实践强化学习课程:第4部分
学习线性问

欢迎来到我的强化学习课程❤️
这是第4部分强化实践课程的学习,将你从零到英雄♂️。
第1部分:介绍强化学习
第2部分:表格q学习的
第3部分:表格撒尔沙
第4部分:线性Q学习(今天)
对不起让你久等,我不再续集,我想与你分享整个学习过程,所以你知道好的结果并不总是容易。但是一旦他们做麻烦️——它们是值得的。
今天,我们正在进入新的领域…。
一个领土whe重新强化学习与优化技术,在现代机器学习是必不可少的。一个杀手组合解决很多不同的问题和环境。
这个问题我们将是著名的车杆平衡,目的是平衡杆连接到车,动车左和右。
这就是深Q-Agent年底落实这冒险的样子:
这部分中我们将探讨的技术是令人印象深刻的成就背后的支柱领域的强化学习在过去的5到10年。
有很多东西消化,所以我们要将工作分为三部分:
- 在第4部分中(这个!)我们实现一个线性问代理okay-ish解决方案。
- 在第5部分中我们增加深度和实现一个深问代理来得到一个好的解决方案。
- 在第6部分中我们将看到如何微调hyper-parameters最大化性能。这里我们终于得到可怕的深问代理你看见上面!
在每个部分中,我们将加入新的想法,你需要掌握技巧,实现细节。更重要的是,我希望你能习惯失败在构建RL的解决方案。因为这是大部分时间会发生什么。
先进的RL技术,就像我们将看到的这三个部分,非常强大,但是需要仔细的实现和hyper-parameter调优。
调试RL算法不是一项容易的任务,成为更好的唯一方法就是通过犯错误。我最大的挫折之一,当我开始学习强化学习,是表面上的简单算法,以及极端困难当试图复制发表的结果。
强化学习是困难的,所以我们尽量不要使它更复杂化。一步一步走吧!
这节课的所有代码这Github回购。Git克隆它跟随今天的问题
别忘了给它一个⭐!


第4部分
内容
- 购物车️杆问题
- 环境、行为、状态的回报
- 随机代理基线
- 参数q学习的
- 你好PyTorch !
- 线性问代理
- 回顾✨
- 家庭作业
- 接下来是什么?❤️
1。购物车️杆问题
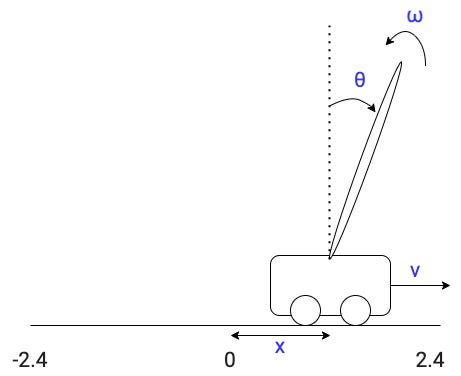
杆连着一个购物车un-actuated联合。和你的目标是将车位置,左和右,防止杆下降。
我们将使用的实现CartPole-v1你可以找到的OpenAI健身房。
为什么这个问题?
在到目前为止,我们已经使用传统强化学习算法,q学习(第2部分),和撒尔沙(第3部分)在一个离散/表格的环境。
今天的问题是更复杂,因为其离散状态空间太大。相反,我们需要升级游戏和使用更强大的RL算法。
我们将使用参数q学习的一种技术,它结合了经典的q学习我们在第2部分中看到的,与参数近似线性的(在第4部分)或者一个更复杂的神经网络(第5部分)。
参数q学习使用神经网络(又名深q学习)背后的许多最近的突破在强化学习,像著名的由DeepMind雅达利游戏机。
让我们熟悉这个环境的细节!
2。环境、行为、状态的回报
国家是由4个数字:
- 车的位置x从-2.4到2.4。
- 车的速度v
- 极角θ从-12年到12度对垂直(从-0.21到0.21弧度)
- 北极角速度ω。这是的变化率θ。

一集时终止:
- 购物车超出了限制:x > 2.4或x < -2.4
- 北极太远离垂直。θ> 12度或θ< -12度。
- 或者我们达到的最大数量集的步骤,500。在这种情况下,代理完美的解决了这一事件。
初始状态是随机采样的时间间隔为每个状态[-0.05,0.05]。有时,起始位置非常接近平衡,这一事件是很容易的。其他时候,起始位置很不平衡,这是更难解决,,有时甚至是不可能的。
那车速度v和杆角速度ω。这些值有界吗?
首先,让我们来加载CartPole-v1环境。


如果你看看OpenAI健身房区间变量env.observation_space.low和env.observation_space.high你会发现这两个数字似乎任意大或小。


