神经网络
LSTM循环神经网络-如何教一个网络记住过去

介绍
标准循环神经网络(rnn)在处理较长的数据序列时,会出现消失梯度问题,从而影响短期记忆。
幸运的是,我们有更高级版本的rnn,它可以保存序列早期部分的重要信息,并将其发扬下去。最著名的两个版本是长短时记忆(LSTM)和门控循环单位(GRU).
在本文中,我将重点讨论LSTM并提供一个详细的Python示例供您使用。
内容
- LSTM在机器学习领域的地位如何?
- LSTM与标准rnn的区别是什么? LSTM是如何工作的?
- 一个完整的Python示例,展示了如何构建和训练自己的LSTM模型
LSTM在机器学习领域的地位如何?
下面的图表是我对最常见的机器学习算法进行分类的尝试。
While我们经常以有监督的方式使用带有标记的训练数据的神经网络,我觉得他们在机器学习方面的独特方法值得单独分类。
因此,我的图显示了神经网络(nn)从机器学习领域的核心分支出来。递归神经网络是神经网络的一个分支,包含标准神经网络、lstm和gru等算法。
下图是互动,所以请点击不同的类别来放大并显示更多.
如果你喜欢数据科学和机器学习,请订阅收到我的新文章的电子邮件。
LSTM与标准rnn的区别是什么? LSTM是如何工作的?
让我们先快速回顾一下一个简单的RNN结构。RNN类似于前馈神经网络,由多层组成:输入层、隐层和输出层。

然而,RNN包含复发性单位在它的隐藏层,允许算法处理序列数据.它通过递归地传递来自前一个的隐藏状态来实现步伐并将其与当前输入相结合。
时间步长-通过循环单元对输入进行单次处理。时间步长的数目等于序列的长度。
您可以在我的前一篇文章如果需要的话。
LSTM与标准RNN有何不同?
我们知道rnn利用复发性单位从序列数据中学习。LSTMs也是如此。然而,在循环单位内部发生的事情在这两者之间是非常不同的。
看看标准RNN的简化循环单元图(没有显示权重和偏差),我们注意到只有两个主要操作:将之前的隐藏状态与新的输入相结合,并通过激活函数传递它:

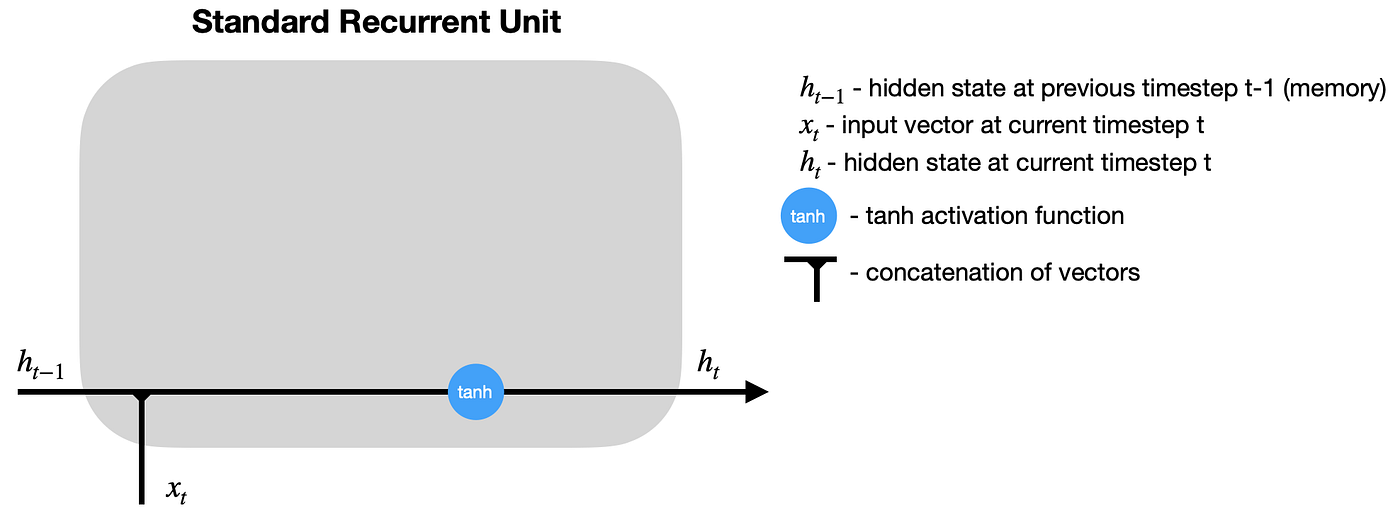
在时间步长t计算出隐藏状态后,为回到循环单位并结合时间步长t+1时的输入,计算出时间步长t+1时新的隐藏状态。这个过程重复t+2, t+3,…,t+n,直到达到预定义的时间步数(n)。
同时,LSTM使用各种门禁来决定保留或丢弃哪些信息。此外,它还添加了一个细胞状态,这就像LSTM的长期记忆。让我们来仔细看看。
LSTM是如何工作的?
