实践强化学习课程:第5部分
深q学习的

欢迎来到我的强化学习课程❤️
这是第5部分强化实践课程的学习,将你从零到英雄♂️。
第1部分:介绍强化学习
第2部分:表格q学习的
第3部分:表格撒尔沙
第4部分:线性q学习的
第5部分:深q学习的(今天)
在第4部分中,我们构建了一个购物车okay-ish代理极环境。我们与线性模型参数Q学习使用。
今天我们将取代这一线性模型神经网络。
我们将kick-ass-solve车杆环境
今天的课我年代的一段时间,因为它包含一个迷你速成课训练神经网络模型。除非你是一个专家在深度学习,我强烈建议你不要跳过它。
这节课的所有代码这Github回购。Git克隆它跟随今天的问题。
如果你喜欢,请给它一个⭐在Github !


需要很长的sip☕。我们已经准备好开始!
第5部分
内容
1。让我们深入!
在前面的课程中,我们使用这个线性参数化表示最佳q函数。

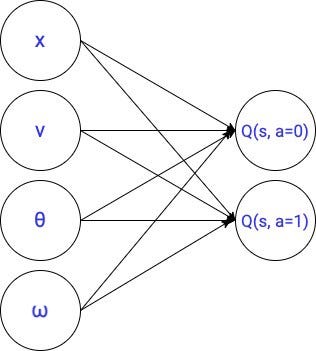
这是一个小模型只有10参数。
成功(或失败)的参数q学习代理强烈依赖于我们用来近似最优参数q值函数。
线性模型在概念上很简单,快速火车,和快速运行。然而,他们不是很灵活的。给定一组输入和输出的线性输入映射到输出层斗争。
这是当神经网络进入游戏。
神经网络模型是我们拥有的最强大的函数近似。他们非常灵活,可以用来揭示复杂的模式输入特性和目标之间的标签。
通用逼近定理是一个数学的结果,本质上说的
神经网络一样灵活的你想要的。如果你设计一个足够大的神经网络(即有足够的参数),你会发现一个accuracte输入特性和目标值之间的映射。
或者你更喜欢哲学联系…


今天我们要从第4部分取代线性模型的最简单的神经网络架构:a前馈神经网络。
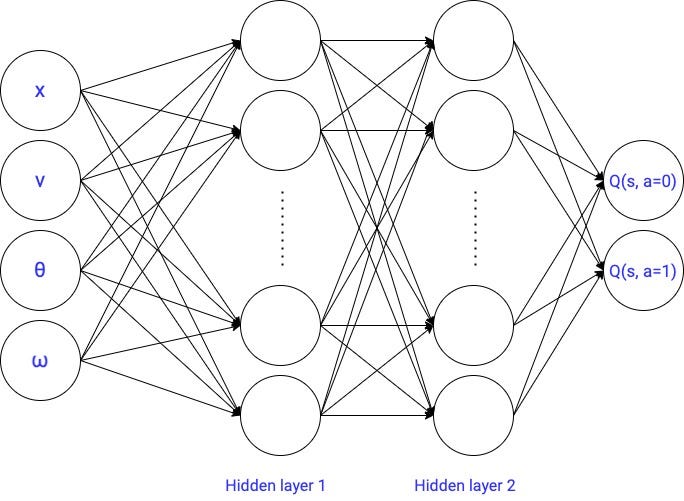
在晚些时候,我们将使用其他神经网络处理更加复杂州空间(如卷积神经网络)。
正如我说过的课程的一开始,我不希望你是一个神经网络专家。
如果你确实是一个,请跳过下一节,直接进入第三节。
否则,让我们热身深度学习掌握以下模仿学习问题我今天创建。
有很多,所以用深度关注武装自己。
2。实践介绍深度学习:学习最优政策从标记数据
笔记本/ 05 _crash_course_on_neural_nets.ipynb
在本节中,我们将使用深度学习解决监督机器学习问题。
但是,为什么我们不解决车杆?
监督的关键区别毫升问题,我们解决的优化参数q学习的,是在Supverside毫升的目标固定在参数q学习它们不是固定的,但移动。
正因为如此,监管毫升问题更容易解决,因此它们是一个更好的起点,让我们的手脏与神经网络模型。
在监督机器学习,你有一个数据集的对(输入、输出)你想找的正确的之间的映射的输入(即功能)和输出(即目标/标签)。
好吧,什么是监督毫升我们要解决的问题?
我把完美deep-q代理我们将在下一节火车(又名完美的剂)和生成一个样本的1000个国家(输入)和相应的采取的行动这个完美的代理(输出)。从这个示例的观察,我们想了解潜在的最优政策的代理。
认为它是一个模仿学习的问题。给你1000个样本(状态、动作)性能,从一个专家,你的工作是学习底层策略代理。
足够的说话。让我们来看看代码。我们第一次看到如何生成训练数据。然后我们将几种神经网络模型训练和提取一些知识。
2.1生成训练数据
像往常一样,我们首先加载环境


生成训练数据我们首先需要得到完美的代理参数(hyperparameters)。我上传这些公共访问Google Drive,并从那里你可以下载如下:


在path_to_agent_data你有两个文件:
模型→保存PyTorch模型参数的参数函数,在这种情况下,一个神经网络。hparams.json→hyper-parameters用于火车代理
现在,您可以实例化一个QAgent对象从这些参数(和hyper-parameters)如下:


前进一步,我想让你相信我当我说代理是完美的。让我们评估1000年随机集和检查的总回报。




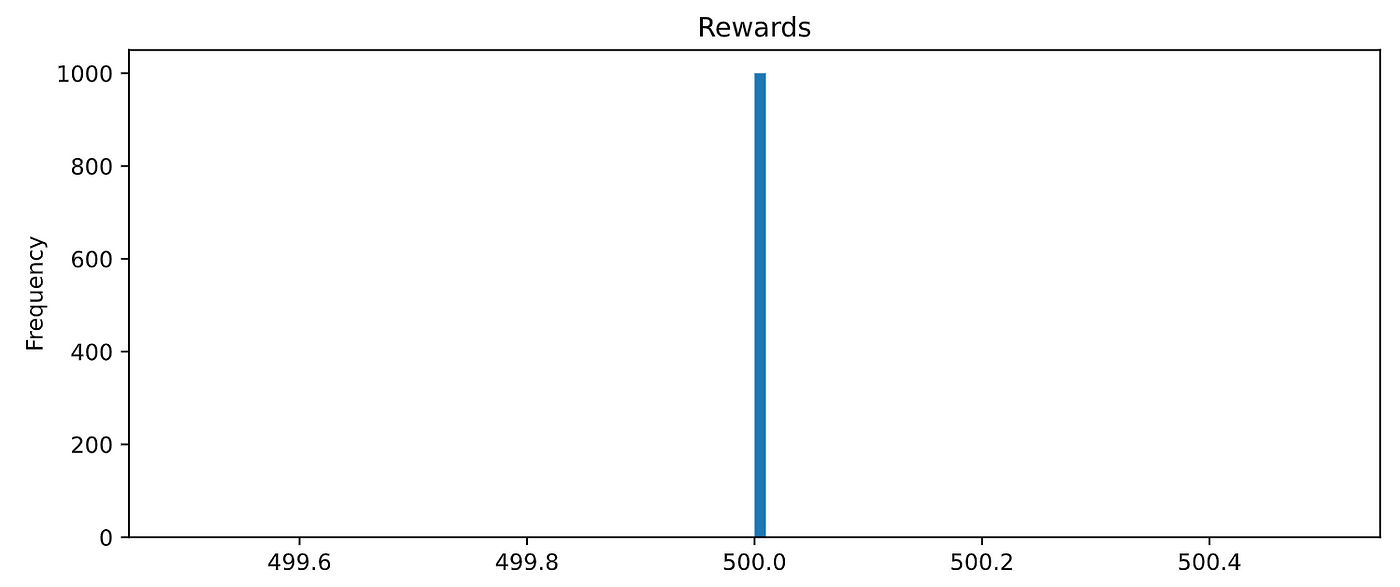
500是最大的总回报,我们代理了1000集。太棒了!你需要等到下一节自己训练这个完美的代理。
现在,我们让代理与环境交互的几集,直到我们收集了1000双(状态、动作)。这是我们如何生成训练数据。


的generate_state_action_data这样的函数生成一个CSV文件:

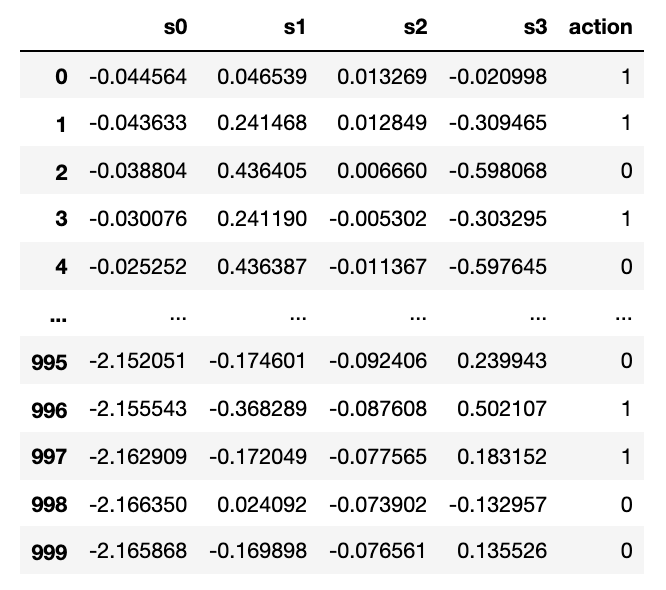
地点:
s1、s2、s3、s4输入功能,行动是目标,在这种情况下,一个二进制目标(0或1)。我们会解决吗二元分类问题。
现在,在我们进入建模部分之前,我们还需要做一件事。
当你训练监督毫升模型(特别是神经网络)和你想正确地评估他们的准确性,你不能你用来训练他们使用相同的数据集。
为什么?
因为它可能会发生你的模型仅仅记住了训练数据,而不是发现真正的特性和目标之间的相关性。这可以很容易地发生与highly-parametric模型,如神经网络。因此,当你使用新的和看不见的数据模型的模型,你的模型的性能将低于期间你有什么培训。
为了解决这个问题,我们生成另一个数据集,称为测试数据,我们不使用任何模型参数调整。测试数据仅用于评估模型的性能。
我们以同样的方式产生训练集。

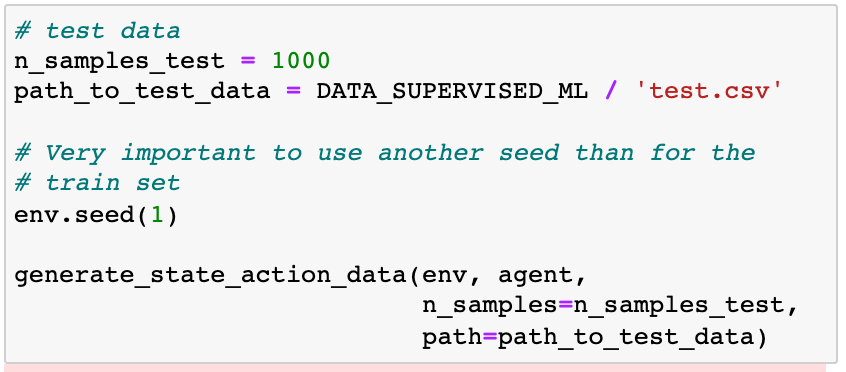
观察我们使用不同的种子train.csv,以保证我们不会产生相同的样本训练和测试数据集。
酷。我们得到数据。让我们转移到建模的部分。
2.2。造型
当我们总是在强化学习问题,最好是先建立一个快速的基准模型,为了了解问题是多么困难。
让我们加载CSV文件:


如果我们检查火车数据我们可以看到,目标值(即最优行动)有一个完全平衡的分布。

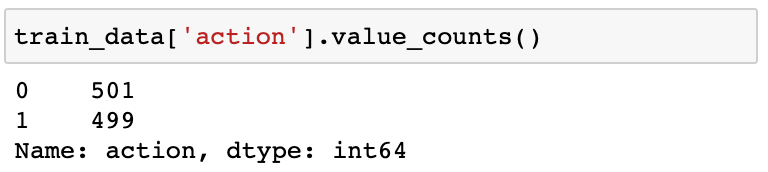
这意味着一个虚拟基线模型,预测总是行动= 0(或动作= 1)的准确性为50%,这意味着模型预测50%的时间匹配正确的标签。
加载数据到PyTorch模型
在我们进入模型之前,我们需要建立一个数据管道快速移动数据的批次熊猫数据帧我们PyTorch模型。
PyTorch API提供了2辅助对象允许您轻松地这样做:
torch.utils.data.Dataset→方便包装你熊猫的数据帧。它检索dataframe特性和一个样本的标签。torch.utils.data.DataLoader→你的重担,移动的数据数据集在批次Pytorch模型。它使用Python的多处理库来加快数据检索。
我们需要两个数据管道,一个用于训练数据和测试数据。


我们创建一个定制的数据集3类,并实现必不可少的方法:__init__ (),__len__ ()和__getitem__ (idx)。


然后,我们实例化2数据集对象:


的DataLoaders更容易实现,因为我们只需要声明它们,如下:


好!数据管道是准备好了。现在我们有一种快速批量移动数据,并将它们提供给我们将构建的模型。
所有的模型将被训练使用叉损失函数分类的,这是一个标准的选择问题。

我们将使用TensorBoard想象训练和测试指标(损失和准确性)。即使它是由谷歌开发的DL框架TensorFlow Tensorboard很整洁与PyTorch集成。
2.2.1线性模型→10参数
这是我们的第一个候选人学习最优政策。

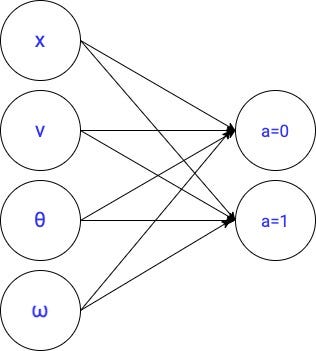
我们创建PyTorch模型如下:


我们训练该模型150时代。一个时代是一个完整的传递在整个训练数据。因此,我们将使用训练数据中的每个样本调整模型参数的150倍
在每个时代的结束,我们计算模型损失和使用测试数据的准确性。这样我们得到的多好该模型。


让我们点燃Tensorboard服务器可视化培训和测试指标。我们可以从Jupyter笔记本使用


请注意:你可以直接从命令行开始Tensorboard如果你喜欢,并导航到URL打印在控制台上,在我的例子中
localhost: 6009 /


打开Tensoboard并选择最新的运行。您应该看到这两个图表:
- 在火车上的数据准确性批后,批处理。高原70%左右。

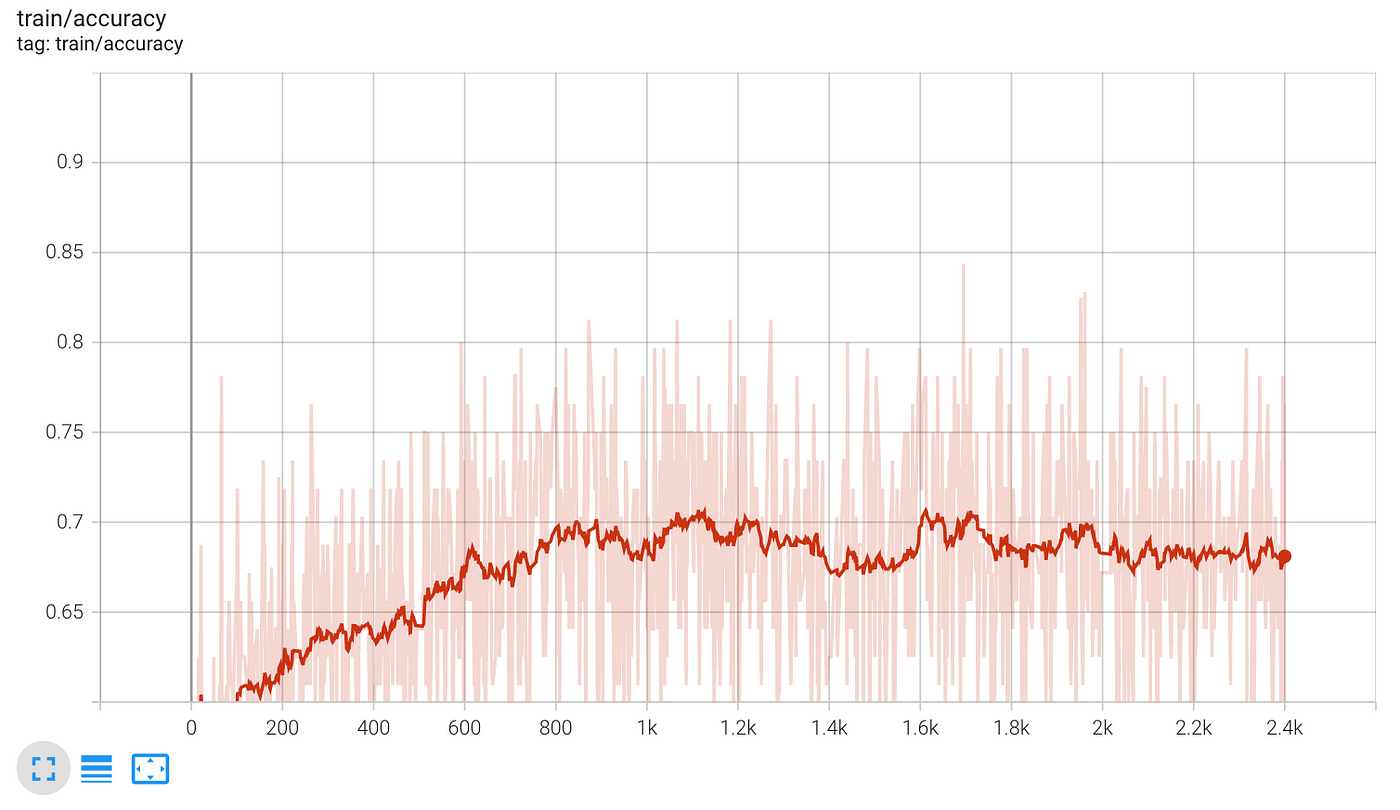
- 准确的测试数据批后,批处理。它还高原70%左右。这个数字大于50%的基准,因此,模型是学习的东西。