在实践中,这是不正确的。这两个v和ω窄的间隔,但这是你不能直接读的吗env对象。你只能看到他们的真实范围作为你的代理探索环境。
这是很重要的,因为我们今天将使用的模型,并在第5部分中,效果最好标准化的输入。在这种情况下,规范化。和规范化首先需要知道它的最大和最小值。这两个值v和ω不能读的env.observation_space。你需要估计他们使用一点探索。
这个注意的要点是:
⚠️不要盲目采取价值的
env.observaton_space每个国家的实际范围。
是怎样的行动我们的代理可以执行吗?
0:购物车推到左边。1:向右推购物车。
的奖励+ 1,每一步。这意味着剂使南极站的时间越长,累积奖励越高。
3所示。随机代理基线
笔记本/ 01 _random_agent_baseline.ipynb
像往常一样,我们使用一个RandomAgent来建立一个基线性能。


我们评估该代理使用1000集


计算的平均回报及其标准偏差。



让我们看看参数q学习可以帮助我们建立一个智能代理!
4所示。参数q学习的
在到目前为止,我们在离散/表格环境(在第2部分中)或原始的环境变成一个离散(第3部分)。
然而,最有趣的环境不是离散,但连续,离散和解决太大。
幸运的是,有RL算法直接在连续状态空间工作。
今天我们要使用参数q学习的。这个算法类似于原始的q学习第2部分中我们看到但适应工作在连续的设置。
状态方程为CartPole由4个连续的数字

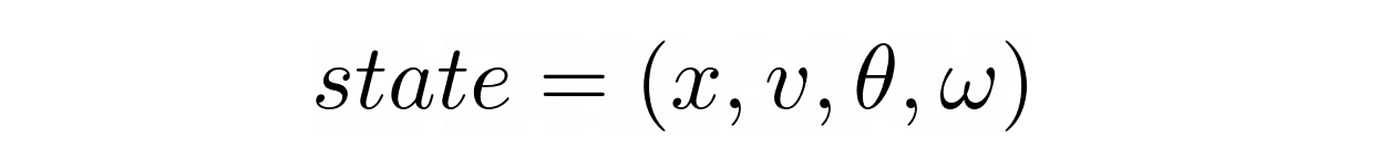
在哪里
- x是车的位置
- v是车的速度
- θ是极角
- ω杆角速度
在这样一个连续状态空间,最优核反应能量函数

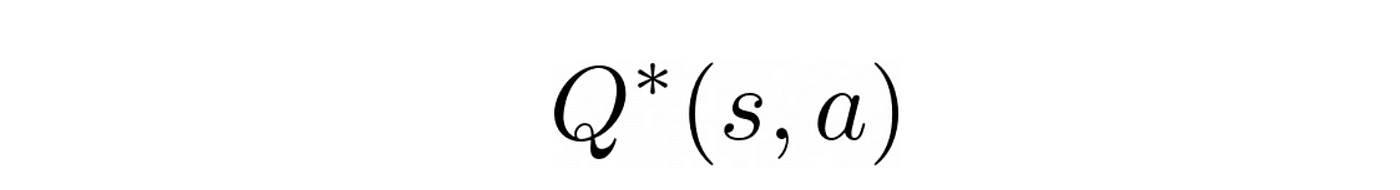
不能被表示为一个表(因为它会无限的尺寸)。
相反,我们代表使用参数形式


在哪里
问*是一个模型体系结构,像一个线性模型,或一个很深的前馈神经网络。- 这取决于我们将一组参数估计使用经验(s, r, s ')代理收集在训练。

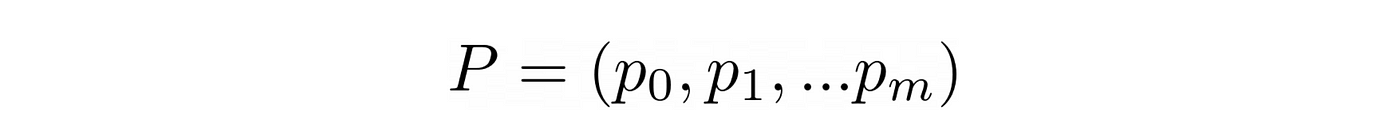
的选择模型架构Q *是至关重要的学习一个好的政策和解决这个问题。
多个参数模型,更灵活。和更高的很有可能这是一个很好的模型问题。事实上,神经网络的线性模型只是一个特例,没有中间层次。
今天我们要使用一个线性模型,为简单起见,在接下来的演讲中,我们将介绍一个更深层次的(我。e层)神经网络模型,以提高性能。
一旦你选择模型架构问*,你需要找到最优参数P。
好吧,但你怎么学习向量的参数P吗?
我们需要一个迭代的方法来找到更好的估计这些参数P代理收集更多的经验在训练,收敛于最优参数P *


