数据库
从原始数据到清理数据库:深入挖掘通用数据工具包
一个使用通用数据工具包(VMware最近发布的一个框架)和Trino DB的完整示例
最近,VMware发布了一个新的开源工具,叫做多才多艺的数据包(简称VDK),它允许非常快速地管理数据。该工具允许通过很少的代码行将不同格式的数据输入到单个数据库中。
在我的前一篇文章,我描述了一个基本的例子,它使用VDK,并描述了如何安装它并使它运行。总之,你应该:
- 有一个正在运行的数据库(VDK外部)
- 在VDK中配置到数据库的接口,包括用户名、密码、主机和端口
- 在VDK中定义如何摄取数据库中的数据,使用SQL查询或Python实现的更复杂的过程。
一旦您在数据库中摄取了数据,您就可以随心所欲地使用它们,例如,构建有趣的仪表板或可视化。
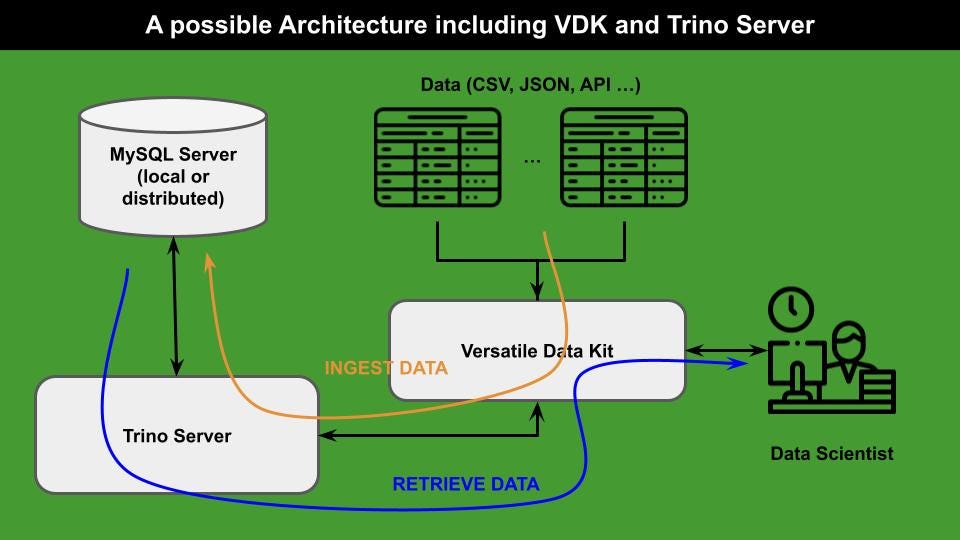
在这种基于“增大化现实”技术t在本文中,我将重点介绍一个完整的例子,它从数据摄取开始,一直到数据处理。这个例子使用了一个带MySQL服务器的Trino数据库来存储数据,VDK在数据库中吸收数据。
如下图所示,可能的架构包括VDK、Trino Server和MySQL Server:
文章具体组织如下:
- 场景定义
- 数据库的设置
- VDK中的数据摄入
- VDK中的数据处理
1场景定义
该情景的目的是分析美国不同地区的预期寿命,并将其与该地区的国内生产总值(GDP)进行比较。为了实现这一目标,您应该下载与美国预期寿命相关的数据,并将它们与相关的GDP合并。
这个示例展示了如何通过VDK提取和集成该场景所需的数据。
我们可以使用以下两个数据集,它们都可以作为CSV文件使用:
前面的数据集在美国政府工作许可证。
除了前面的数据集,我们还可以使用下面的其他数据集:
前两个数据集分别由美国经济分析局(U.S. Bureau of Economic Analysis)和美国人口普查局(U.S. Census Bureau)发布,都是在公共许可下提供的公开数据。
数据集2010-2015年,美国各州出生时预期寿命和人口普查数据包含了73,121份美国人预期寿命的记录,按州和县划分,涉及到2010-2015年期间。
下图显示了数据集的摘录:


数据集《美国各州性别预期寿命》(U.S. State Life Expectancy by Sex, 2018)包含了156项与2018年美国人预期寿命相关的记录,按州和性别(男性、女性、总寿命)划分。下图显示了数据集的摘录:


美国各州的国内生产总值数据集包含了3163条记录,这些记录与美国各州的实际国内生产总值有关,涉及到2017-2020年这一时期。数据集包含许多列。下图显示了数据集的摘录:


美国各州的国内生产总值数据集包含了3163条记录,这些记录与美国各州的实际国内生产总值有关,涉及到2017-2020年这一时期。数据集包含许多列。下图显示了数据集的摘录:

2安装数据库
我们将所有的数据存储在一个Trino数据库作为一个MySQL服务器的接口。Trino是一个用于大数据分析的分布式开源SQL查询引擎。它运行分布式和并行查询,速度非常快。对于Trino数据库的设置,您可以按照以下步骤进行我之前的教程。
在本例中,Trino在本地运行,其最小值如下config.properties配置文件:
协调员= true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5 gb
query.max-memory-per-node = 1 gb
query.max-total-memory-per-node = 2 gb
discovery.uri = http://127.0.0.1:8080
http-server.https.enabled = false
此外,Trino DB使用MySQL目录,配置如下(文件mysql.properties位于Trino服务器的目录文件夹中:
connector.name = mysql
连接url = jdbc: mysql: / / localhost: 3306
连接用户=根
连接密码=
allow-drop-table = true
最后,这个示例假设调用一个空模式人均预期寿命MySQL服务器上存在。
3 VDK数据吸收
VDK使用以下配置运行(config.ini):
db_default_type = TRINO
ingest_method_default = trino
trino_catalog = mysql
trino_use_ssl =
trino_host = localhost
trino_port = 8080
trino_user =根
trino_schema =人均预期寿命
trino_ssl_verify =
Data Ingestion将数据源部分中定义的两个CSV表上载到数据库中。对于每一个表,数据的摄取将通过以下步骤进行:
- 删除现有的表(如果有的话)
- 创建一个新表
- 直接从CSV文件摄取表值。
前两个步骤将使用SQL语言编写,而最后一个步骤将使用Python编写。
每个数据集将在一个名称与数据集名称相似的表中被摄取。例如,2010-2015年,美国各州出生时预期寿命和人口普查数据数据集将被摄入life_expectancy_2010_2015表格
3.1删除已有表
首先,我创建了一个名为01 _delete_table_life_expectancy_2010_2015.sql:
删除表如果存在life_expectancy_2010_2015
数量01脚本名称前面表示VDK框架将作为第一个脚本运行。
我还创建了02 _delete_table_life_expectancy_2018.sql脚本,该脚本删除life_expectancy_2018表和要删除的其他脚本us_regions和us_gdp表。
3.2创建新表
现在,我为新表创建模式,并将其存储在03 _create_table_life_expectancy_2010_2015.sql脚本:
创建表life_expectancy_2010_2015 (
州varchar (32),
县varchar (32),
CensusTractNumber varchar (32),
LifeExpectancy小数(4,2),
LifeExpectancyRange varchar、
LifeExpectancyStandardError小数(4,2)
)
与前面的脚本类似,我创建04 _create_table_life_expectancy_2018.sql:
创建表life_expectancy_2018 (
州varchar (32),
性varchar (32),
1小数(3,1),
SE小数(3,1),
四分位数varchar (32)
)
还有us_regions和us_gdp表:
创建表us_regions (
州varchar (32),
StateCode varchar (2),
地区varchar (32),
varchar (32)
)创建表us_gdp (
县varchar (32),
Year2017长整型数字,
Year2018长整型数字,
Year2019长整型数字,
Year2020长整型数字
)
3.2直接从CSV文件中获取表值
最后,我可以在life_expectancy_2010_2015表格我使用了IJobInputVDK API提供的类。我定义一个run ()函数,它将被VDK框架读取,在它里面,我写摄取代码:
以pd身份进口大熊猫
从vdk.api。job_input进口IJobInputdef运行(job_input: IJobInput):#读取CSV文件url = " http://data.cdc.gov/api/views/5h56-n989/rows.csv "
dtypes = {
“状态”:str,
“县”:str,
"Census Tract Number": str,
“寿命”:np.float64,
“预期寿命范围”:str,
"Life Expectancy Standard Error": n .float64,
}df = pd。dtype = dtypes read_csv (url)。取代 ("'", "''", regex = True)
df。列= df.columns.str。替换(" "," ")#摄取CSV文件job_input。send_tabular_data_for_ingestion(
df.itertuples(指数= False),
destination_table = " life_expectancy_2010_2015 ",
column_names = df.columns.tolist ()
)
为了摄取数据库中CSV的每一行,我使用send_tabular_data_for_ingestion ()的方法IJobInput类。
我们可以用同样的技术吸收其他数据集。
4 VDK数据处理
数据处理包括以下任务:
- 干净的桌子
- 合并清理过的桌子
4.1清洁表
打扫life_expectancy_2010_2015表中包含以下两项操作:
- 县分组记录
- 拆分的列
LifeExpectancyRange在两个小数列中MinLifeExpectancyRange和MaxLifeExpectancyRange。
清洗过程的输出为life_expectancy_2010_2015表存储在一个新表中,称为cleaned_life_expectancy_2010_2015。
以上两种操作都可以通过SQL语句来实现:
创建表cleaned_life_expectancy_2010_2015作为(选择状态,
LifeExpectancy,
cast(split(life_expectancy_2010_2015.LifeExpectancyRange,'-')[1] AS decimal(4,2)) AS MinLifeExpectancyRange,
cast(split(life_expectancy_2010_2015.LifeExpectancyRange,'-')[2] AS decimal(4,2)) AS MaxLifeExpectancyRange,
LifeExpectancyStandardError
从life_expectancy_2010_2015
在哪里县= '(空白)'
)
在数据集中,具有县= '(空白)'包含给定县的预期寿命的总和。因此,只需选择这些行,我就可以轻松地按县进行分组。
生成的表格如下图所示:

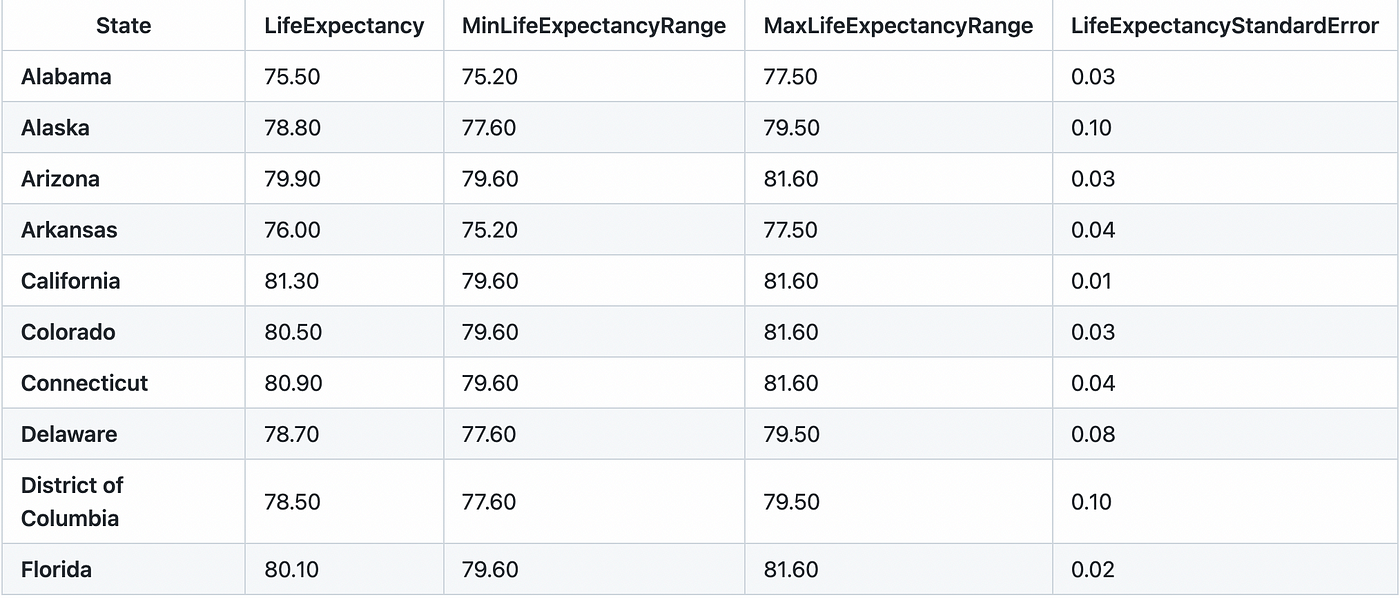
现在,我打扫life_expectancy_2018表格打扫life_expectancy_2018表中包含以下操作:
- 重命名列
1来LifeExpectancy - 重命名列
SE来LifeExpectancyStandardError - 拆分的列
四分位数在两个小数列中MinLifeExpectancyRange和MaxLifeExpectancyRange - 只选择包含以下内容的行
性别=“总”。
以上所有操作都可以通过一条SQL语句来实现:
创建表cleaned_life_expectancy_2018作为(选择状态,
1 LifeExpectancy,
(分裂(life_expectancy_2018。四分位数,' - ')[1] AS decimal(4,2)) AS MinLifeExpectancyRange,
(分裂(life_expectancy_2018。四分位数,' - ')[2] AS decimal(4,2)) AS MaxLifeExpectancyRange,
SE是LifeExpectancyStandardError从life_expectancy_2018
在哪里性别= 'Total' and State <> 'United States'
)
的示例cleaned_life_expectancy_2018表:


注意,清洗完毕后cleaned_life_expectancy_2010_2015和cleaned_life_expectancy_2018表具有相同的模式。
4.2合并清理后的表
最后,我准备合并所有的表。我执行以下操作:
- 垂直合并之间的
cleaned_life_expectancy_2010_2015和cleaned_life_expectancy_2018表; - 横向合并在结果表和
us_regions和us_gdp表。
垂直合并意味着将第二个数据集添加到第一个数据集,而水平合并将添加三个新列,称为期,国内生产总值和地区,到生成的表中,被命名merged_life_expectancy。的国内生产总值属性仅为记录设置时间= ' 2018 '。对于其他记录,它被设置为0,因为它不可用。
创建表merged_life_expectancy作为(选择us_regions。状态,
LifeExpectancy,
MinLifeExpectancyRange,
MaxLifeExpectancyRange,
“2010 - 2015”时期,
地区,
0作为国内生产总值
从cleaned_life_expectancy_2010_2015
加入us_regions
us_regions。状态= cleaned_life_expectancy_2010_2015.State
)联盟(选择us_regions。状态,
LifeExpectancy,
MinLifeExpectancyRange,
MaxLifeExpectancyRange,
“2018”时期,
地区,
Year2018作为国内生产总值
从cleaned_life_expectancy_2018
加入us_regions
us_regions。状态= cleaned_life_expectancy_2018.State
内连接us_gdp
us_gdp。县= cleaned_life_expectancy_2018。状态
在哪里Year2018 > 100000000
)
在第二个选择声明中在哪里指定条件Year2018 > 100000000。这只允许选择县。
最后的表格如下表所示:


总结
恭喜你!您刚刚学习了如何在VDK中摄取和处理数据!这可以通过用SQL和Python编写简单的脚本来实现。
可以获得此示例的完整代码在这里。
下一步是构建一个显示处理结果的报告。敬请关注,学习如何去做:)
如对通用数据集有疑问或疑问,可直接加入他们的公共松弛工作区或他们的邮件列表或在推特上关注他们。
如果你读到这里,对我来说今天已经够多了。谢谢!你可以在里面读到更多关于我的信息这篇文章。