70%不是那么糟糕,但也远非完美。
提示:情节训练指标检测错误
火车总是阴谋准确性和损失,因为它可以帮助你找到代码中的bug。如果精度(损失)不增加(减少)在每一个时代,这意味着你的网络不是学习。这可能是由于一个错误代码,您需要修复。学习:Underfitting火车数据
如果模型是小的任务,我们观察训练和测试精度高原在温和的水平,在这种情况下70%。我们说这个模型underfits的数据,我们需要尝试一个更大的模型。
让我们扩大网络改善结果。
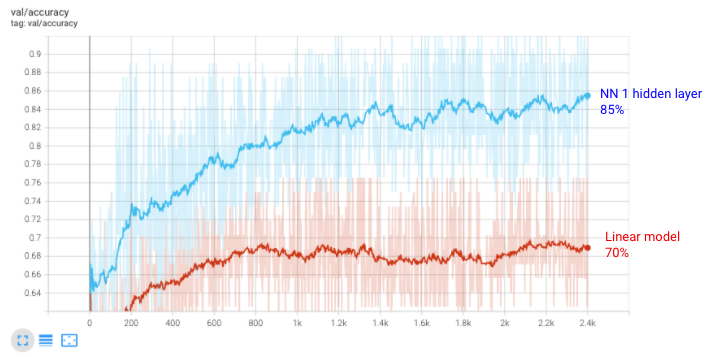
2.2.2与1神经网络隐层→1795参数
我们创建一个与一个隐层神经网络有256单位:



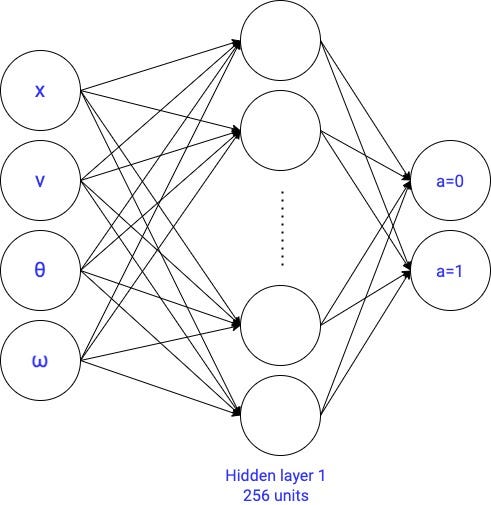
我们训练了150时代,然后去Tensorboard检查指标
- 准确的测试数据。我们从70%提高到85%左右。
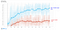
85%看起来好多了。但是,我认为我们可以做得更好。让我们尝试一个更大的神经网络。
2.2.3神经网络有两个隐藏层→67586参数



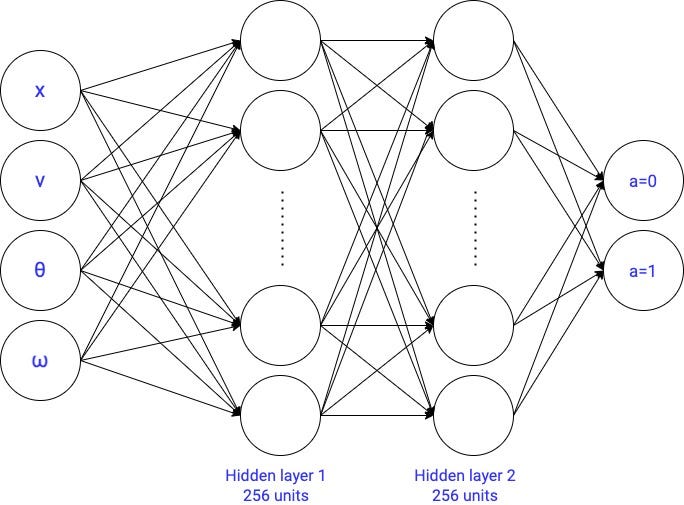
你会观察其测试的准确性打90%。

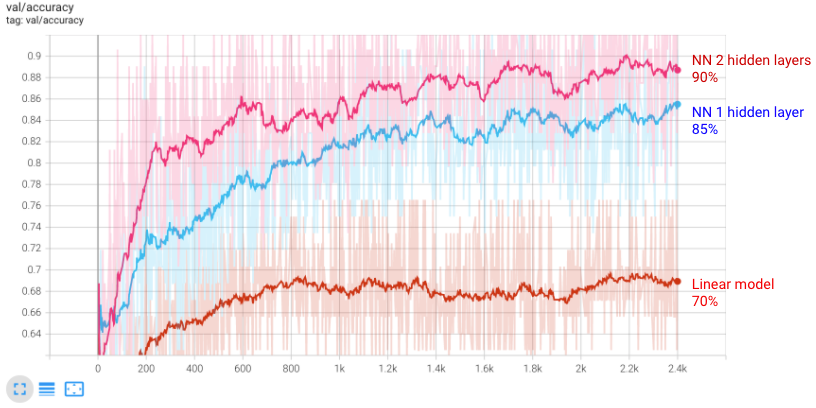
增加网络大小似乎是一个聪明的策略。让我们更进一步,加多一层。
2.2.4神经网络与3隐藏层→133378参数