现在,这个函数Q * (s, P)满足了贝尔曼最优性方程,方程在强化学习的关键

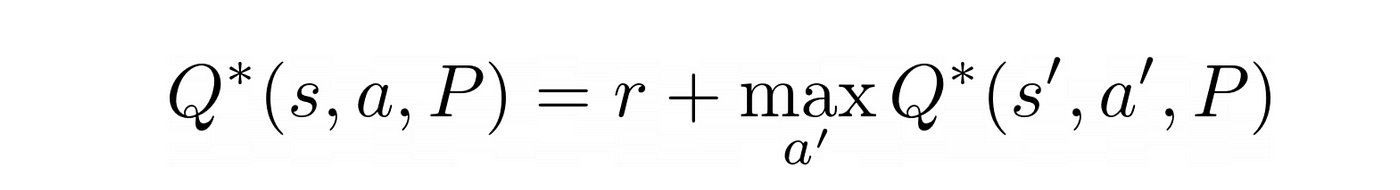
它告诉我们,未来的最大回报Q * (s, P)是奖励r代理接收输入的当前状态年代加上未来的最大奖赏下一个状态年代”。
最优参数P *是那些把等式左边尽可能接近右边。
这是一个优化问题,可以解决现代机器学习技术。更准确地说,监督机器学习技术。
监督毫升的问题有三个成分:
- 输入
特性和相应的目标 - 一组
参数我们需要确定 - 这取决于这些模型架构
参数这地图特性来模型输出
我们的目标是找到的参数使模型输出匹配目标值

