以跳过这个阶段的特征向量从关系数据结构吗?如果你现在思考“深度学习救援”,重要的是要意识到这一点,直到最近,所有经典的深度学习方法也仅限于表示形式的固定大小的数值向量(或张量)。深度学习背后的理念是“仅仅”跳过人工建设“低级”的“高级”表示向量(输入)表示向量,但你仍然需要后者开始!
从理论的角度来看,有一个深刻的问题将关系数据转换为矢量表示,由于没有映射关系结构不限任何方式没有固定大小表示(多余的)损失的信息在这个预处理(propositionalization)的步骤。
此外,即使我们限制固定大小的结构,设计一个合适的形式表示一个数字矢量或张量仍是困难重重。比如,即使只是图形数据,这是一种特殊形式的关系数据。如果有一个明确的方式映射图的标准学习形式(固定大小)数值向量(或张量),将平凡地解决图同构问题。
- 自测试如果两个图是否同构,它将足以把它们变成这样的向量和比较这些平等代替。当然,我们进一步假设创建这样的向量将是有效的(即不是np完备性)。
因此,有一个内在的需要一个从根本上不同的学习表现形式主义等数据与不规则的拓扑结构,外固定大小的经典空间数值向量(或张量)。
所以,我们可以学习与关系数据表示,各种形式的网络,(知识)图,和关系数据库?
在卫星系统。进行插曲当然,现在你可能已经听说过神经网络图(卫星系统)进行,最近提议解决图结构的数据,不要担心,我们将在后续文章中!现在,仅仅指出,卫星系统是一种特定的方式进行处理的一种形式的关系表示(图),根植于一个特定的(很好)启发式图同构问题(Weisfeiler-Lehman)。
现在让我们继续更广泛的视角。
机器学习的关系
最近大量的深度学习研究当时发现模型和在各种形式的学习表示捕获数据集和图形。然而,只有很少承认这些结构化的学习表现对长期以来研究(如一个特例)机器学习的关系。
一个关系您可能还记得,在一些定义的笛卡儿积集的一个子集的对象。每一个集因此简单的退化情况(一元)的关系。每一个图可以被视为一个实例化的二进制关系在同一组对象(节点)。表格数据,超过2列(对象),然后对应的关系更高的参数数量,也称为超图。添加多个这样的关系(表)的对象,和你有一个关系数据库。
许多现实世界的数据被存储在关系数据库中,你肯定遇到过。现在想象你的学习样本是不准备好作为一个表行,但分布在多个相互关联表的数据库,在不同样本包括不同的类型和数量的对象,每个对象被一组不同的属性特征。在实践中,这种情况实际上是远离罕见但你打算怎么这样适合你喜欢的支持向量机/ xGBoost NN模型?
虽然这些数据表示本质上不属于标准向量(张量)的形式,实际上有另一个表现形式,涵盖了所有这些格式非常自然。它是关系逻辑。
的确,关系逻辑¹是通用语言的结构化(关系)表示。在实践中,许多的标准格式(例如ERM & SQL)设计的结构化数据,从设置到数据库²,直接从关系逻辑(和遵循关系代数)。
虽然你可能已经熟悉关系逻辑/代数形式主义从CS 101,很可能你从来没有听说过它的上下文中机器学习。然而,除了一个伟大的数据操作和表现形式,直接关系逻辑也可以用来解决复杂关系机器学习的场景,就像上面的一个概述。
学习与逻辑
太多的灯光机器学习的主流,有一个社区归纳逻辑编程(独立),关心学习可说明的模型数据与复杂的关系结构。
独立了,利用关系逻辑形式的表现力来捕捉这些数据结构(包括关系数据库和更多)。然而,有趣的是,这里也用来表示关系逻辑模型本身。在独立,这些⁴采取逻辑的形式理论,即集使用的逻辑规则形成的逻辑关系。
此外,独立的基本概念背景知识可以,由于基于逻辑的表示,优雅的结合关系直接感应偏压模型。
F或几十年[3],而非传统的、关系毫升方法当时的总理学习与数据样本不屈服i.i.d.特征向量的标准形式。这使得独立探索一些非常处理结构化数据表示的一般学习问题,涉及各种对象参与关系,行为和事件,超出了标准统计毫升范围。
的例子。说明,让我们来看看最近探索图形结构学习问题可以处理这个关系逻辑。代表一个图表,我们简单地定义一个二进制的边缘的关系,与一组实例化边缘(x, y)对于所有相邻节点x, y图中。另外,我们也可以使用其他(一元)关系分配各种属性集的节点,如“红色(x)”等。

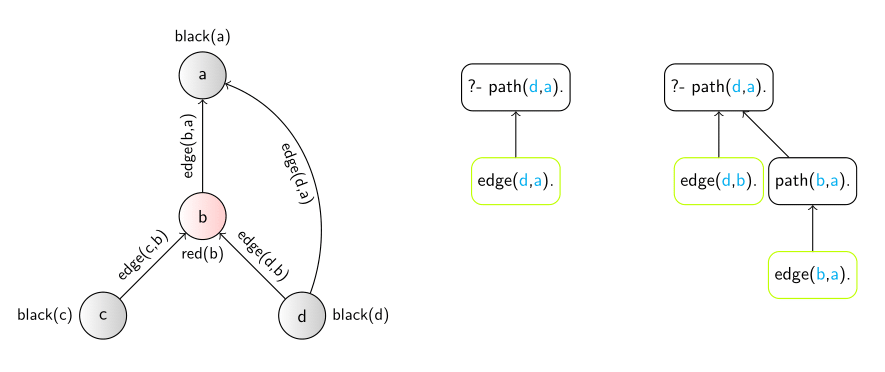
一般的模型,即逻辑规则,然后表达关系模式内搜索数据。这涵盖了各种各样的东西从寻找特征子结构在分子路径网络。由于高表达、陈述性自然,内在使用的递归关系的逻辑,然后学习模型常常简洁和优雅的。例如,(学)模型完全捕捉路径图,如从x到y地铁连接,将通常的样子