LSTM循环单元比RNN复杂得多,提高了学习效率,但需要更多的计算资源。

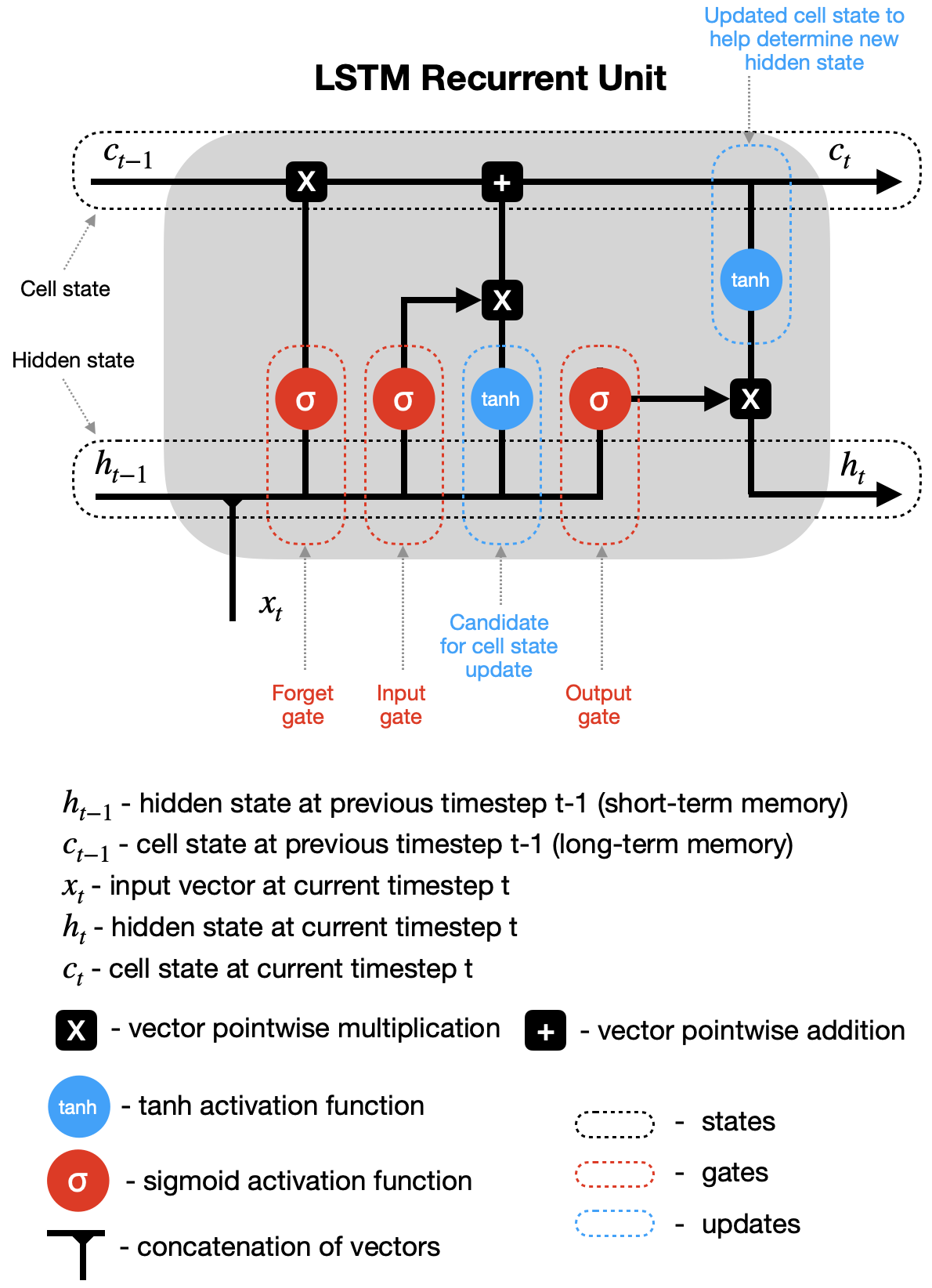
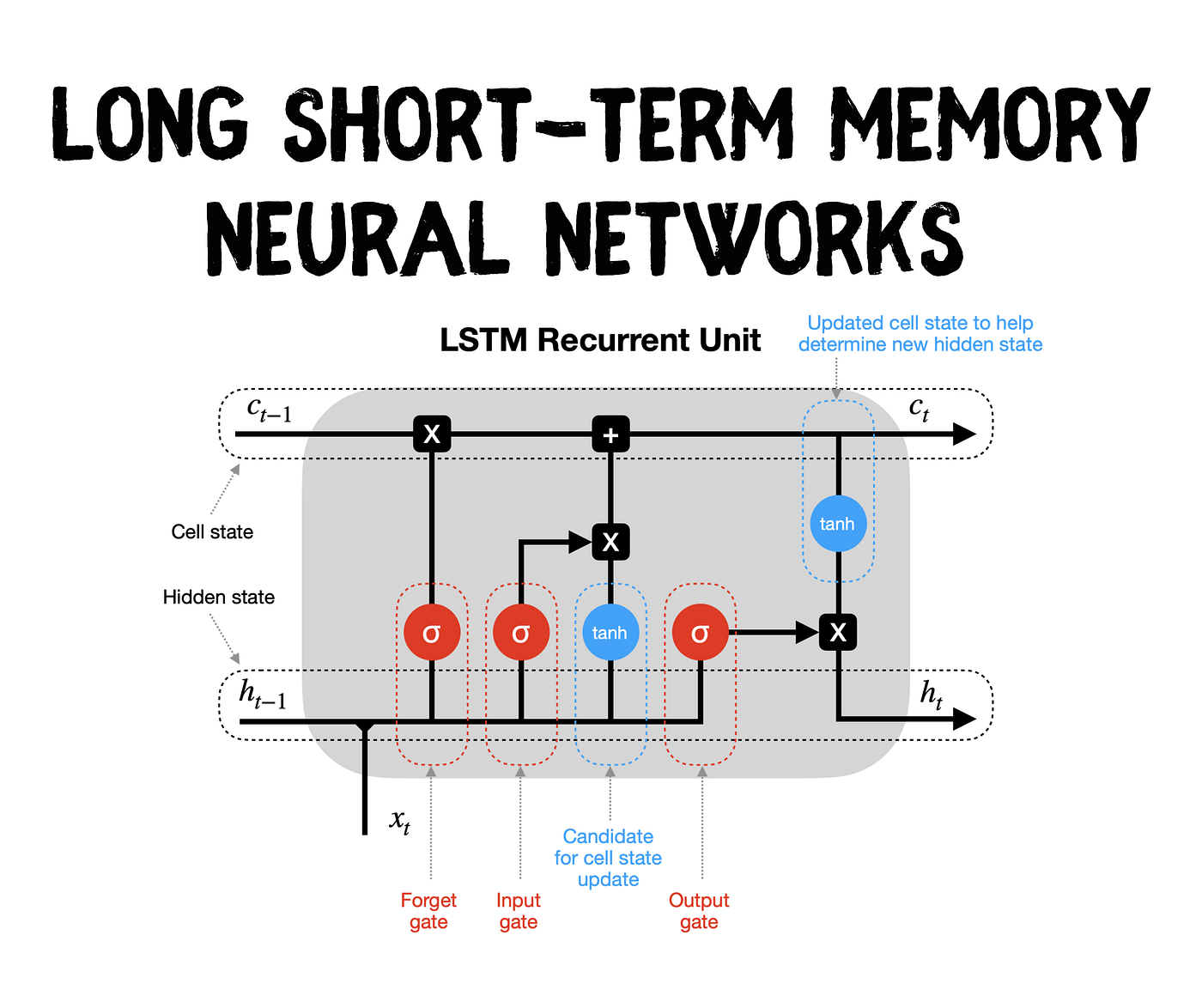
让我们通过简化的图表(没有显示权重和偏差)来了解LSTM循环单元如何处理信息。
- 隐藏状态和新输入-前一个时间步(h_t-1)的隐藏状态和当前时间步(x_t)的输入在通过各种门传递副本之前被合并。
- 忘记门这个门控制着哪些信息应该被遗忘。由于sigmoid函数的范围在0到1之间,它设置了哪些cell状态中的值应该丢弃(乘以0)、记住(乘以1)或部分记住(乘以0到1之间的某个值)。
- 输入门帮助识别需要添加到单元状态的重要元素。请注意,输入门的结果乘以单元状态候选,只有输入门认为重要的信息被添加到单元状态。
- 更新细胞状态-首先,前一个单元格状态(c_t-1)乘以遗忘门的结果。然后我们从[input gate × cell state candidate]中添加新的信息,得到最新的cell状态(c_t)。
- 更新隐藏状态-最后一部分是更新隐藏状态。最新的细胞状态(c_t)通过tanh激活函数传递,并乘以输出门的结果。