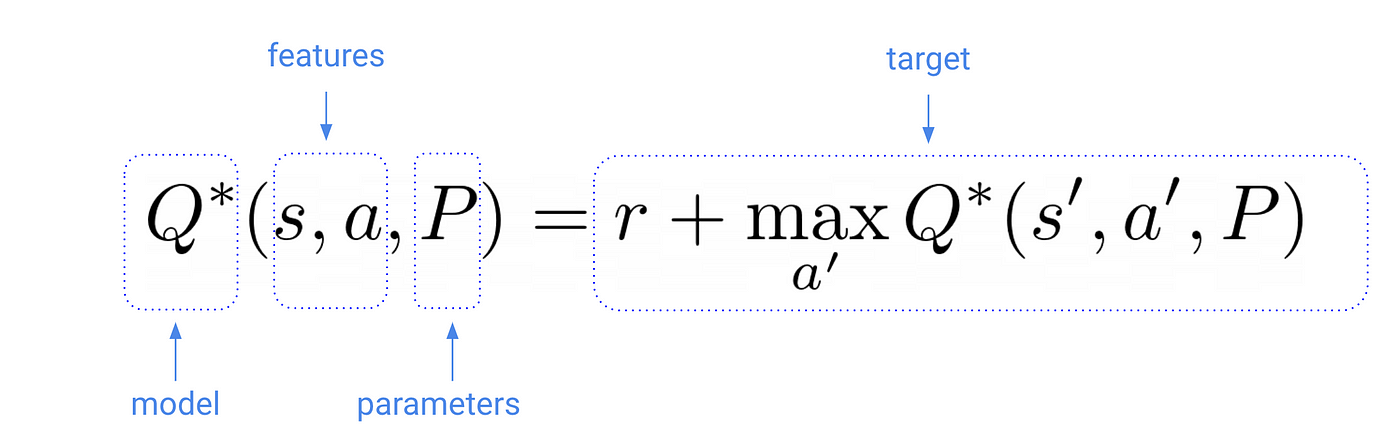
换句话说,我们想要找到的参数P *最小化的距离,又名损失毫升的术语。

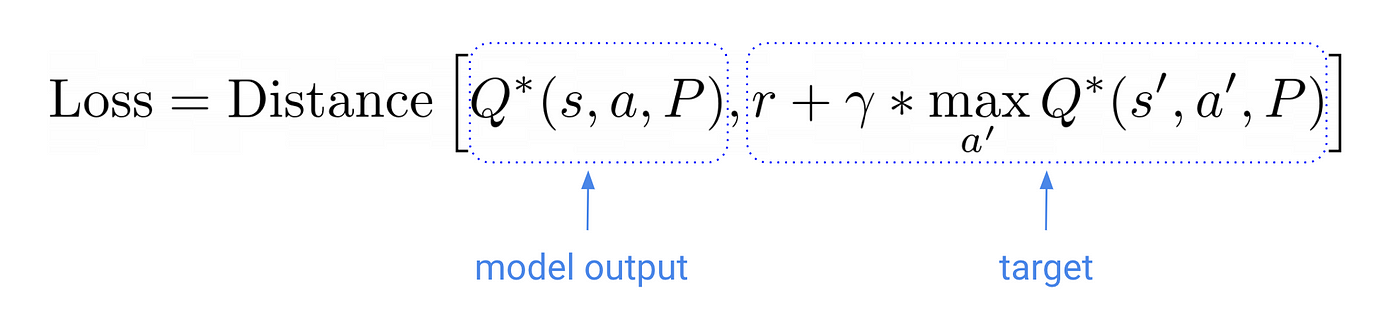
一个经典的算法来解决这个优化问题在机器学习世界是随机梯度下降法(SGD)方法。更准确地说,mini-batch随机梯度下降法。
鉴于你目前的估计P⁰,mini-batch经验(s, r, s ')和一个合适的学习速率你可以改善你的估计P⁰与SGD更新公式

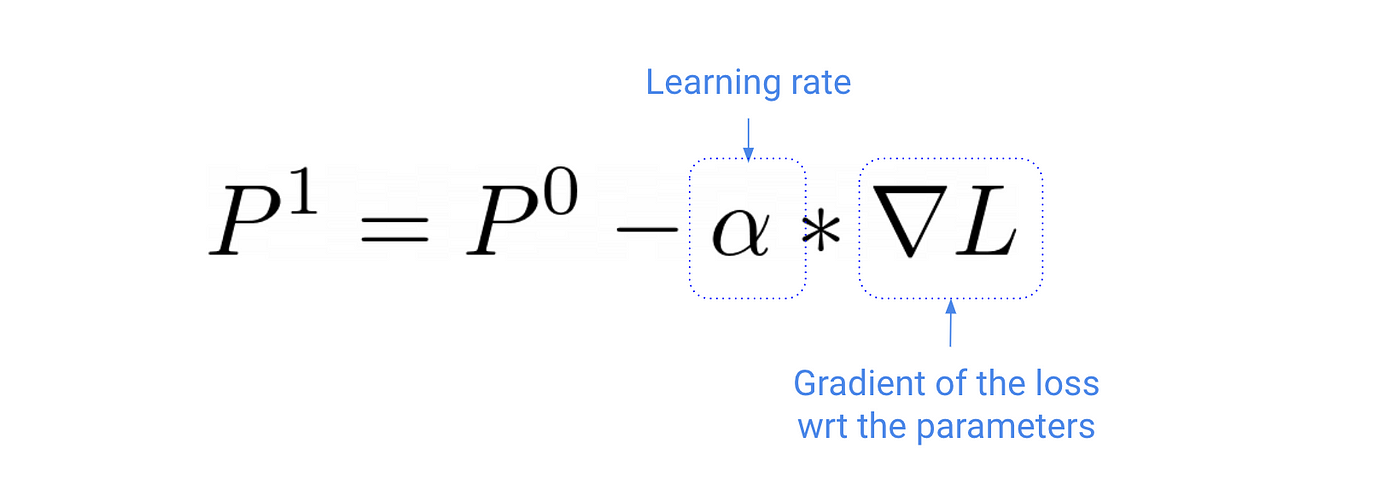
失去对参数的梯度,∇L是一个向量的分量是损失的敏感性对向量中每个组件的参数。
在实践中,你永远不需要计算梯度。Python库像PyTorch或TensorFlow为你做这些,使用一种算法反向传播,也就是微积分链式法则的一个花哨的名字你可能已经学会了年前的高中。
让我们来总结一下:
- 为我方的代理探索环境,你收集批次的经历,你使用这些更新参数使用SGD更新公式。
- 如果你重复这个时间足够长,你就会(希望如此)的最优参数P *,因此最优问*价值函数。
- 从最优Q *函数可以得到最优策略


瞧!这是参数q学习如何工作!
但等待一秒…
你为什么说“希望收敛到最优的“上面吗?
而不是表格设置,有很强的保证q学习的工作,事情更多脆弱的参数版本。
从本质上讲,是什么原因导致事情打破目标值的优化问题