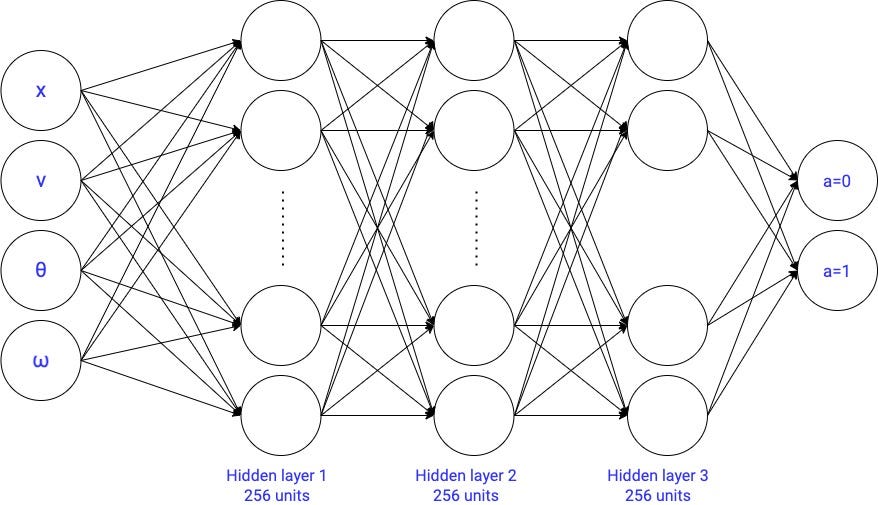
如果你去检查其准确性测试数据,您将看到它到达90%。因此,这个模型并不能提高我们的最好的结果。

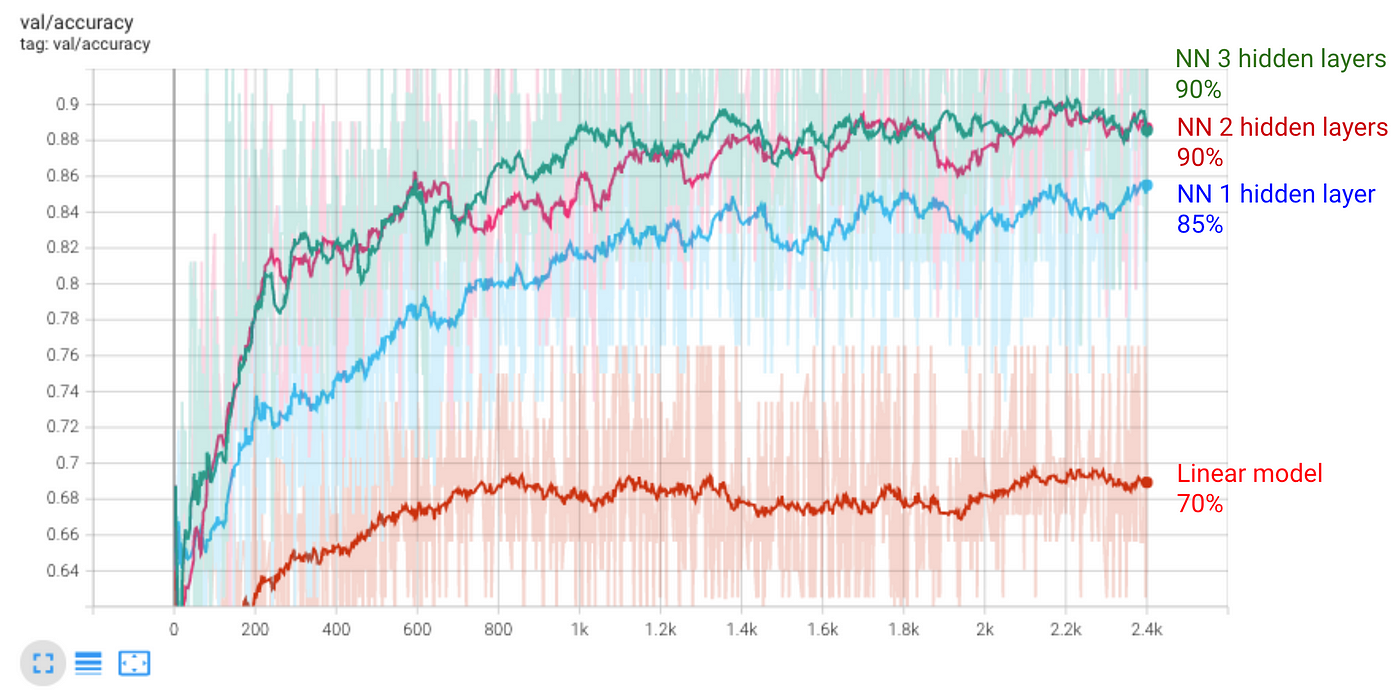
直观地说,看来我们之前的模型,用2隐藏层和大约67 k参数,做了充分的工作。使用更复杂的模型并不真正带来更好的结果。
学习:过度拟合训练数据
如果你的模型太大的训练数据量相比,你会的overfit训练数据。检测过度拟合看一看火车和测试的损失。
如果火车失去继续减少,而测试损失高原,这意味着你开始overfit
在这种情况下我们可以检查过度拟合通过观察训练和测试的损失:
- 在训练数据丢失几乎都为0。