最后,最新的单元状态(c_t)和隐藏状态(h_t)返回到循环单元中,然后在时间步长t+1处重复过程.循环继续,直到我们到达序列的末尾。


一个完整的Python示例,展示了如何构建和训练自己的LSTM模型
我们可以以四种不同的方式使用lstm:
- 一对一的-理论上是可能的,但是给定一个项目不是一个序列,你不会得到lstm提供的任何好处。因此,最好使用前馈神经网络相反,在这种情况下。
- 多对一-使用一系列的值来预测下一个值。你可以在我的RNN的文章.
- 一对多-使用一个值来预测一个值序列。
- 多对多-使用一个值序列来预测下一个值序列。我们现在将构建一个多对多的LSTM。
设置
获取以下数据和库:
- 来自Kaggle的澳大利亚天气数据(许可证:知识共享,为数据的原始来源:澳大利亚联邦气象局).
- 熊猫和Numpy对数据操作
- 情节数据可视化
- Tensorflow / KerasLSTM神经网络
- Scikit-learn图书馆数据缩放(MinMaxScaler) - - -可选
让我们导入所有库:
上面的代码打印了我在这个例子中使用的包版本:
Tensorflow / Keras: 2.7.0
熊猫:1.3.4
numpy: 1.21.4
sklearn: 1.0.1
情节:5.4.0