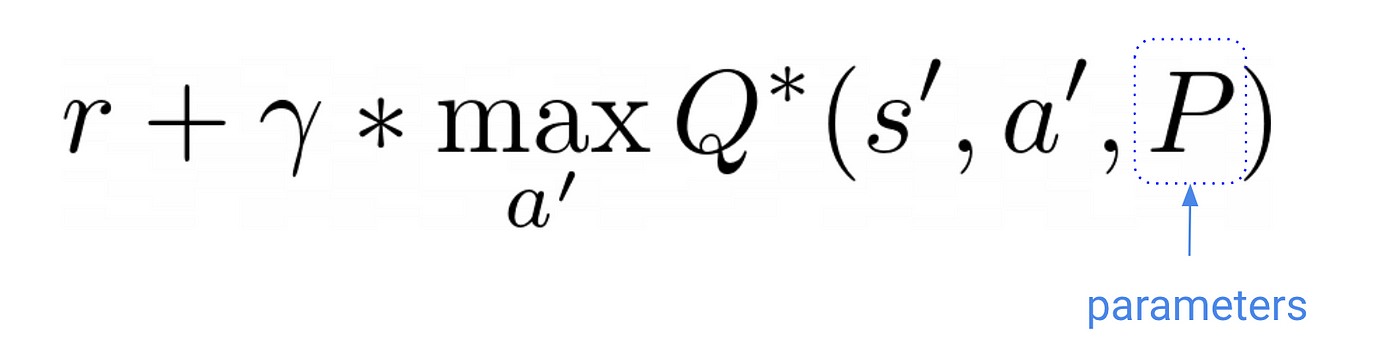
改变我们更新的参数估计。在培训目标的变化。他们搬
这显然小细节是难以解决的问题。
希望,研究人员有创造性和介绍了一些诀窍和技巧✨来解决这个问题。
技巧1:✨慢更新的目标
如果移动目标是一个问题,我们可以尽量少移动它们吗?
答案是肯定的。我们可以通过使用两个不同向量的参数:
- 病人:主要模型参数(左边)。这些是每个SGD更新后调整。像预期的那样。
- Pᵀ:目标模型的参数(右边)。这些参数保持固定SGD更新期间,我们只重置他们的P每相匹配展开迭代。

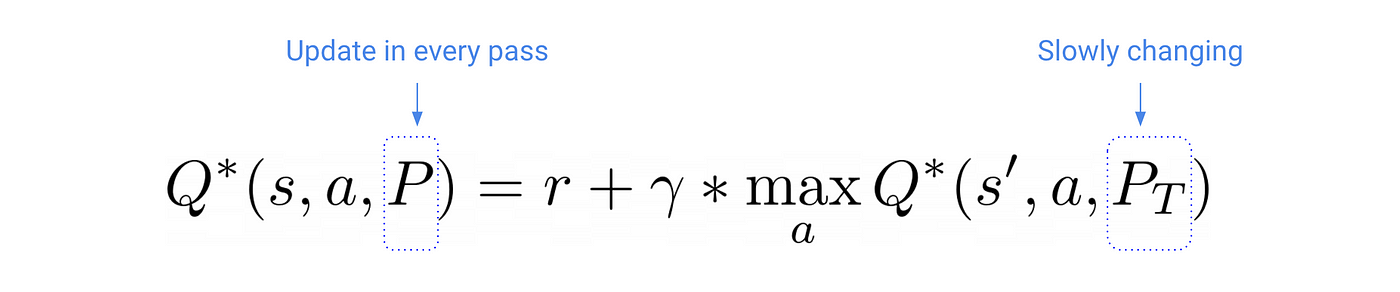
更新的频率Pᵀ是一个hyper-parameter我们需要调整。
技巧2:✨回放记忆
q学习是一个离线算法。这意味着贝尔曼方程适用于任何代理经验(s, r, s '),无论政策代理。
因此,过去的经验可以组合与SGD批次和用于更新参数更新。
像这样创建批次的数据消除了相关之间的经历,这是特别有用的训练神经网络模型更快。
有多少经验我们应该存储在该内存吗?
这个数字(即内存大小)是一个hyper-parameter,我们需要调整。
今天你需要相信我hyper-parameters我们将使用,等待第6部分,看看我们得到。
装机hyper-parameters不是一种艺术,而是一门科学。
在第6部分中我们将看到如何使用非常流行的Python库Optuna
最后,如果你已经建立了神经网络模型与PyTorch图书馆你可以跳过下一节。否则,让我把你介绍给你的下一个最好的朋友
5。你好PyTorch !
PyTorch是一个Python库,让你训练可微的模型,包括线性模型和神经网络。
PyTorch就是的图书馆其余的课程我们将使用的监督毫升问题我们需要解决参数强化学习算法,如参数q学习的。
PyTorch很Python接口(而不是Tensorflow),我相信你会把它捡起来快。
PyTorch背后的关键特性是它的自动分化引擎,这对我们计算我们需要更新模型参数的梯度。
的主要构建块训练脚本PyTorch是:
一批输入数据,包含功能和目标。
的模型定义作为一个Python对象封装torch.nn.Module你只需要实现向前传递,即从输入到输出的映射。例如,