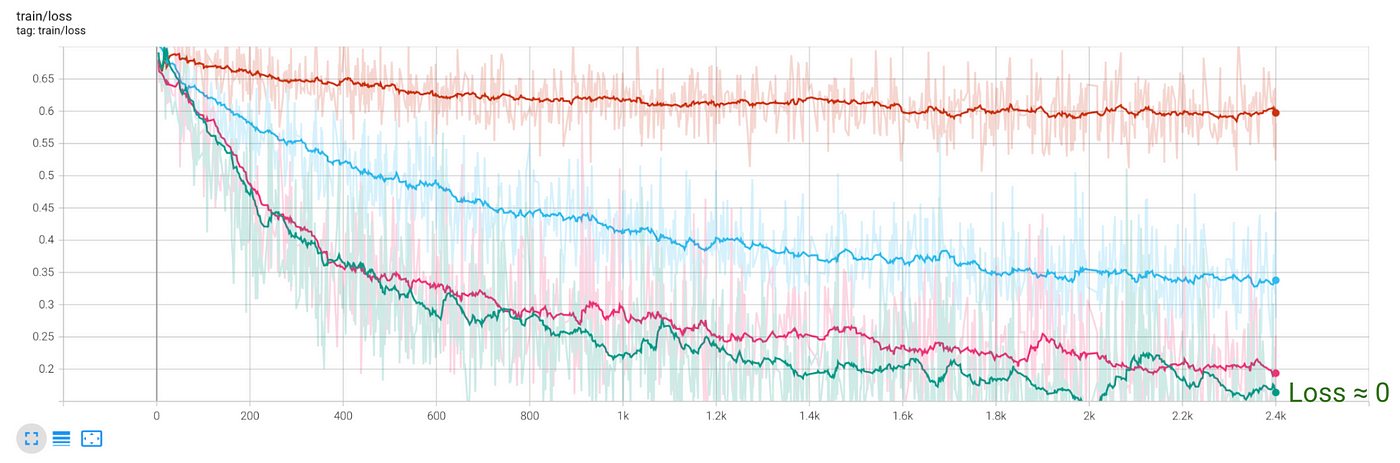
- 损失的测试数据高原为0.3,也就是和前面的模型2隐藏层。

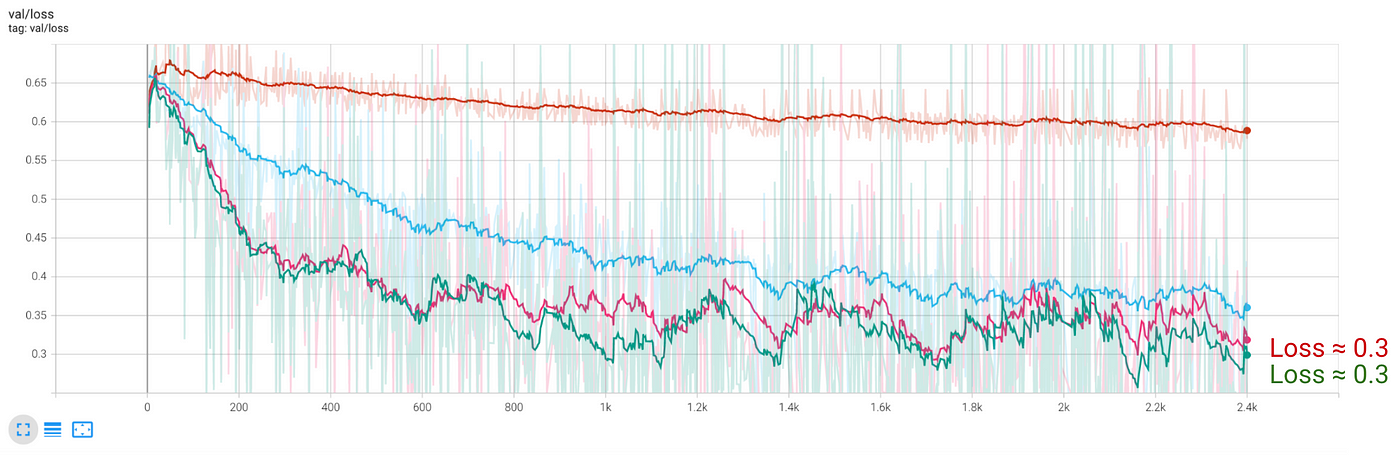
提示:收集更多的数据来改善结果
最有效的策略来提高神经网络模型是使用一套大火车。这些建议适用于任何机器学习模型,不仅神经网络。然而,神经网络是最受益于更大的训练集,因为它们是高度parameteric和灵活的适应最复杂模式的数据。
如你所见,有相当多的试验找到合适的神经网络架构问题。
你可能会问…
有一种系统的方法来找到合适的架构为我的数据?
是的,有。在本节中,我们从小型模型大型模型,以逐步增加了复杂性。然而,在实践中,你应该去。
提示:从大到小
一般来说,应该从一个足够大的网络,overfits训练数据。一旦你相信网络有足够的能力,你开始减少,减少过度拟合训练数据和增加对验证数据准确性。
Andrej Karpathy有一个非常好的博客,我强烈推荐你阅读吗
训练神经网络的秘诀
本节之后,我希望你有一个更好的理解如何训练神经网络模型。
我建议你经历中的代码src / supervised_ml.py巩固我们在这一节中。训练神经网络模型在监管环境是一个非常实用的用例深度学习在现实世界中。练习100 x乘以,如果你有问题,请让我知道。
在下一节中,我们回到购物车杆问题。
你准备好把RL和刚刚了解神经网络的吗?
3所示。深q学习解决车杆
回到参数q学习和购物车。
我们将完全从第4部分重用代码,唯一的区别,我们将取代最佳q函数的线性参数化