路径(X, Y) < =边缘(X, Y)。
路径(X, Y) < = (X, Z),路径(Z, Y)。
这可以很容易地学会了基本的独立系统,但几个例子。
我nterestingly,这是直接对比,例如,解决同样的问题可微的神经计算机最近Deepmind的亮点之一,需要大量的例子和额外的黑客(例如,修剪出无效的路径预测)解决任务的“不合适”的张量(命题)表示(模仿一个可微的内存)。
统计关系学习
尽管表示更多的表达,学习与逻辑本身并不适合处理噪音和不确定性。⁵应对这个问题,许多方法出现合并关系逻辑的表达,采用独立,和概率建模,采用从经典统计学习的概念统计关系学习(SRL)⁶涵盖学习的模型,从复杂的数据表现出不确定性和丰富的关系结构。特别是,SRL独立扩展了技术在non-logical学习世界的启发,比如基于方法和图形模型。
一般来说,有两个主要的流在SRL的方法——概率逻辑编程和解除建模,这将作为我们进一步探索的基础深关系学习概念。
把模型
相对于标准(又名“地面”)机器学习模型,把模型没有指定一个特定的计算结构,而是一个吗模板的标准模型正在展开的推理(评价)过程中,考虑到不同上下文的关系输入数据(也可能,背景知识)。
例如,(可以说)最受欢迎的模型——解除马尔可夫逻辑网络(MLN)[7]可能被视为经典的马尔可夫网络这样一个模板。对于预测和学习MLN结合一组特定的关系事实,描述输入数据(例如,数据库),并展开一个经典的马尔可夫网络。让我们仔细看看。
的例子。例如,这种MLN模板可能表达之前,“朋友”的吸烟者往往是吸烟者,吸烟可能导致癌症。学习数据可以描述一个人的社交网络与吸烟者贴上这样的一个子集。解除建模范式mln然后允许诱导吸烟概率的所有其他人们基于他们的社会关系,如常规的马尔可夫网络建模,但系统地概括了社交网络的不同结构和尺寸!
重要的是,这也使得模型捕获了固有的对称等学习问题⁸友谊关系的规律在所有网络,不同的人把它们的参数。
这个参数共享可以大大降低权重的数量是需要学习的,并允许解除模型表达的高度压缩表示问题,因为所有的常规关系模式(对称)是由单一共同参数化模板。这反过来允许更好的泛化。
- 此外,利用这种解除的对称建模方法还可以显著加快评价本身,这是通常被称为“解除推理生存研究实验室。
T这里一直在SRL社区提出许多有趣的概念,然而,增加表现力,他们经常也继承了独立的有问题的计算复杂性。也主要关注的概率(图形)模型,开发系统普遍缺乏效率、健壮性、学习能力和深度表示的神经网络我们变得如此习惯于享受。
因此,在实际的应用程序使用远非我们看到深度学习这些天。神经模型,另一方面,仍有极大地局限于固定大小的张量(命题)表示,正如本文中解释,不能正确地捕获的,动态的和不规则的结构化学习表示,关系的逻辑形式是自然的选择。
在下一篇文章中,我们将浏览到的历史”Neural-Symbolic集成“针对符号逻辑与神经网络相结合。这将进一步提供了一些背景我们朝着理想的现代结构深度学习的统一模型,如神经网络图,与关系逻辑放在一个表达”深关系学习”。
1。通常也称为谓词或一阶逻辑(此外还介绍了逻辑功能符号,将不需要)。
2。关系逻辑甚至不是局限于关系数据库,但进一步允许覆盖所有丰富的知识库和华丽的演绎本体。
[3]收割机,。、Dumančić年代。,埃文斯,r . et al。在30归纳逻辑编程。马赫(2021)学习。https://doi.org/10.1007/s10994 - 021 - 06089 - 1
4所示。这些的基础形式逻辑编程语言如Datalog和Prolog,这毫升方法是概念上接近项目领域的合成(由于高表达的学习模型)。
5。不确定性关系学习自然来自数据在很多层面上,从经典的不确定性对象的属性值类型(s)的不确定性,会员在一个关系,对象和关系的总体数量范围。
6。其他条款,本研究领域包括multi-relational学习/数据挖掘或概率逻辑的学习。结构预测模型也可以被视为SRL的实例。
[7]理查森,马修和佩德罗·多明戈。”马尔可夫逻辑网络。“机器学习62.1 - 2 (2006):107 - 136。
8。后来还推断(通过佩德罗·多明戈神经网络,再一次):
一族,罗伯特,佩德罗·多明戈。”深对称网络”。神经信息处理系统的进步27 (2014):2537 - 2545。