一个损失函数例如,torch.nn.functional.mse(均方误差),计算损失模型输出和目标。
一个优化器,就像torch.optim.Adam(复杂的版本的SGD),调整模型参数,以减少损失函数的批处理输入数据。
这四个成分组合在一个循环中,又名循环训练监督的机器学习问题。


这个脚本结束时,如果你的模型体系结构是合适的数据,你的模型将这样的参数model_output非常非常接近吗目标值


这是你如何解决与PyTorch参数函数近似。
足够的说话。让我们搬到代码和实现一个线性问代理!
6。线性问代理
我们使用以下模型映射输入州核反应能量函数(也就是我们的q函数):

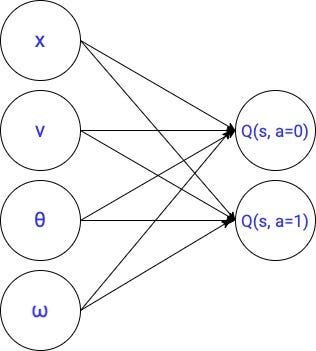

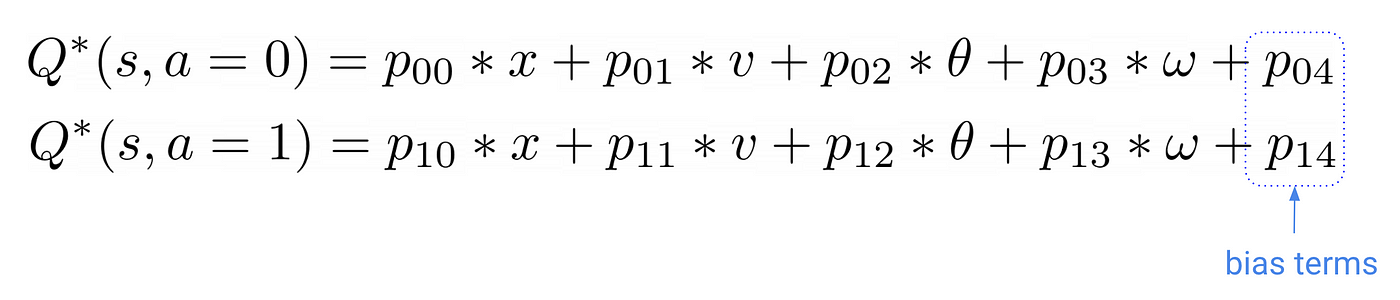
参数的数量等于输入和输出之间的连接数量的细胞(即4 x 2 = 8) + 2偏见方面我们通常添加到这些线性层来增强他们的表现力。这给了总共10参数。
这不是一个非常灵活的模型,但是今天就够了。在接下来的演讲中,我们将使用更强大的神经网络模型。
现在,让我们去hyperparameters…
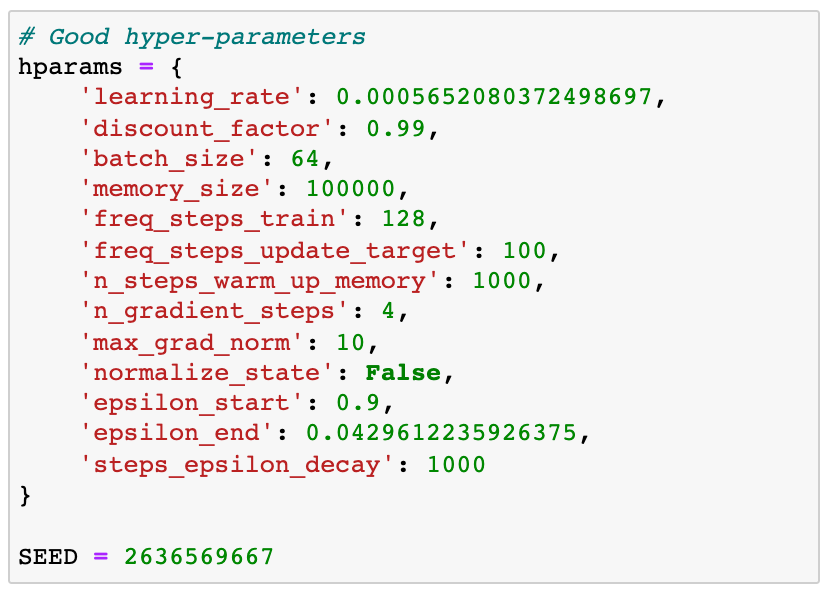
我创建了两个笔记本。一个与坏hyper-parameters和其他好的人。
在两节课中,我们将看到如何通过实验发现这些值。目前,他们相信我是最好的我能找到(最差)
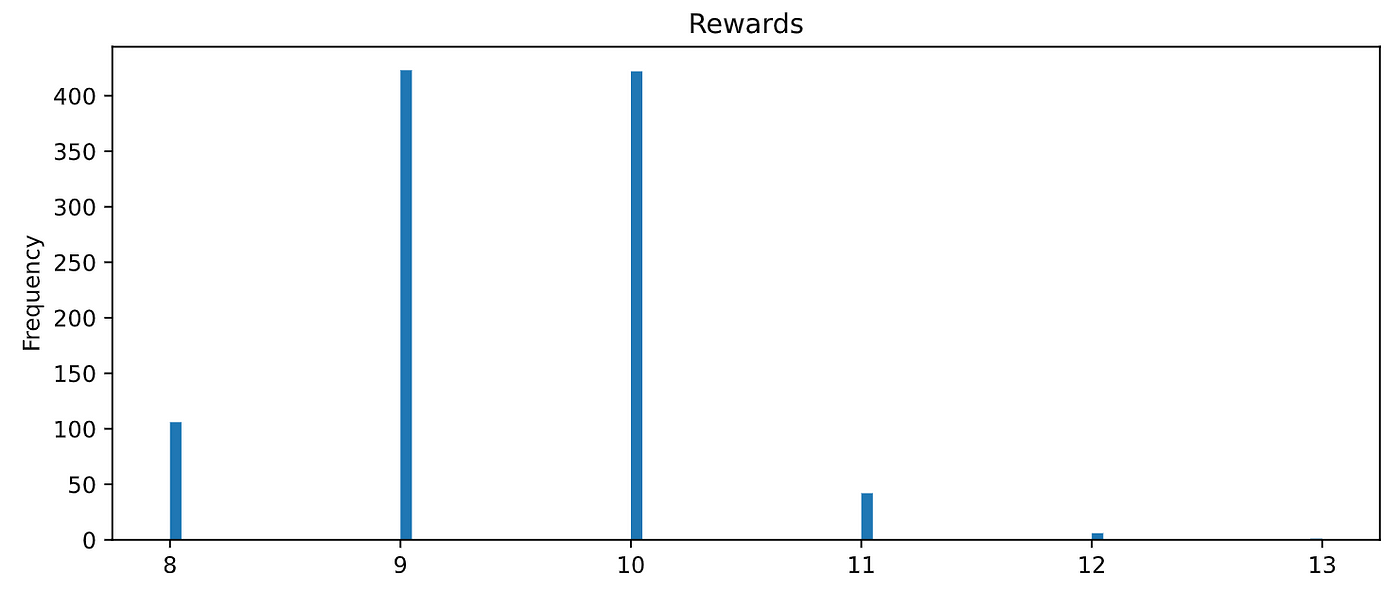
坏hyper-parameters