其次,下载及摄取澳洲天气资料(资料来源:Kaggle).我们只摄取列的一个子集,因为我们的模型不需要整个数据集。
此外,我们执行一些简单的数据操作,并推导出两个新变量:年-月和中值温度。

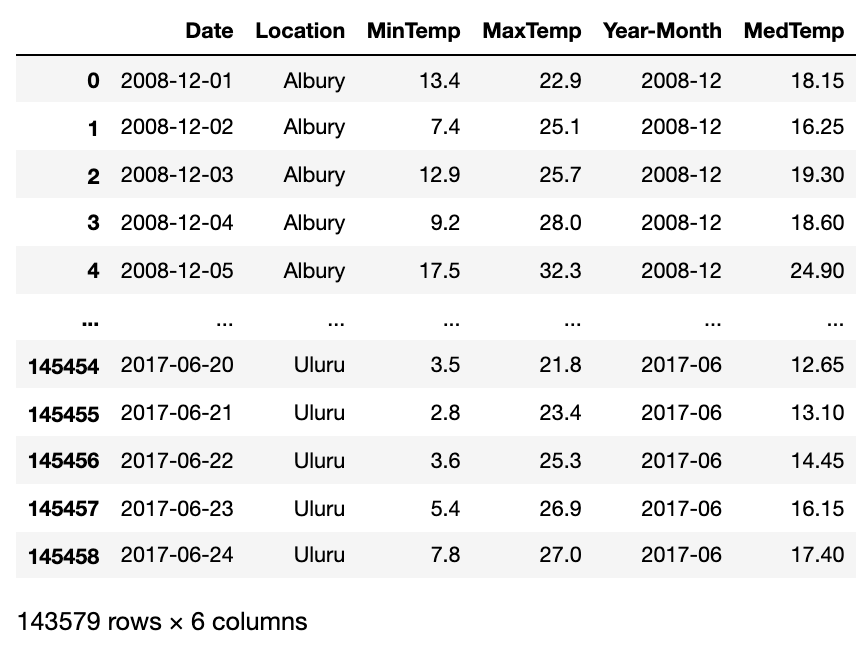
目前,每个地点和日期都有一个温度中值记录。然而,每天的气温波动很大,使得预测更加困难。因此,让我们计算每月平均值,并将数据转换为行和年-月列。

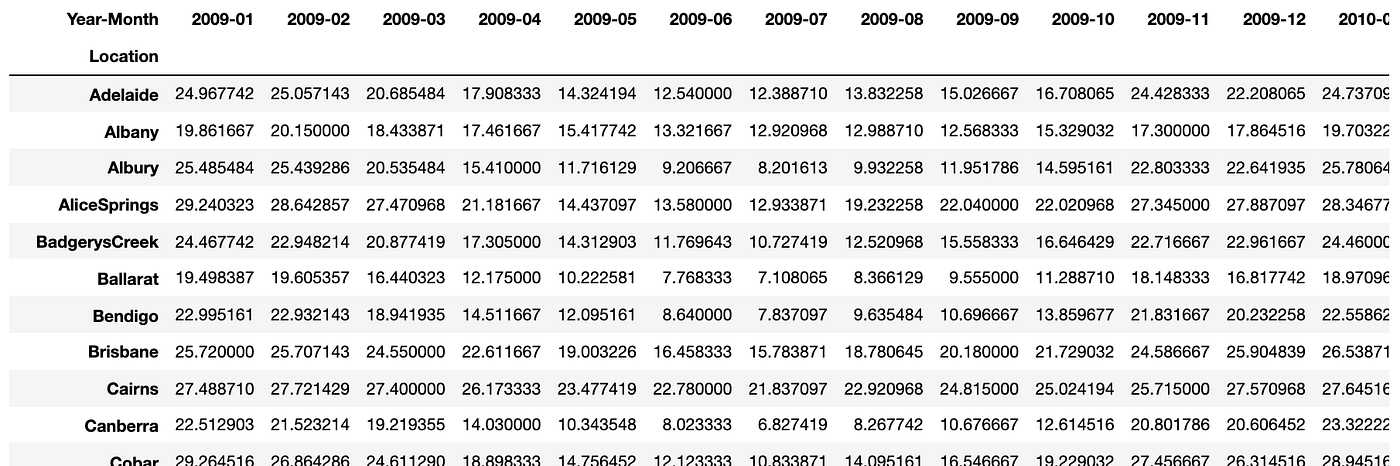
由于我们使用的是真实数据,我们注意到数据帧中完全缺失了三个月(2011-04,2012-12,2013-02)。因此,我们通过取前一个月和后一个月的平均值来估算缺失月份的值。
最后,我们可以在图表上绘制数据。


图中显示了最初的所有地点,但我选择了其中的四个(堪培拉、达尔文、黄金海岸和吉尼山)显示在上图中。
请注意平均温度及其变化在不同地点之间是如何变化的。我们可以训练一个特定地点的模型,以获得更好的精度,或者我们可以训练一个通用的模型,能够预测每个地区的温度。
在这个例子中,我将在单个地点(堪培拉)上训练我们的LSTM模型。如果您对通用模型感兴趣,请不要担心,我将在下一篇关于门控循环单位(GRU)的文章中解决这个问题。订阅千万不要错过!
LSTM模型的训练与评估