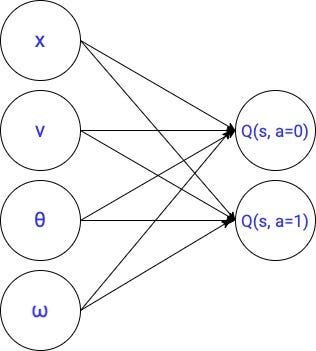
与神经网络2隐藏层
这将是第一个在很深的强化学习算法。在这种情况下,深Q-network。
hyperparameters呢?
RL hyper-parameters算法非常敏感。和深度q学习也不例外。
我不会对你说谎。找到合适的hyper-parameters可能非常耗时。Hyper-parameters是至关重要的深的强化学习,许多作者不公布。这是相当令人沮丧对于任何进入该领域。
甚至训练循环中的随机性,例如,洗牌的批火车内存中的数据,可以在最终的代理参数有很大的影响。
正因为如此,我们总是修复所有的种子在我们的Python脚本的开始


然而,这并不足以确保在机器再现性。它可以发生,你和我使用相同的hyper-parameters和随机种子,但我们得到不同的模型仅仅因为你培训一个GPU而我不是。
换句话说,完全可重复的结果不能保证在PyTorch版本,不同的平台,或硬件设置(GPU与CPU)。
再现性的结果
你可能不会得到同样的结果当使用相同的hyperparameters我分享在这一节中。不要沮丧。在下一课,我们将学习如何调整hyperparameters自己,,你将能够找到那些牛逼你的设置情况下这些不为你工作。
坏hyper-parameters
笔记本/ 06 _deep_q_agent_bad_hyperparameters.ipynb
这些hyperparameters不是最糟糕的,我发现,绝对。我打电话给他们坏因为他们给我们类似的结果线性q-model第4部分。
什么是使用一个复杂的神经网络模型的点当hyper-parameters严重吗?
这些是hyper-parameters:

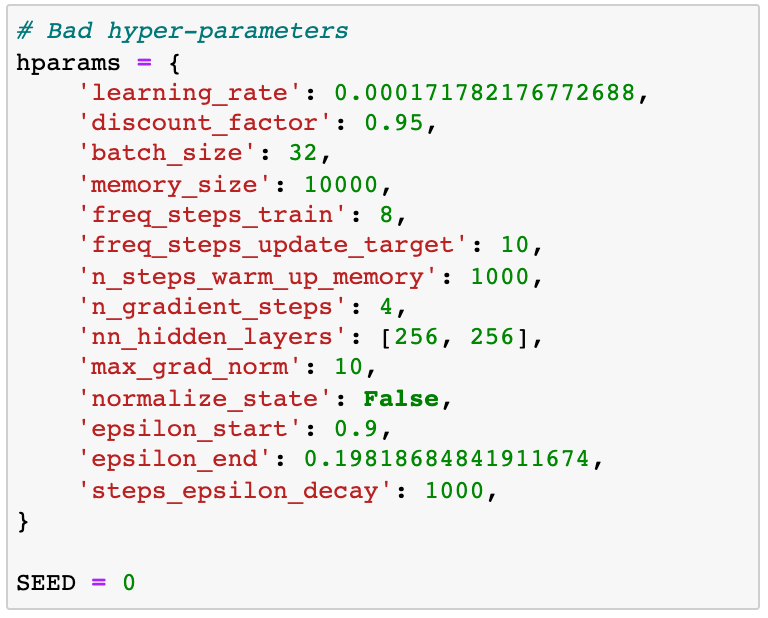
像往常一样,我们解决种子


我们声明QAgent从这些hyper-parameters


我们训练200集:


然后我们评估代理1000新话题
结果okish,但是我们可以做得更好。

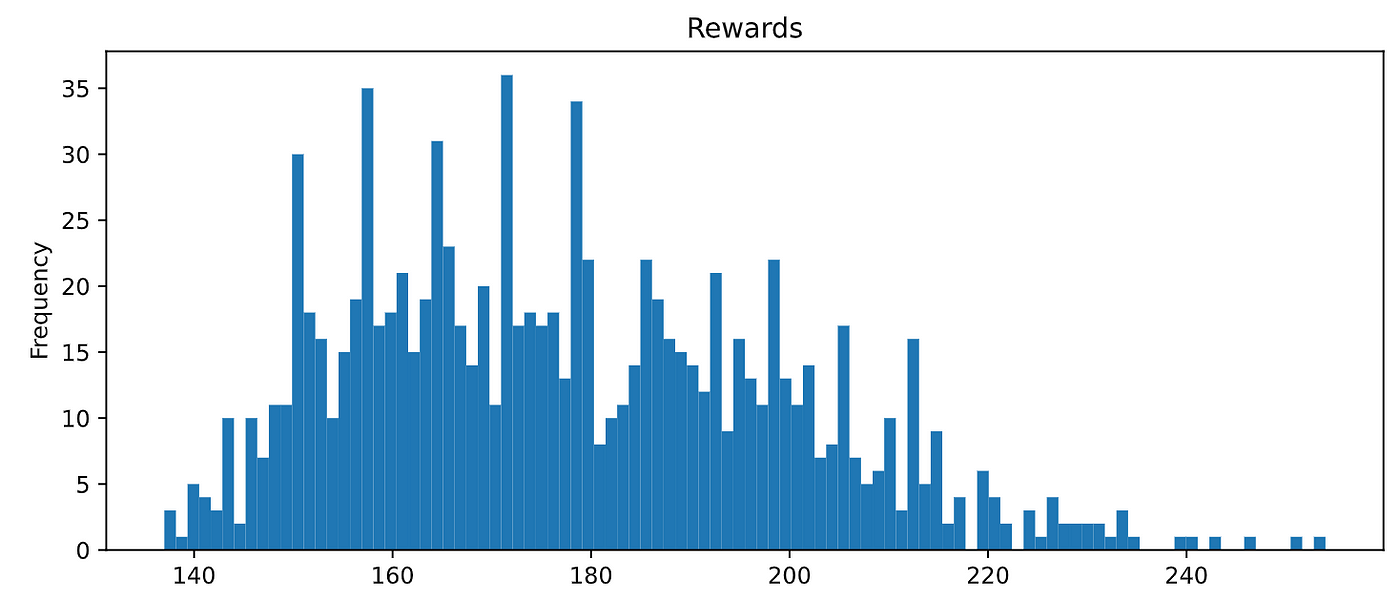
让我们做它!
好hyper-parameters
笔记本/ 07 _deep_q_agent_good_hyperparameters.ipynb
这些hyper-parameters效验如神在我的MacBook:


像往常一样,我们解决种子
我们声明QAgent从这些hyper-parameters
我们训练200集:
如果你评估代理1000年集
你会看到它到达100%时性能:

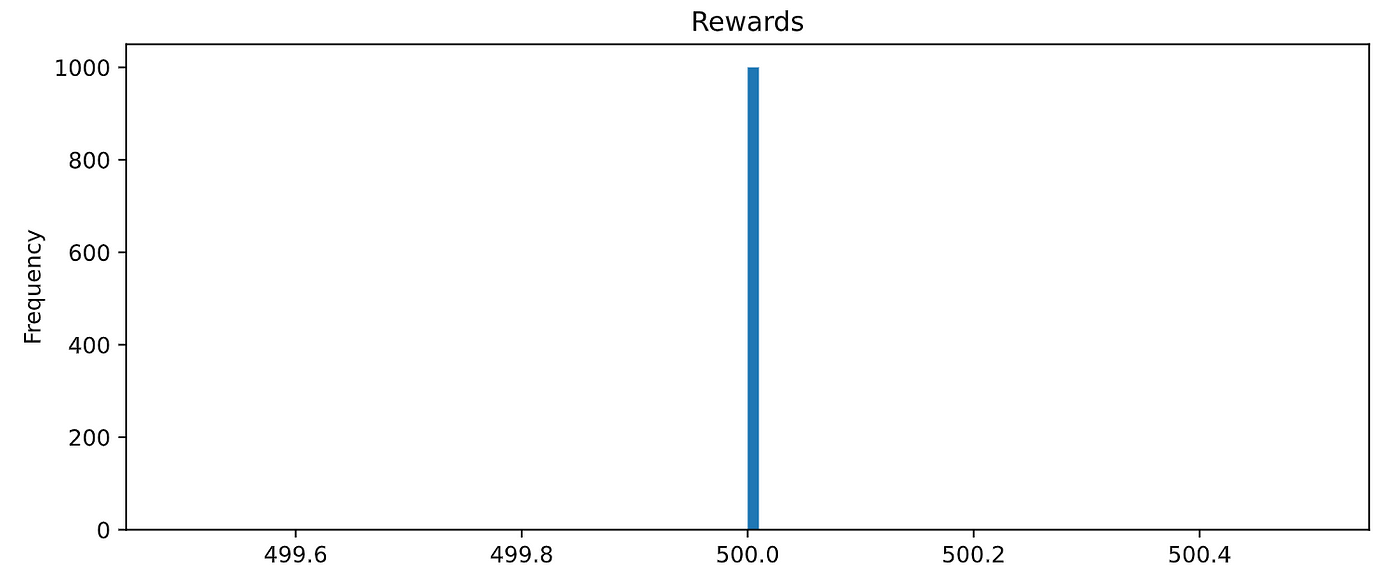
Wooowww ! !Amaaaziiiing ! ! !
这是很酷。我们发现完美的深q-agent CartPole环境!(如果你还没有在你的电脑,等我和第6部分将揭示背后的科学和工程hyper-parameter校准)。
这是今天的所有人。
渴望了解更多吗?


4所示。回顾✨
这些关键的知识我希望你从今天的教训:
- 神经网络是非常强大的功能接近者。您可以使用它们在充分监督环境(如学习最优政策从标记数据)或作为RL算法的一个组件(例如近似最优核反应能量函数)。
- 找到合适的神经网络结构不容易的。太大(小)的神经造成过度拟合(underfitting)。一般来说,从一个大型网络,overfits训练数据。然后你开始减少提高验证精度。
- Hyper-parameters深陷q学习是至关重要的,以确保培训循环收敛于最优解。此外,完整的再现性跨平台(例如Windows和Mac),底层硬件(GPU与CPU), PyTorch版本是非常难的,如果目前不可能。
5。家庭作业
让我们弄脏你的手:
- Git克隆回购到您的本地机器上。
- 设置这节课的环境
03 _cart_pole - 开放
03 _cart_pole /笔记本电脑/ 08 _homework.ipynb并尝试完成2挑战。
如果你不是一个深度学习的主人,我建议你解决第一个挑战。增加训练数据和尝试中至少95%的准确率模仿的问题。
在第二个挑战,我敢你找到一个简单的神经网络(如只有1隐层),可以完全解决CartPole问题。
6。接下来是什么?❤️
在下一课,我们将学习如何像专业人士那样调整hyper-parameters,使用正确的工具。
在那之前,
爱和学习。
,特别感谢Neria Uzan,如此致力于课程。谢谢你的努力工作和你反馈给我!