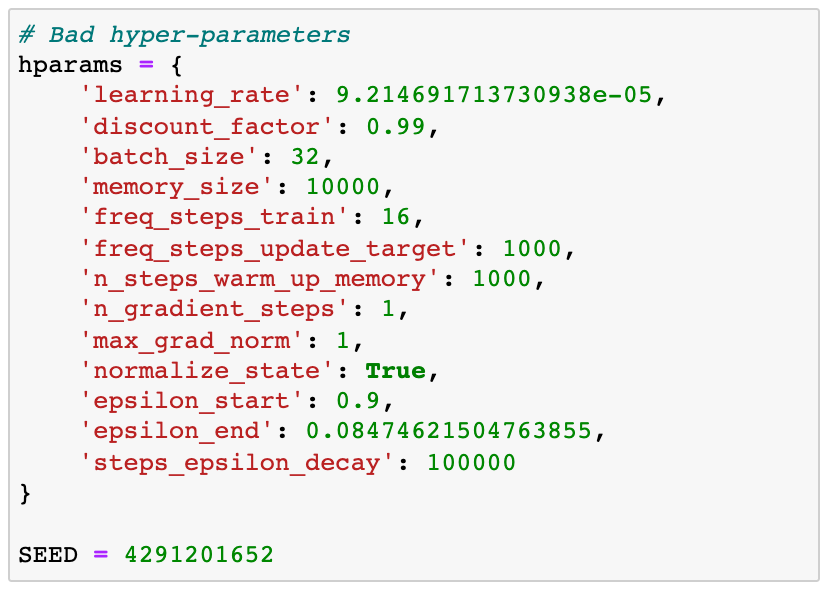
我们解决所有随机种子,以确保再现性


然后我们创建QAgent对象


我们训练了2000集:


我们在1000个随机运行评估它的性能

结果看…


很糟糕!
他们是比基线RandomAgent!

让我们看看会发生什么当你使用好hyper-parameters。
好hyper-parameters

我们重复相同的步骤来训练代理,然后我们评估其性能:


惊人的结果!
你可以画出整个分布看到代理一直成绩100以上!
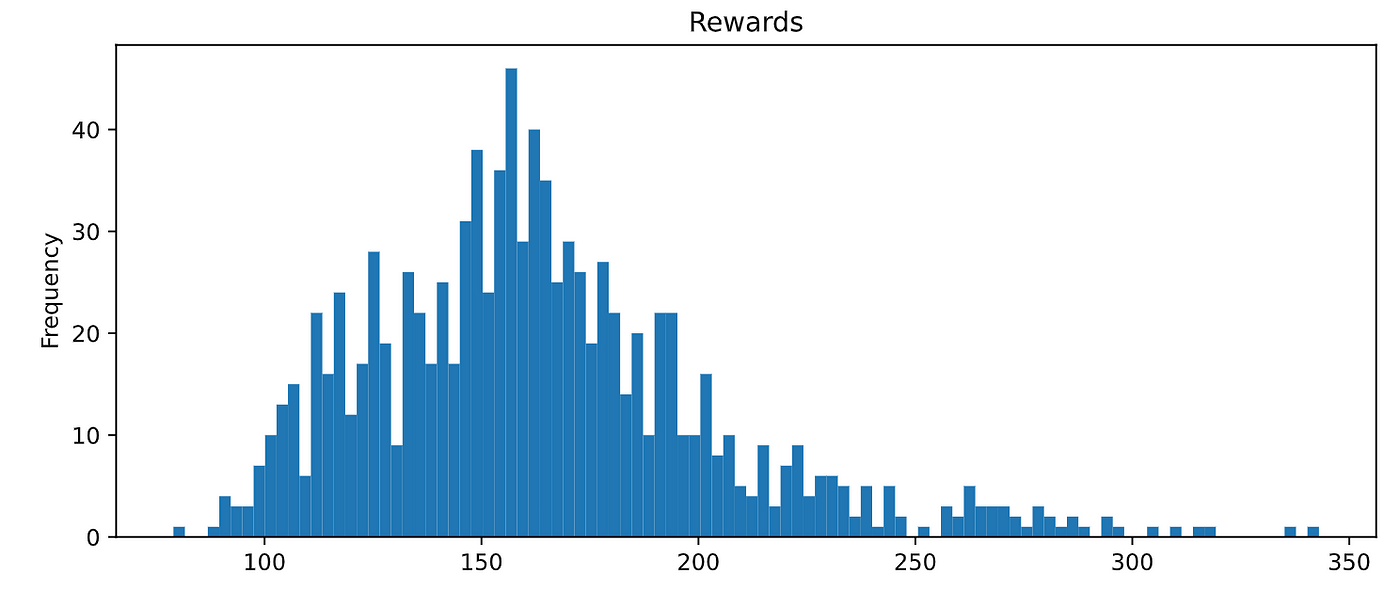
哇!一个巨大的影响hyperparameters所训练的结果。
Hyper-parameter敏感性
强化学习代理使用参数近似hyper-parameters非常敏感。通常,他们也很敏感的随机种子用来控制所有来源的随机性在训练。
这使得很难繁殖的结果发表在报纸和杂志,除非hyper-parameters都提供。
是一个伟大的纸有再现性在现代/深强化学习,我强烈推荐你阅读
我们今天取得足够的进展,建立我们的第一个参数问代理。
时间停下来回顾。


7所示。回顾✨
这些是3关键外卖:
- 参数Q学习是一个功能强大的算法,结合经典RL (Q学习)函数近似(监督毫升)。
- 你使用的参数化是保证算法收敛于最优解的关键。今天,我们使用了一个线性模型,但在接下来的部分,我们将使用更灵活的模型:一个神经网络。
- Hyper-parameters至关重要,可以一个协议的破坏者。
8。家庭作业
这就是我想要你做的事:
- Git克隆回购到您的本地机器上。
- 设置这节课的环境
03 _cart_pole - 开放
03 _cart_pole /笔记本电脑/ 04 _homework.ipynb并尝试完成2挑战。
在第一个挑战,我想让你尝试不同的种子价值观和重新培训代理使用好hyper-parameters我给你们。你还得到良好的性能吗?或者做结果更多的是依赖种子你使用吗?
在第二个挑战,我问你今天使用的方法和代码来解决MountainCar-v0环境第3部分。你能使用线性分数99%分数q学习的吗?
9。接下来是什么?❤️
下节课,我们要把我们第一次深神经网络,创建我们的第一个深问代理。
令人兴奋,不是吗?
让我们一起继续学习!