在我们开始之前,有几点需要强调。
- 我们将使用18个月的序列来预测未来18个月的平均气温。你可以根据自己的喜好进行调整,但要注意,对于超过23个月的序列,将没有足够的数据。
- 我们会把数据分成两个独立的数据帧,一个用于训练,另一个用于验证(没时间了验证)。
- 因为我们正在创建一个多对多预测模型,我们需要使用稍微复杂一点的encoder-decoder配置。编码器和解码器都是隐藏的LSTM层,信息通过一个重复向量层。
- 一个重复向量当我们想要有不同长度的序列时是必要的,例如,一个18个月的序列来预测未来12个月。它确保我们为译码器层提供正确的形状。但是,如果您的输入和输出序列的长度与我的示例中相同,那么您也可以选择设置return_sequences = True在编码器层并去掉重复向量。
- 注意,我们添加了一个双向包装到LSTM层。它允许我们在两个方向上训练模型,这有时会产生更好的结果。然而,它的用途是可选的。
- 同时,我们需要使用时间分布包装器在输出层中预测每个时间步的输出。
- 最后,请注意,我在本例中使用了未缩放的数据,因为它比使用缩放数据训练的模型(MinMaxScaler)产生了更好的结果。你可以在我的GitHub库中找到木星笔记本的缩放和非缩放版本(链接在文章末尾).
