理解ML监控债务
本文是正在进行的系列文章的一部分,该系列文章探讨ML监控债务、如何识别债务以及管理和减轻其影响的最佳实践

我们都很熟悉软件工程中的技术债务,在这一点上,ML系统中隐藏的技术债务几乎是教条。但是ML监控债务是什么呢?ML监视债务是当模型监视被它要监视的ML系统的规模压倒时。练习者只能大海捞针,或者更糟的是,在警报中点击“全部删除”。
ML监控与此相去甚远与传统的APM监控一样清晰。当涉及到度量和基准时,不仅没有绝对的真理,而且模型也不受规模经济的影响。创建一个新的Kubernetes集群很容易,该集群将遵循与其前身相同的性能指标、基准、阈值和kpi。但是当您部署一个新模型时,即使它是一个已经存在的模型,并且工件没有任何更改,实际上也可以保证您的引用将是不同的。这意味着您将为部署到生产和监视的每个模型承担债务。
什么是糟糕的性能级别?
80%的准确率?60%的准确率?
要确定好的/坏的性能水平需要考虑多个因素,根据每个模型的用例、段,当然还有数据,底线是不同的。在这篇文章中,我们将解释ML模型监控的债务维度“大数据的四个V”框架,它非常适合进行这种比较。
1.真实性
高维度
测量和监视依赖于2-3个元素的数据驱动过程相当简单。但是ML主要是利用大量的数据源和实体来定位底层的、可预测的模式。根据问题和相关数据的不同,您可能要查看几十个功能,甚至成百上千个功能,每一个功能都应该被独立地监视。
模型指标
ML是一个随机的面向数据的世界,由生产中的多个不同管道组合而成。这意味着需要为每个实体跟踪和监视大量的度量和元素,例如特征平均值、标准、数值元素的缺失值和基数水平、熵,以及类别元素的更多值。全面的模型度量超越了特性、数据和管道完整性,提供了可量化的度量来分析模型输入和输出的相对质量。
2.体积
ML监控中的容量需要从两个维度进行分析:吞吐量和粒度
吞吐量
模型通常处理大量数据,以实现决策过程的自动化。这对监视和观察数据集的分布和行为提出了工程挑战。监视解决方案需要在几分钟内检测数据质量和性能问题,同时分析大量的数据流。
分辨率的数据
要在亚种群水平上检测事物,需要有按段划分数据的能力,但这也是一个分析挑战。对于相同的度量,在不同的子种群下,数据的性质和模型的性能可能有很大的不同。


例如,一个名为“年龄”的功能的缺失值指标通常占总体的20%,但对于一个特定的渠道,如Facebook,该值可能是可选的,在60%的情况下是缺失值,而在所有其他亚人群中,只有0.5%的情况下是缺失值。
高级视图只能提供这么多信息,特别是关于支持业务需求和决策的关键的子群体和详细的解决方案。影响整个数据集或人口的宏观事件是每个人都知道要注意的事情,通常可以相对较快地检测到。
但这意味着,在巨大的数据流中检测问题的工程和分析挑战,现在因需要监控的不同部分的数量而成倍增加。
3.速度
模型以不同的速度服务于业务流程的自动化,从每天、每周的批量预测到大规模的实时ms决策。根据您的用例,您需要能够支持不同类型的速度。不过,和体积一样,速度还有一个额外的维度需要应对,那就是管道速度。将整个推理流视为持续改进的管道。为了快速移动而不破坏东西,您需要将延迟反馈重新整合到您的ML决策过程中。
在某些用例中,例如广告技术实时竞价算法,我们需要监视每周的影响,因为我们需要能够在几分钟内检测数据质量或性能问题,以避免业务灾难。
4.各种
最后但同样重要的是,我们谈到了多样性。一个具有业务ROI的成功模型跨越了更多的模型。一旦您通过了第一个模型障碍,并证明了ML对业务结果的积极影响,您的团队和业务都希望复制这种成功并扩大其规模。有三种方法来缩放模型,它们并不相互排斥。
版本
ML是一个迭代的过程,版本是我们实现它的方式。现实世界不是静态的,因此管道和模型必须不断优化。版本不断地为相同的现有模型创建,但每个版本实际上是一个完全不同的模型实例,可能具有不同的特性,甚至不同的基线。
用例的规模
向您的库中添加一个用例意味着您实际上是从头开始重新启动整个MLOps周期。您可以进行许多事情,特别是涉及到特性工程时,但是当您部署到生产时,您将有一组新的模型度量要监视。除了ML监视的技术方面之外,模型驱动业务流程,而且每个流程都是不同的。对于相同的贷款批准模型,风险和合规团队可能会担心由于监管方面的担忧而产生的潜在偏差,业务运营人员希望第一个知道模型是否突然决定全面拒绝贷款,ML工程师需要知道完整性和管道问题,而数据科学团队可能对模型预测中的缓慢漂移感兴趣。关键是它是多学科的,您的涉众对ML决策过程的不同方面感兴趣。在一个新的过程中,你需要确保快速地交付价值。
多租户规模
多租户具有指数级容量。决定跨多个原则部署模型是在租户本身等于总体时使用的。例如,部署一个检测潜在客户流失的学习过程,但在每个国家(在本例中是租户)上是分开的。结果是每个国家都有一个独立的模型。


做出这样的决定可能会让你在一夜之间从一个欺诈模型变成数百个欺诈模型。虽然他们可能共享相同的指标集,但预期价值和行为会有所不同。
我们已经了解到的关于债务监控模型的内容
从表面上看,模型监视似乎很简单。公平地说,对于一个或两个模型,如果您愿意投入资源,手动监视ML是可行的。但是在ML工程中,就像软件工程一样,一切都是债务和规模的问题。它是否值得承担并在以后偿还?模型监视不是一项简单的任务,从技术和流程的角度来看也不直接,而且随着您的扩展,管理ML监视的难度也会增加。
4v说明了为什么模型监控是复杂的,作为量化这个问题的练习,让我们考虑以下数字:

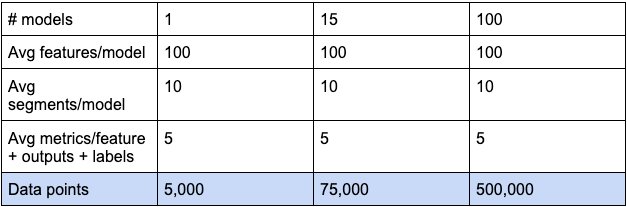
既然我们已经量化了ML监控的固有规模问题及其原因,下一步就是确定债务。本系列的以下部分将讨论确定债务指标和管理和克服债务监测模型的最佳实践。
请继续关注!