首先,让我们定义一个帮助函数,将数据重塑为lstm所需的3D数组。
接下来,我们训练LSTM神经网络超过1000个epoch,并显示一个具有评价指标的模型摘要。您可以按照代码中的注释来理解每一步。
上面的代码打印了我们的LSTM神经网络的以下总结和评估指标(注意,由于神经网络训练的随机性,你的结果可能会有所不同):


现在让我们将结果绘制在图表上,以比较实际值和预测值。

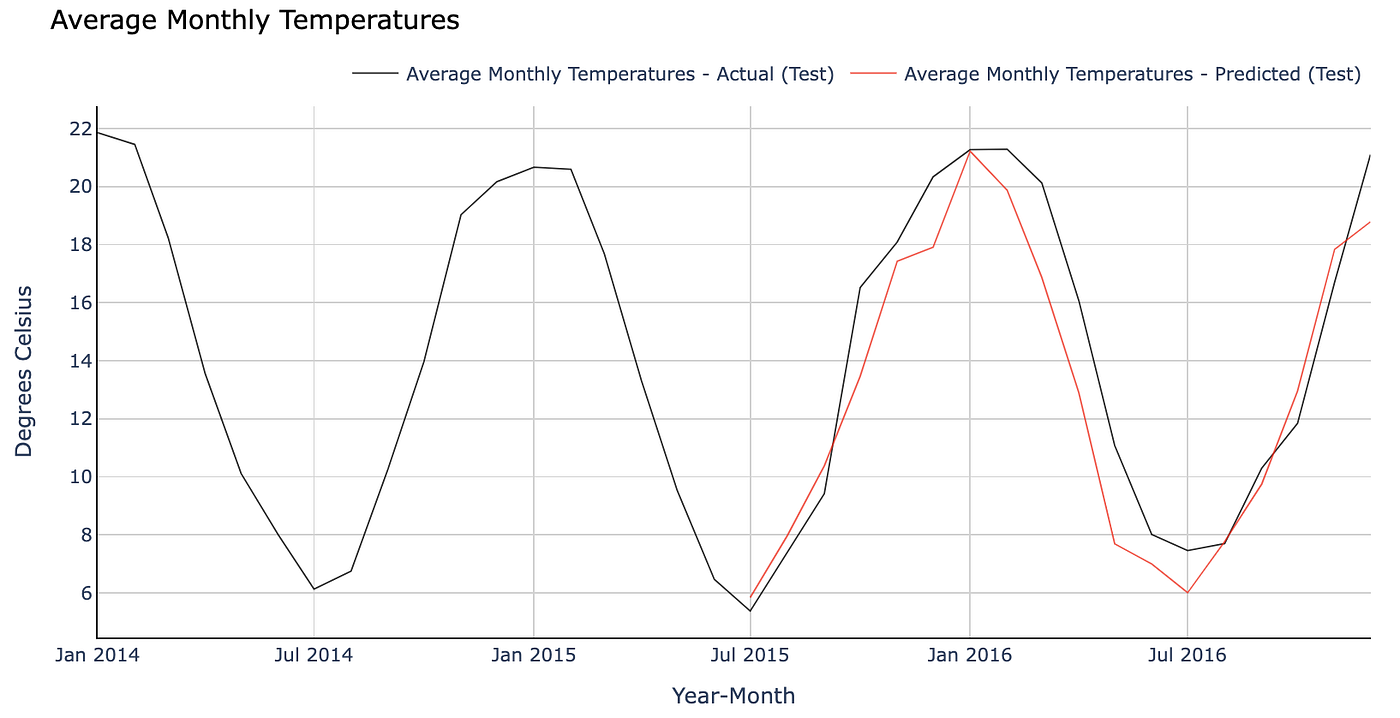
在预测堪培拉的月平均气温方面,我们似乎比较成功。看看你能否在不同的澳大利亚城市得到更好的结果!
最后的评论
我真诚地希望您喜欢阅读这篇文章,并获得一些新的知识。
你可以在我的网站上找到完整的木星笔记本代码GitHub库.您可以使用它来构建您自己的LSTM神经网络,如果您有任何问题或建议,请不要犹豫与我们联系。
干杯!
扫罗Dobilas
如果你已经花完这个月的学习预算,下次请记得我。我加入Medium的个人链接:
其他你可能会感兴趣的文章: